Frequent DNS timeouts
-
@gertjan said in Frequent DNS timeouts:
MAC directly connected by wire on the LAN port ?
Oh noooo. That's it. Thanks for the hint. I was looking into logs forever, but forget about that simple one.
-
Now you know it, look again at the main system log using the console access while your MAC system is shut down == LAN shut down also.
Switch on the MAC.
You'll see a NIC (LAN) uplink event in the system log (check also the hardware or dmesg log).
That triggers a whole lot activity on the system. Every system process using (listing) to the LAN interface will get restarted = DHCP server, NTP, the WebGUI to name a few, and also unbound. -
So far the only thing that has worked for me regarding the DNS hanging is to not use DNS over TLS to quad9 or Cloudflare or whatever upstream servers you have set. I did not see anyone else mention that so far (though it's likely I missed it). After going back to plain old DNS on port 53, all pages load much faster and I don't have missing icons and images. No more timeouts seen on the Status/DNS Resolver page either.
-
@phipac said in Frequent DNS timeouts:
not use DNS over TLS
I posted it above, referencing a different thread. It didn't seem to be any problem for me at home, but others (in one or more threads, have lost track) have said it definitely made a difference. One theory offered was that a high number of DNS requests could perhaps influence it.
-
S SteveITS referenced this topic on
-
@phipac I switched from quad9 to cloudflare about a week ago. There was a noticeable improvement in reliability but I still experience hangs. Much fewer and lasting shorter periods. I may try openDNS next.
The theory @SteveITS mentioned seems plausible. Equally plausible is maybe I have a configuration error. I note Apple devices seem very chatty although I haven’t had the opportunity to check other os’s to compare. The hangs I experience usually happen while using iPad/iPhone’s. I haven’t noticed it on a Mac but cannot say for sure.
-
Clouadflare, quad9, OpenDNS using TLS :
Read the first phrase here : Support TLS de Postfix where Postfix could actually be 'anything'.It's probably not 'thousands' but tens of thousands of lines, because back then, TLS wasn't even TLS 1.x, but the far more simple SSL. I'm not pointing the exisyte,nce of bug, as a decade or so later, most are ironed out. But the code complexity is huge. For those who doubt : have a look at what OpenSSL is. It's open source, and it's mind boggling.
edit : and keep in mind that all the TLS carefully constructed on your side has to be undone on the other side.
Running on hardware that handles millions identical tasks .... On these guys also just found out that their electricity bill just 3 folded. So, If I was to maintain these (free !!) services, I would start to 'throttle'. What would you do ? ;)And then there is this. If entropy is missing on a system, TLS goes bad.
My words : entropy is the possibility of the system to generate random numbers. Belief it or not, these are hard to generate. And when the stock goes low, the system ... does what, wait ?
TLS eats entropy for breakfast.All that said : I've been using 1.1.1.1 and the IPv6 counterpart for several weeks.
The only thing I noticed is that I noticed nothing. I forgot that I switched from DNSSEC Resolving to forwarding over TLS.
I'm not using a big system : a SG 4100 with 23.01. -
 G Gertjan referenced this topic on
G Gertjan referenced this topic on
-
G Gertjan referenced this topic on
-
@gertjan said in Frequent DNS timeouts:
I'm not using a big system : a SG 4100 with 23.01.
Me neither. SG-5100.
What is not clear to me in many posts is if pfBlocker is part of what folks are seeing. As many others said, I too had no problems with 22.xx and problems started after upgrading to 23.01 and new release of pfBlocker. The one change that comes to mind is using python mode for unbound.
I am now traveling and hope all the smoke settles over the next few weeks.
-
@jonh said in Frequent DNS timeouts:
that comes to mind is using python mode for unbound
That 'mode' doesn't restart unbound.
@thundergate said in Frequent DNS timeouts:
Also disabled python mode - and still all the unbound restarts.
Later on he discovered that unbound also restart when a LAN interface is take Up/Down.
So, unbound can get restarted for more then one reason.
I admit, my words, and what @thundergate wrote, are not a proof. With some luck, @BBcan177 can certify my words (but he probably won't even bother) as he can read that python script very well, as he wrote it.
pfBlockerng can restart unbound, as that is way to take in account new DNDBL info.
If it was possible to re download all the DNSBL feeds every five minutes, and (condition) one of these feeds had a changed content, then, yeah, unbound would get restarted every 5 minutes.
The golden rule always applies : the admin always rules, even if he doesn't know what he is doing ;)One of the reason why I refresh my DNSBL feeds ones a week. If a DNSBL feedactually changed, then unbound gets restarted. The cron task has been set at 3 AM sunday, so I never detect an unbound restart = a 3 seconds outage.
Also, don't see this post as a 'your are silly' and 'I am smart'. It's just me pushing you to discover what the real reason is.
The logs will tell you. -
@jonh Good information - thank you! I have not noticed a difference based on OS or manufacturer. I was seeing similar rates of hang on Windows, Linux, and Android.
Conducting a few more tests to see if I can narrow anything else down.
-
@gertjan Entropy. I hadn't considered that. I just noticed all of my ubuntu-based VMs flatlined to 256 entropy last fall. I think it lined up with the release of the 5.10 kernel but I can't be sure. It happens that I have pfsense running on proxmox, which also shows a flatline of 256 entropy. In pfsense, this is what I get from sysctl kern.random:
kern.random.fortuna.concurrent_read: 1
kern.random.fortuna.minpoolsize: 64
kern.random.rdrand.rdrand_independent_seed: 0
kern.random.use_chacha20_cipher: 1
kern.random.block_seeded_status: 0
kern.random.random_sources: 'Intel Secure Key RNG'
kern.random.harvest.mask_symbolic: PURE_VMGENID,PURE_RDRAND,[CALLOUT],[UMA],[FS_ATIME],SWI,[INTERRUPT],NET_NG,[NET_ETHER],NET_TUN,MOUSE,KEYBOARD,ATTACH,CACHED
kern.random.harvest.mask_bin: 01000000010000000101011111
kern.random.harvest.mask: 16843103
kern.random.initial_seeding.disable_bypass_warnings: 0
kern.random.initial_seeding.arc4random_bypassed_before_seeding: 0
kern.random.initial_seeding.read_random_bypassed_before_seeding: 0
kern.random.initial_seeding.bypass_before_seeding: 1 -
@gertjan said in Frequent DNS timeouts:
@jonh said in Frequent DNS timeouts:
that comes to mind is using python mode for unbound
That 'mode' doesn't restart unbound.
And I don’t believe I said anything about that mode restarting unbound..
- my unbound stops responding ever so often for 2-4 minutes. I have not seen anything in my logs about restarting during these occurances. Early on I did restart it manually, that does show in the logs. Now I just wait it out.
-
@jonh same, but everyone keeps just repeating that it must be dhcp registrations ...
-
@nedyah700 said in Frequent DNS timeouts:
@jonh same, but everyone keeps just repeating that it must be dhcp registrations ...
Right, and everyone with the problem, myself included, keeps repeating why did it not happen prior to upgrade to 23.01 and new release of pfBlocker?
Sure, maybe there is less forgiveness in 23.01. I will say that I’ve been convinced dns/tls may not be worth all this hassle and when I return home I’ll be thinking about dropping that from my system.
-
@jonh yep 100% with you. I'm not even using then DNSBL module of pfBlocker, just the IP module. Nothing changed except the upgrade and now, seemingly randomly, all my devices stop resolving DNS for a minute or so.
-
@nedyah700 said in Frequent DNS timeouts:
@jonh same, but everyone keeps just repeating that it must be dhcp registrations ...
If this :

is checked, then yes, that's true.
Look at the DHCP log, see the DHCP events, and the System log at the same time, where you can find dhcpleases process entries like :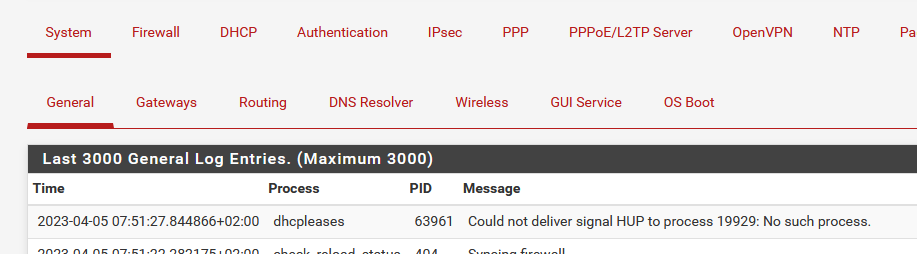
This line indicates that the dhcpdleases process wanted to restart unbound, but it was already doing a restart (!). The pid wasn't valid anymore (for a short moment)
At that moment, another DHCP event came in, the unbound pid was already gone, unbound was restarted again. Etc.I've activated :

just for a minute or two and unbound restarted already 3 times.
So, back to :

The "DHCP Registration" is one reason for unbound to restart (very) often.
Interface events, like DOWN/UP, on WAN, LAN or any other network interface also restart unbound.
Other events, fired by packages I don't use, can also do this.
Saving unbound settings also restarts unbound, twice actually, once to validate the settings, and once to take the (new) settings in account.This package :

coupled with "DHCP Registration" setting activated can create a real mess ... like some sort of chain restart reaction.
On my two pfSense systems, with these :
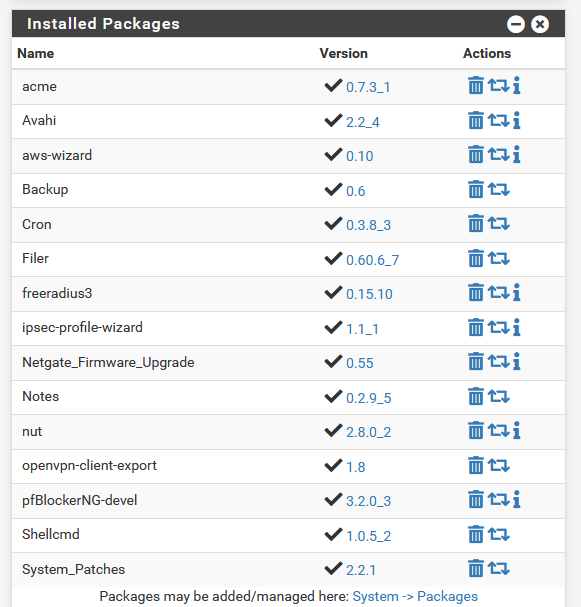
my unbound stays up running. pfBlockerng, as said above, can restart unbound ones in a week or so, during feed updates, if any.
Btw : I've installed "System_Patches" and activated nearly all patches, although none are, afaik, related to unbound restarts.
-
@nedyah700 I wonder if this is more of system wide issue. I have completely disabled DNS Resolver and Forwarder, only to find out resolution to 1.1.1.1, 1.0.0.1, or even Googles DNS (8.8.8.8, 8.8.8.1) , clients still timeout.
Heck, I had special DHCP static leases for specific devices that handed out those DNS servers instead of the firewall, and they still had DNS timeouts. This causes video streaming issues with apps like Hulu, or even connected to this website (I see the "Looks like your connection to Netgate Forum was lost...").
Now, I have had this issue for well over several years, only for it to worsen with the 23.01 update.
-
@chrislynch said in Frequent DNS timeouts:
I had special DHCP static leases for specific devices that handed out those DNS servers instead of the firewall, and they still had DNS timeouts.
These devices 'talk' directly to "1.1.1.1, 1.0.0.1, or even Googles DNS (8.8.8.8, 8.8.8.1)" which means it's some TCP and mostly UDP traffic to these IPs using port destination 53.
pfSense does nothing with this traffic except 'routing it'.IMHO : That's for sure an uplink issue.