Fatal trap 12: page fault while in kernel mode when connecting PPPoE
-
IPv6 addresses on re0 have been removed before adding it as a member to prevent IPv6 address scope violation.Thats strange. IPv6 is not enabled on the interface at all, is it ok?
And what about this firewall that does not save dumps? This one have default ZFS installation with swap 1G I've just selected ZFS mirror disks. Storage have enough space for everything. What else?
-
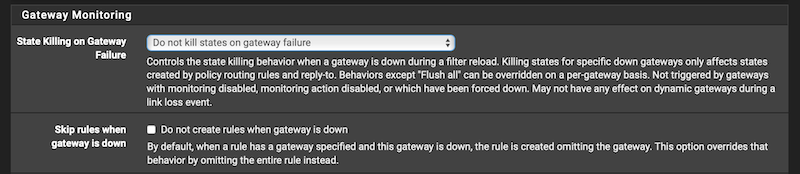
Looks like the "Do not create rules when gateway is down" option and using LAGG+VLANS on non-matching interfaces currently solved those traps.
Will see. -
@w0w said in Fatal trap 12: page fault while in kernel mode when connecting PPPoE:
Looks like the "Do not create rules when gateway is down" option
Where is that option?
 ️
️ -
@RobbieTT
System/Advanced/Miscellaneous -
-
Fatal trap 12: page fault while in kernel mode cpuid = 5; apic id = 05 fault virtual address = 0x50 fault code = supervisor read data, page not present instruction pointer = 0x20:0xffffffff80fb8037 stack pointer = 0x28:0xfffffe001b1ec930 frame pointer = 0x28:0xfffffe001b1ec9f0 code segment = base 0x0, limit 0xfffff, type 0x1b = DPL 0, pres 1, long 1, def32 0, gran 1 processor eflags = interrupt enabled, resume, IOPL = 0 current process = 12 (swi1: netisr 7) rdi: fffff8030039446e rsi: fffffe00c481e82d rdx: 0000000000000000 rcx: fffffe00c481e370 r8: fffffe001b1eca50 r9: 0000000000000000 rax: 0000000000000000 rbx: fffff803fcd6f970 rbp: fffffe001b1ec9f0 r10: 0000000000000000 r11: fffffe00c481e370 r12: fffffe00c481e370 r13: 0000000000000002 r14: fffff8035defd000 r15: fffffe001b1ecc78 trap number = 12 panic: page fault cpuid = 5 time = 1694631331 KDB: enter: panicNo. :) It was primary in carp maintenance mode and secondary was master and just rebooted — that caused the primary to crash.
-
@stephenw10,
I apologize for disturbing you, maybe you have an idea in which direction to dig? If you need any other tests or information, I will be happy to perform them and provide the data. Unfortunately, my knowledge is too little to analyze the dumps on my own.
-
Secondary firewall crashed, when master firewall was rebooted manually in GUI
db:1:pfs> bt Tracing pid 0 tid 100009 td 0xfffffe00205eec80 kdb_enter() at kdb_enter+0x32/frame 0xfffffe00c676e390 vpanic() at vpanic+0x163/frame 0xfffffe00c676e4c0 panic() at panic+0x43/frame 0xfffffe00c676e520 trap_fatal() at trap_fatal+0x40c/frame 0xfffffe00c676e580 trap_pfault() at trap_pfault+0x4f/frame 0xfffffe00c676e5e0 calltrap() at calltrap+0x8/frame 0xfffffe00c676e5e0 --- trap 0xc, rip = 0xffffffff80fb86d7, rsp = 0xfffffe00c676e6b0, rbp = 0xfffffe00c676e770 --- pf_route() at pf_route+0x4e7/frame 0xfffffe00c676e770 pf_test() at pf_test+0xd7b/frame 0xfffffe00c676e910 pf_check_out() at pf_check_out+0x22/frame 0xfffffe00c676e930 pfil_mbuf_out() at pfil_mbuf_out+0x38/frame 0xfffffe00c676e960 ip_output() at ip_output+0xb4a/frame 0xfffffe00c676ea60 ip_forward() at ip_forward+0x3c2/frame 0xfffffe00c676eb10 ip_input() at ip_input+0x6e9/frame 0xfffffe00c676eb70 netisr_dispatch_src() at netisr_dispatch_src+0x22c/frame 0xfffffe00c676ebc0 ether_demux() at ether_demux+0x149/frame 0xfffffe00c676ebf0 ether_nh_input() at ether_nh_input+0x36e/frame 0xfffffe00c676ec50 netisr_dispatch_src() at netisr_dispatch_src+0xaf/frame 0xfffffe00c676eca0 ether_input() at ether_input+0x69/frame 0xfffffe00c676ed00 iflib_rxeof() at iflib_rxeof+0xc46/frame 0xfffffe00c676ee00 _task_fn_rx() at _task_fn_rx+0x72/frame 0xfffffe00c676ee40 gtaskqueue_run_locked() at gtaskqueue_run_locked+0x14e/frame 0xfffffe00c676eec0 gtaskqueue_thread_loop() at gtaskqueue_thread_loop+0xc2/frame 0xfffffe00c676eef0 fork_exit() at fork_exit+0x7f/frame 0xfffffe00c676ef30 fork_trampoline() at fork_trampoline+0xe/frame 0xfffffe00c676ef30 --- trap 0x7cfdf9fb, rip = 0x16592cb25965b2cb, rsp = 0x29d353a6a74c4e99, rbp = 0xde82bd057a0af415 --- db:1:pfs> show registers cs 0x20 ds 0x3b es 0x3b fs 0x13 gs 0x1b ss 0x28 rax 0x12 rcx 0xffffffff81457767 rdx 0xfffffe00c676dfd0 rbx 0x100 rsp 0xfffffe00c676e390 rbp 0xfffffe00c676e390 rsi 0x2d rdi 0xffffffff82d40298 vt_conswindow+0x10 r8 0 r9 0 r10 0 r11 0 r12 0 r13 0 r14 0xffffffff813db3a1 r15 0xfffffe00205eec80 rip 0xffffffff80d38812 kdb_enter+0x32 rflags 0x82 kdb_enter+0x32: movq $0,0x2344ff3(%rip) db:1:pfs> show pcpu cpuid = 2 dynamic pcpu = 0xfffffe009d56af00 curthread = 0xfffffe00205eec80: pid 0 tid 100009 critnest 1 "if_io_tqg_2" curpcb = 0xfffffe00205ef1a0 fpcurthread = none idlethread = 0xfffffe0020566560: tid 100005 "idle: cpu2" self = 0xffffffff84212000 curpmap = 0xffffffff83021ab0 tssp = 0xffffffff84212384 rsp0 = 0xfffffe00c676f000 kcr3 = 0x73a39000 ucr3 = 0xffffffffffffffff scr3 = 0x17042a000 gs32p = 0xffffffff84212404 ldt = 0xffffffff84212444 tss = 0xffffffff84212434 curvnet = 0xfffff80001241400 db:1:pfs> run lockinfo db:2:lockinfo> show locks No such command; use "help" to list available commands db:2:lockinfo> show alllocks No such command; use "help" to list available commands db:2:lockinfo> show lockedvnods Locked vnodes db:1:pfs> acttrace -
@w0w said in Fatal trap 12: page fault while in kernel mode when connecting PPPoE:
@stephenw10,
I apologize for disturbing you, maybe you have an idea in which direction to dig? If you need any other tests or information, I will be happy to perform them and provide the data. Unfortunately, my knowledge is too little to analyze the dumps on my own.I can't speak for Steve but the Netgate team has made a significant discovery in issues related to IPv6. There is a chance that the changes needed could make it to the 23.09 release.
️ -
@RobbieTT
Do you mean something https://redmine.pfsense.org/issues/14077 like that?
I see no IPv6 traces in this trap. -
Primary firewall leaving "Carp Maintenance mode"
db:1:pfs> bt Tracing pid 12 tid 100063 td 0xfffffe00c498ae40 kdb_enter() at kdb_enter+0x32/frame 0xfffffe001b1f1610 vpanic() at vpanic+0x163/frame 0xfffffe001b1f1740 panic() at panic+0x43/frame 0xfffffe001b1f17a0 trap_fatal() at trap_fatal+0x40c/frame 0xfffffe001b1f1800 trap_pfault() at trap_pfault+0x4f/frame 0xfffffe001b1f1860 calltrap() at calltrap+0x8/frame 0xfffffe001b1f1860 --- trap 0xc, rip = 0xffffffff80fb86d7, rsp = 0xfffffe001b1f1930, rbp = 0xfffffe001b1f19f0 --- pf_route() at pf_route+0x4e7/frame 0xfffffe001b1f19f0 pf_test() at pf_test+0xd7b/frame 0xfffffe001b1f1b90 pf_check_out() at pf_check_out+0x22/frame 0xfffffe001b1f1bb0 pfil_mbuf_out() at pfil_mbuf_out+0x38/frame 0xfffffe001b1f1be0 ip_output() at ip_output+0xb4a/frame 0xfffffe001b1f1ce0 ip_forward() at ip_forward+0x3c2/frame 0xfffffe001b1f1d90 ip_input() at ip_input+0x6e9/frame 0xfffffe001b1f1df0 swi_net() at swi_net+0x128/frame 0xfffffe001b1f1e60 ithread_loop() at ithread_loop+0x257/frame 0xfffffe001b1f1ef0 fork_exit() at fork_exit+0x7f/frame 0xfffffe001b1f1f30 fork_trampoline() at fork_trampoline+0xe/frame 0xfffffe001b1f1f30 --- trap 0xaf34f5ea, rip = 0x56a9887e31914e4f, rsp = 0x4506b2da7d808177, rbp = 0xf56feca9dc25ff3d --- db:1:pfs> show registers cs 0x20 ds 0x3b es 0x3b fs 0x13 gs 0x1b ss 0x28 rax 0x12 rcx 0xffffffff81457767 rdx 0xfffffe001b1f1250 rbx 0x100 rsp 0xfffffe001b1f1610 rbp 0xfffffe001b1f1610 rsi 0x30 rdi 0xffffffff82d40298 vt_conswindow+0x10 r8 0 r9 0 r10 0 r11 0 r12 0 r13 0 r14 0xffffffff813db3a1 r15 0xfffffe00c498ae40 rip 0xffffffff80d38812 kdb_enter+0x32 rflags 0x86 kdb_enter+0x32: movq $0,0x2344ff3(%rip) db:1:pfs> show pcpu cpuid = 3 dynamic pcpu = 0xfffffe009afa7f00 curthread = 0xfffffe00c498ae40: pid 12 tid 100063 critnest 1 "swi1: netisr 6" curpcb = 0xfffffe00c498b360 fpcurthread = none idlethread = 0xfffffe00c48d5e40: tid 100006 "idle: cpu3" self = 0xffffffff84013000 curpmap = 0xffffffff83021ab0 tssp = 0xffffffff84013384 rsp0 = 0xfffffe001b1f2000 kcr3 = 0x80000000c5d31001 ucr3 = 0xffffffffffffffff scr3 = 0x316df2c9a gs32p = 0xffffffff84013404 ldt = 0xffffffff84013444 tss = 0xffffffff84013434 curvnet = 0xfffff800012791c0 db:1:pfs> run lockinfo db:2:lockinfo> show locks No such command; use "help" to list available commands db:2:lockinfo> show alllocks No such command; use "help" to list available commands db:2:lockinfo> show lockedvnods Locked vnodes -
Primary crashes when it is in CARP maintenance mode and I manually reboot the secondary firewall, which is currently “MASTER”
db:1:pfs> bt Tracing pid 12 tid 100062 td 0xfffffe00c498b560 kdb_enter() at kdb_enter+0x32/frame 0xfffffe001b1f6610 vpanic() at vpanic+0x163/frame 0xfffffe001b1f6740 panic() at panic+0x43/frame 0xfffffe001b1f67a0 trap_fatal() at trap_fatal+0x40c/frame 0xfffffe001b1f6800 trap_pfault() at trap_pfault+0x4f/frame 0xfffffe001b1f6860 calltrap() at calltrap+0x8/frame 0xfffffe001b1f6860 --- trap 0xc, rip = 0xffffffff80fb86d7, rsp = 0xfffffe001b1f6930, rbp = 0xfffffe001b1f69f0 --- pf_route() at pf_route+0x4e7/frame 0xfffffe001b1f69f0 pf_test() at pf_test+0xd7b/frame 0xfffffe001b1f6b90 pf_check_out() at pf_check_out+0x22/frame 0xfffffe001b1f6bb0 pfil_mbuf_out() at pfil_mbuf_out+0x38/frame 0xfffffe001b1f6be0 ip_output() at ip_output+0xb4a/frame 0xfffffe001b1f6ce0 ip_forward() at ip_forward+0x3c2/frame 0xfffffe001b1f6d90 ip_input() at ip_input+0x6e9/frame 0xfffffe001b1f6df0 swi_net() at swi_net+0x128/frame 0xfffffe001b1f6e60 ithread_loop() at ithread_loop+0x257/frame 0xfffffe001b1f6ef0 fork_exit() at fork_exit+0x7f/frame 0xfffffe001b1f6f30 fork_trampoline() at fork_trampoline+0xe/frame 0xfffffe001b1f6f30 --- trap 0x24f03cbe, rip = 0x3e5ce0ab5d44269a, rsp = 0x9a1bada3ca8f0cb6, rbp = 0x2a37be9697d8c544 --- db:1:pfs> show registers cs 0x20 ds 0x3b es 0x3b fs 0x13 gs 0x1b ss 0x28 rax 0x12 rcx 0xffffffff81457767 rdx 0xfffffe001b1f6250 rbx 0x100 rsp 0xfffffe001b1f6610 rbp 0xfffffe001b1f6610 rsi 0x30 rdi 0xffffffff82d40298 vt_conswindow+0x10 r8 0 r9 0 r10 0 r11 0 r12 0 r13 0 r14 0xffffffff813db3a1 r15 0xfffffe00c498b560 rip 0xffffffff80d38812 kdb_enter+0x32 rflags 0x86 kdb_enter+0x32: movq $0,0x2344ff3(%rip) db:1:pfs> show pcpu cpuid = 5 dynamic pcpu = 0xfffffe009afc5f00 curthread = 0xfffffe00c498b560: pid 12 tid 100062 critnest 1 "swi1: netisr 5" curpcb = 0xfffffe00c498ba80 fpcurthread = none idlethread = 0xfffffe00c48d5000: tid 100008 "idle: cpu5" self = 0xffffffff84015000 curpmap = 0xffffffff83021ab0 tssp = 0xffffffff84015384 rsp0 = 0xfffffe001b1f7000 kcr3 = 0x80000000c5d25002 ucr3 = 0xffffffffffffffff scr3 = 0x262086cbb gs32p = 0xffffffff84015404 ldt = 0xffffffff84015444 tss = 0xffffffff84015434 curvnet = 0xfffff80001279200 db:1:pfs> run lockinfo db:2:lockinfo> show locks No such command; use "help" to list available commands db:2:lockinfo> show alllocks No such command; use "help" to list available commands db:2:lockinfo> show lockedvnods Locked vnodes -
Hi, could you add the line
net.isr.maxthreads=1to/boot/loader.confon both primary and secondary, and try replicating the crash? -
Crash on primary, leaving CARP maintenance mode.
db:1:pfs> bt Tracing pid 12 tid 100063 td 0xfffffe00c498ae40 kdb_enter() at kdb_enter+0x32/frame 0xfffffe001b1f1610 vpanic() at vpanic+0x163/frame 0xfffffe001b1f1740 panic() at panic+0x43/frame 0xfffffe001b1f17a0 trap_fatal() at trap_fatal+0x40c/frame 0xfffffe001b1f1800 trap_pfault() at trap_pfault+0x4f/frame 0xfffffe001b1f1860 calltrap() at calltrap+0x8/frame 0xfffffe001b1f1860 --- trap 0xc, rip = 0xffffffff80fb86d7, rsp = 0xfffffe001b1f1930, rbp = 0xfffffe001b1f19f0 --- pf_route() at pf_route+0x4e7/frame 0xfffffe001b1f19f0 pf_test() at pf_test+0xd7b/frame 0xfffffe001b1f1b90 pf_check_out() at pf_check_out+0x22/frame 0xfffffe001b1f1bb0 pfil_mbuf_out() at pfil_mbuf_out+0x38/frame 0xfffffe001b1f1be0 ip_output() at ip_output+0xb4a/frame 0xfffffe001b1f1ce0 ip_forward() at ip_forward+0x3c2/frame 0xfffffe001b1f1d90 ip_input() at ip_input+0x6e9/frame 0xfffffe001b1f1df0 swi_net() at swi_net+0x128/frame 0xfffffe001b1f1e60 ithread_loop() at ithread_loop+0x257/frame 0xfffffe001b1f1ef0 fork_exit() at fork_exit+0x7f/frame 0xfffffe001b1f1f30 fork_trampoline() at fork_trampoline+0xe/frame 0xfffffe001b1f1f30 --- trap 0xaf34f5ea, rip = 0x56a9887e31914e4f, rsp = 0x4506b2da7d808177, rbp = 0xf56feca9dc25ff3d --- db:1:pfs> show registers cs 0x20 ds 0x3b es 0x3b fs 0x13 gs 0x1b ss 0x28 rax 0x12 rcx 0xffffffff81457767 rdx 0xfffffe001b1f1250 rbx 0x100 rsp 0xfffffe001b1f1610 rbp 0xfffffe001b1f1610 rsi 0x30 rdi 0xffffffff82d40298 vt_conswindow+0x10 r8 0 r9 0 r10 0 r11 0 r12 0 r13 0 r14 0xffffffff813db3a1 r15 0xfffffe00c498ae40 rip 0xffffffff80d38812 kdb_enter+0x32 rflags 0x86 kdb_enter+0x32: movq $0,0x2344ff3(%rip) db:1:pfs> show pcpu cpuid = 0 dynamic pcpu = 0x111df00 curthread = 0xfffffe00c498ae40: pid 12 tid 100063 critnest 1 "swi1: netisr 6" curpcb = 0xfffffe00c498b360 fpcurthread = none idlethread = 0xfffffe00c48d73a0: tid 100003 "idle: cpu0" self = 0xffffffff84010000 curpmap = 0xffffffff83021ab0 tssp = 0xffffffff84010384 rsp0 = 0xfffffe001b1f2000 kcr3 = 0x80000000c5d25003 ucr3 = 0xffffffffffffffff scr3 = 0x2f5f9db5f gs32p = 0xffffffff84010404 ldt = 0xffffffff84010444 tss = 0xffffffff84010434 curvnet = 0xfffff80001279200 db:1:pfs> run lockinfo db:2:lockinfo> show locks No such command; use "help" to list available commands db:2:lockinfo> show alllocks No such command; use "help" to list available commands db:2:lockinfo> show lockedvnods Locked vnodes ************************************************************************ Fatal trap 12: page fault while in kernel mode cpuid = 5; apic id = 05 fault virtual address = 0x50 fault code = supervisor read data, page not present Fatal trap 12: page fault while in kernel mode Fatal trap 12: page fault while in kernel mode instruction pointer = 0x20:0xffffffff80fb86d7 cpuid = 1; Fatal trap 12: page fault while in kernel mode apic id = 01 cpuid = 3; stack pointer = 0x28:0xfffffe001b1e2930 Fatal trap 12: page fault while in kernel mode frame pointer = 0x28:0xfffffe001b1e29f0 cpuid = 0; apic id = 00 fault virtual address = 0x50 fault code = supervisor read data, page not present fault virtual address = 0x50 instruction pointer = 0x20:0xffffffff80fb86d7 stack pointer = 0x28:0xfffffe001b1f1930 frame pointer = 0x28:0xfffffe001b1f19f0 code segment = base 0x0, limit 0xfffff, type 0x1b Fatal trap 12: page fault while in kernel mode = DPL 0, pres 1, long 1, def32 0, gran 1 code segment = base 0x0, limit 0xfffff, type 0x1b = DPL 0, pres 1, long 1, def32 0, gran 1 processor eflags = interrupt enabled, resume, IOPL = 0 cpuid = 6; apic id = 06 processor eflags = interrupt enabled, resume, IOPL = 0 current process = 12 (swi1: netisr 6) rdi: fffff8028743200e rsi: fffffe00c481e82d rdx: 0000000000000000 rcx: fffffe00c481e370 r8: fffffe001b1f1a50 r9: 0000000000000000 rax: 0000000000000000 rbx: fffff80317e5b8b8 rbp: fffffe001b1f19f0 r10: 0000000000000000 r11: fffffe00c481e370 r12: fffffe00c481e370 r13: 0000000000000002 r14: fffff802f5b13840 r15: fffffe001b1f1c78 trap number = 12 panic: page fault cpuid = 0 time = 1695445416 KDB: enter: panicnet.isr.numthreads: 1 net.isr.maxprot: 16 net.isr.defaultqlimit: 256 net.isr.maxqlimit: 10240 net.isr.bindthreads: 0 net.isr.maxthreads: 1 net.isr.dispatch: hybridWhen primary booted, I just selected Reboot in GUI and confirmed, at the same time secondary firewall crashed
db:1:pfs> bt Tracing pid 0 tid 100007 td 0xfffffe0020565720 kdb_enter() at kdb_enter+0x32/frame 0xfffffe001d7da390 vpanic() at vpanic+0x163/frame 0xfffffe001d7da4c0 panic() at panic+0x43/frame 0xfffffe001d7da520 trap_fatal() at trap_fatal+0x40c/frame 0xfffffe001d7da580 trap_pfault() at trap_pfault+0x4f/frame 0xfffffe001d7da5e0 calltrap() at calltrap+0x8/frame 0xfffffe001d7da5e0 --- trap 0xc, rip = 0xffffffff80fb86d7, rsp = 0xfffffe001d7da6b0, rbp = 0xfffffe001d7da770 --- pf_route() at pf_route+0x4e7/frame 0xfffffe001d7da770 pf_test() at pf_test+0xd7b/frame 0xfffffe001d7da910 pf_check_out() at pf_check_out+0x22/frame 0xfffffe001d7da930 pfil_mbuf_out() at pfil_mbuf_out+0x38/frame 0xfffffe001d7da960 ip_output() at ip_output+0xb4a/frame 0xfffffe001d7daa60 ip_forward() at ip_forward+0x3c2/frame 0xfffffe001d7dab10 ip_input() at ip_input+0x6e9/frame 0xfffffe001d7dab70 netisr_dispatch_src() at netisr_dispatch_src+0x22c/frame 0xfffffe001d7dabc0 ether_demux() at ether_demux+0x149/frame 0xfffffe001d7dabf0 ether_nh_input() at ether_nh_input+0x36e/frame 0xfffffe001d7dac50 netisr_dispatch_src() at netisr_dispatch_src+0xaf/frame 0xfffffe001d7daca0 ether_input() at ether_input+0x69/frame 0xfffffe001d7dad00 iflib_rxeof() at iflib_rxeof+0xc46/frame 0xfffffe001d7dae00 _task_fn_rx() at _task_fn_rx+0x72/frame 0xfffffe001d7dae40 gtaskqueue_run_locked() at gtaskqueue_run_locked+0x14e/frame 0xfffffe001d7daec0 gtaskqueue_thread_loop() at gtaskqueue_thread_loop+0xc2/frame 0xfffffe001d7daef0 fork_exit() at fork_exit+0x7f/frame 0xfffffe001d7daf30 fork_trampoline() at fork_trampoline+0xe/frame 0xfffffe001d7daf30 --- trap 0x5965b2cb, rip = 0x526ba4d649ac9358, rsp = 0xe81fd03ea07c40f8, rbp = 0 --- db:1:pfs> show registers cs 0x20 ds 0x3b es 0x3b fs 0x13 gs 0x1b ss 0 rax 0x12 rcx 0xffffffff81457767 rdx 0xfffffe001d7d9fd0 rbx 0x100 rsp 0xfffffe001d7da390 rbp 0xfffffe001d7da390 rsi 0x2d rdi 0xffffffff82d40298 vt_conswindow+0x10 r8 0 r9 0 r10 0 r11 0 r12 0 r13 0 r14 0xffffffff813db3a1 r15 0xfffffe0020565720 rip 0xffffffff80d38812 kdb_enter+0x32 rflags 0x82 kdb_enter+0x32: movq $0,0x2344ff3(%rip) db:1:pfs> show pcpu cpuid = 0 dynamic pcpu = 0x122bf00 curthread = 0xfffffe0020565720: pid 0 tid 100007 critnest 1 "if_io_tqg_0" curpcb = 0xfffffe0020565c40 fpcurthread = none idlethread = 0xfffffe00205673a0: tid 100003 "idle: cpu0" self = 0xffffffff84210000 curpmap = 0xffffffff83021ab0 tssp = 0xffffffff84210384 rsp0 = 0xfffffe001d7db000 kcr3 = 0x73a43000 ucr3 = 0xffffffffffffffff scr3 = 0x15ba88000 gs32p = 0xffffffff84210404 ldt = 0xffffffff84210444 tss = 0xffffffff84210434 curvnet = 0xfffff80001241400 db:1:pfs> run lockinfo db:2:lockinfo> show locks No such command; use "help" to list available commands db:2:lockinfo> show alllocks No such command; use "help" to list available commands db:2:lockinfo> show lockedvnods Locked vnodes ************************************************************************************** Fatal trap 12: page fault while in kernel mode cpuid = 0; apic id = 00 fault virtual address = 0x50 fault code = supervisor read data, page not present instruction pointer = 0x20:0xffffffff80fb86d7 stack pointer = 0x0:0xfffffe001d7da6b0 frame pointer = 0x0:0xfffffe001d7da770 code segment = base 0x0, limit 0xfffff, type 0x1b = DPL 0, pres 1, long 1, def32 0, gran 1 processor eflags = interrupt enabled, resume, IOPL = 0 current process = 0 (if_io_tqg_0) rdi: fffff8011bf9c80e rsi: fffffe002049d82d rdx: 0000000000000000 rcx: fffffe002049d370 r8: fffffe001d7da7d0 r9: 0000000000000000 rax: 0000000000000000 rbx: fffff8015b76d3b0 rbp: fffffe001d7da770 r10: 0000000000000000 r11: fffffe002049d370 r12: fffffe002049d370 r13: 0000000000000002 r14: fffff802da989c60 r15: fffffe001d7da9f8 trap number = 12 panic: page fault cpuid = 0 time = 1695450285 KDB: enter: panicnet.isr.numthreads: 1 net.isr.maxprot: 16 net.isr.defaultqlimit: 256 net.isr.maxqlimit: 10240 net.isr.bindthreads: 0 net.isr.maxthreads: 1 net.isr.dispatch: hybrid -
If it makes sense, I have re-configured both nodes with LAGGs to exactly match order and interface names, but it did not change anything in this behavior. So far I can't reproduce this in VMs, but one of the VMs was crashed once sometime ago when I tried other pf bug replication, unfortunately I have not saved this crash, but it was similar, fatal trap 12, referring to two exact things:
fault virtual address = 0x50
and
fault code = supervisor read data, page not present -
@w0w Can you try disabling pfsync?
Need help fast? https://www.netgate.com/support
-
@cmcdonald
Last time when I disabled pfsync, it stopped to crash. But I need to re-test it. -
@cmcdonald
Yes, looks like the problem is limited to “Synchronize states” option. -
@w0w I've had a look at that dump, and while I think I've identified what's going wrong I do not understand how we can end up in that situation.
It'd be interesting to get a full core dump (as opposed to these text dumps). Are you up for reproducing the problem and sharing a core dump (along with the exact version you triggered the crash on, of course)?
Short version: add a device for a swap partition, ideally at least as large as system RAM. A USB stick should work. (Note you'll lose all data on the stick!)
If the USB (or other) swap device is da0 do:gpart destroy -F da0 gpart create -s gpt da0 gpart add -t freebsd-swap da0Add
/dev/da0p1 none swap sw 0 0to /etc/fstab.
Edit /etc/pfSense-ddb.conf and change thescript kdb.enter.defaulttoscript kdb.enter.default=bt ; show registers ; dump ; reset.Reboot.
Future panics should dump a kernel core to the swap partition, which will get saved to /var/crash on the next boot. Those files (along with an exact version number of the system this happened on) should let us dig a bit deeper.
-
@w0w What if you restrict pfsync updates from primary to secondary only, a vice-versa...instead of bi-directional syncing?