pfSense 2.7.2 in Hyper-V freezing with no crash report after reboot
-
I've been having the same issue when I first upgraded to 2.7.0. (at least I think it is the same issue). After 3-4 days pfSense would freeze completely, no GUI, no SSH and no console.
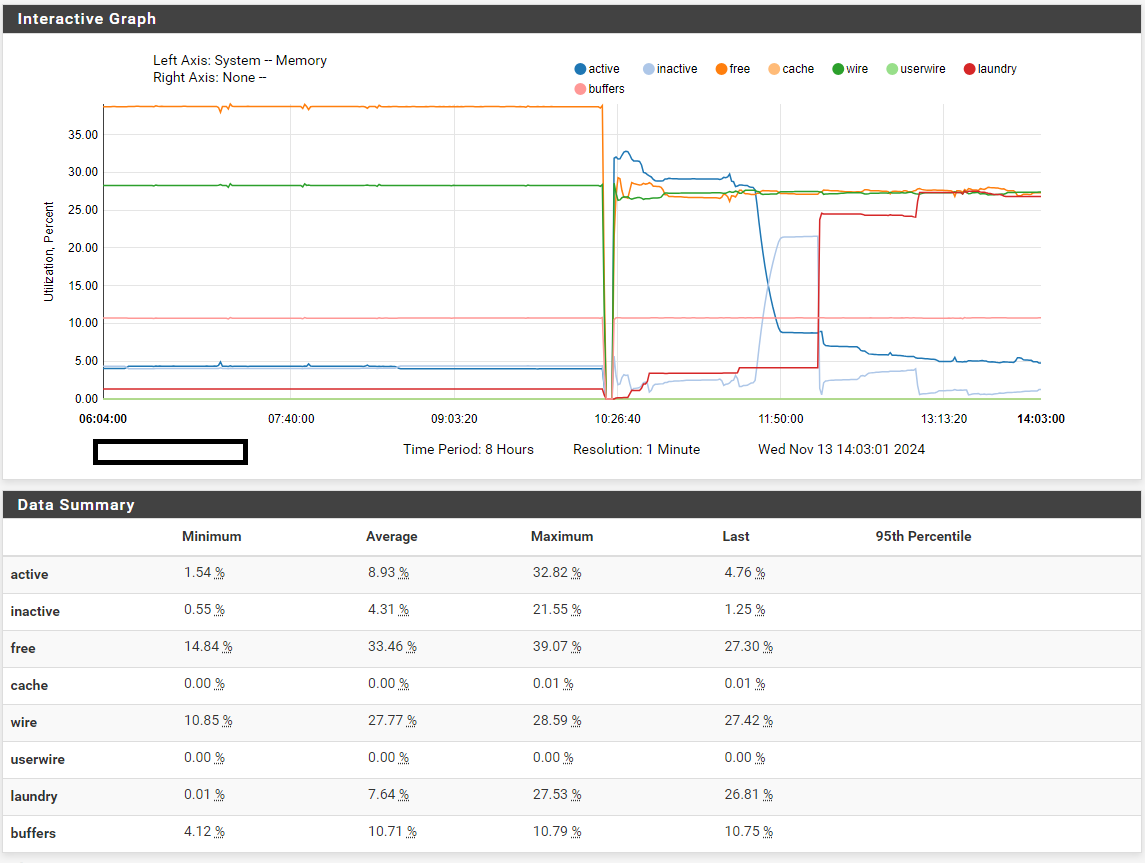
As I only have one installation of pfSense and use it as VPN (openVPN+IPSec) server to access work network from home, when it would freeze I also had no access to the VM until the next day. In the few cases that I was there during the freeze i noticed the following:- GUI would go first. It would slow down to a crawl and soon stopped responding.
- By the time GUI was unresponsive, SSH would still work but was excruciatingly slow. Then after a while SSH would no longer connect. However OpenVPN / IPSec and routing in general seemed to be still working (probably with limited bandwidth).
- Not sure of the timeframe but once SSH failed to connect, console was also dead. Hitting Ctrl-T at the console did nothing, it's completely frozen.
It is curious that IP connectivity was the last to go, i.e. there were still some packets passing through the router while the console was frozen. I know because, while being there, sometimes access to the internet would slow down and I would check the console and it was already frozen. After a few minutes IP connectivity would fail as well.
I know all this doesn't help much, but the way I see it there must be something wrong at the kernel level (or kernel driver). No matter what a user level process does it cannot bring the entire system down (after all that's what the whole point of running the kernel in ring-0 protection level - isolating processes from one another and protecting the entire system from misbehaving processes).
P.S.: I've since downgraded to 2.6 and have no issues at all. Still I would love to figure this out so I can upgrade to 2.7 again.
-
Is this an old VM? Was it created as an old hyper-v version?
Anything logged at all?
-
@stephenw10 it was quite few months ago, so I'm not really sure.
I know it was on hyperv 2016 (the free version). I think at some point I had a crash that totally messed up the VHD so I just reinstalled 2.7.0 from scratch on new VM and imported last saved configuration. Didn't make any difference, same issue in a few days. No logs whatsoever. I mean nothing out of the ordinary, just started to slow down, and finally froze. -
I don't have anything hyper-V here but someone may have a suggestion.
-
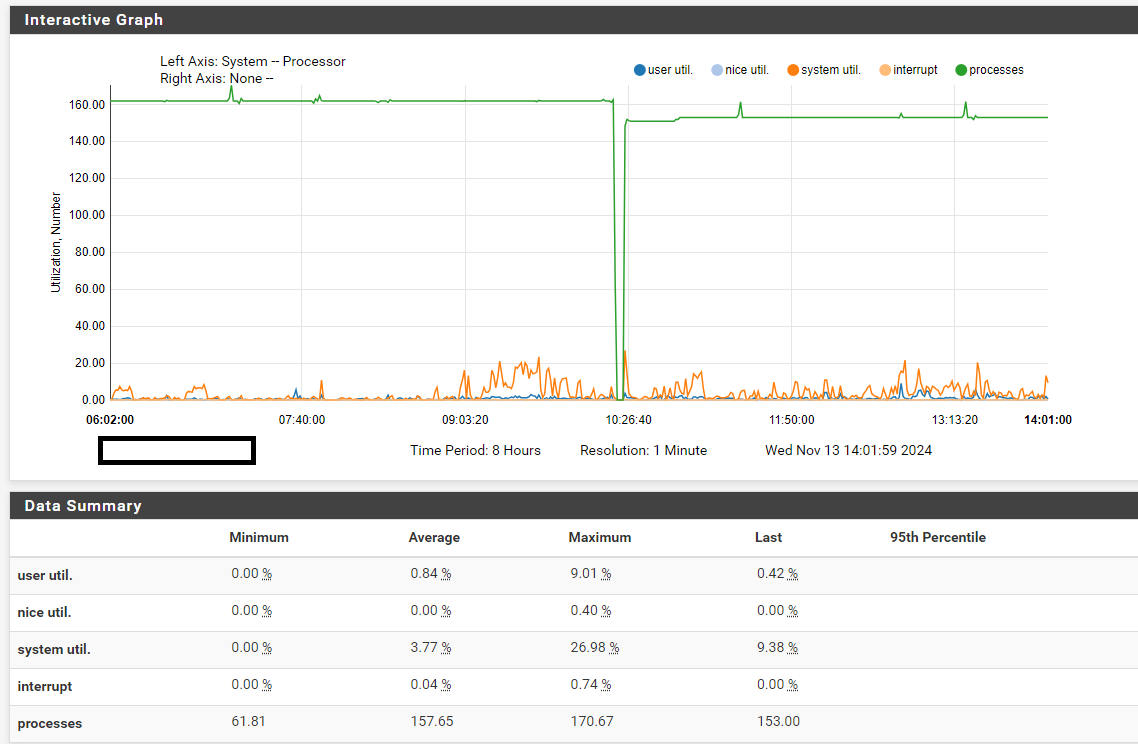
Monitor top -aSHm cpu via SSH, and you'll see [kernel{hveventN}] consuming all your CPU until pfSense crashes or freezes. While it's difficult to reproduce, certain factors increase its occurrence, such as using large filter lists, extensive MAC filters for CP, bogonv6, scheduled rule times (cron 00/15/30/45), and actions triggering filter reloads.
This issue also occurs on bare metal, but it's so rare that most users don’t notice it; I experienced it twice since January. However, after transitioning from bare metal to Hyper-V two weeks ago, it now happens 2-3 times a week.
I suspect that under specific conditions, the filter reload causes a process to lose its thread connections, resulting in an event storm.
No such problems with version 2.6.0 on the same HW or Hypervisor.
I'm sure dtrace or maybe procstat can shed some light here but that's beyond my capabilities.
-
Quick update: No incidents occurred for 7 days after disabling scheduled rule times. However, an incident recurred this morning after I manually enabled and disabled a WAN interface rule. I'm now disabling bogons for that interface to further troubleshoot.
-
@Bismarck What are you triggering with cron? I'd like to try replicating it in one of our testsetups.
Do you use large filter lists? -
@Techniker_ctr Maybe all my list are around 40k. To replicate, enable bognsv6 on your WAN interface (over 150k lines) and create a WAN rule with "scheduled rule times." With the cron package installed, check for /etc/rc.filter_configure_sync entrie which get executed every 0, 15, 30, and 45 minutes. Alternatively, install pfBlockerNG (which I don't have) and enable its heavy lists, duplicate the cronjob few times for overlapping schedules, and generate some traffic. Having a CP on an interface with few 100 of MACs should help, just ad rules at all available Interfaces. Expect results within 12-24 hours.
-
@Bismarck Status update: No incident in 9 days (incident occurred 4 days after last post). Changes since:
Guest (pfSense VM):
- Removed custom IP block lists; bogons re-enabled.
- Disabled "hn ALTQ support" (all offloading disabled).
- Uninstalled unused WireGuard and Syslogd-NG packages (Syslogd-NG was failing to start).
Host:
- Disabled RSC on interfaces/setSwitch.
- Disabled VMQ on all vNics.
Result: pfSense VM now runs very stable and reliably.
If you ask me, my best guess is disabling "hn ALTQ support" and / or the RSC/VMQ did the trick.
-
Greetings
Thanks for your testing @Bismarck
Unfortunately, we were unable to trigger the crash even after extensive testing. Regardless of how much traffic/states are generated, tables are created, or how often the filter is reloaded.
On our pfSense “hn ALTQ support” is activated.
RSC is deactivated on our host.
VMQ cannot be deactivated due to our infrastructureThis is identical on all our HVs. But we still have some random systems that fail.
Are there any other ideas on how we can trigger the crash?
-
Hi Techniker_ctr,
Unfortunately yesterday it happened again, but it occurs way less than before.
To be honest, I'm out of ideas. Do you use the system patches and apply the security fixes?
Because this system was running fine for 1 - 1 1/2 years without any changes, the issue started around January if I remember it right, and only one of three firewalls is affected.
Host: Windows Server 2022, Drivers are all up to date (2H24), nothing suspicious in the logs.
I saw your FreeBSD forum thread; I have the same issue. I was considering testing the alternate "sense", but a different hypervisor seems like a better solution.
Btw, did you try to run it as a Gen 1 VM?
-
Hi @Bismarck ,
we tried Gen1 as well as Gen2, happens on both setups. Recommended Security Patches are applied on all systems via the patches addon. Crazy is that some of our 2.7.2 pfSenses are running fine since nearly a year on this version, but most of the firewalls we installed or updated to 2.7 were crashing. Sometimes after a crash and reboot they crash a second time shortly after, maybe even a third time on some occasions.
We're also out of ideas, and as it's not wanted by higher levels to set up some proxmox hosts only for the ~300 firewalls, we might try some other firewall systems in near future. We do not know what else we can do for now, as we're unable to replicate it in a way someone at pfSense/OPNsense of FreeBSD could replicate it as well. -
Regarding your installations is it UFS or ZFS, could you check
topfor an ARC entry (e.g., "ARC: 2048B Total, 2048B Header")?I have three UFS pfSense instances (one bare metal, two VMs), and only one VM exhibits this issue. It displays an ARC entry in
topand haszfs.koloaded, despite being UFS.Unloading
zfs.kotemporarily removes the ARC entry, but it reappears shortly after. This behavior also occurred during OPNsense testing.I've unloaded and renamed
zfs.koto observe the outcome.HyperV CPU hvevent goes to 100%
Should a UFS machine have an ARC entry in top?
looking for the reason for sudden very high CPU utilization on network/zfs related process"However this is not what is observed. What was observed is consistent with busy waiting. The storagenode process was constantly in the “uwait” process state. As if instead of pulling back, moderating bandwidth, sleeping more, storagenode instead loops at a very fast rate on system calls that fail or return a retry error, or just polls on some event or mutex, thereby consuming high CPU while effectively doing nothing (which is also observed: lower performance, lower overall IO, more missed uploads and downloads)."
/edit
Quick recap: zfs.ko loads due to a trigger in kernel like ZFS storage access. Is your storage dynamic or fixed? This instance experiences the most reads/writes, just a guess. -
@Bismarck Hi, I'm the OPNsense user from the FreeBSD topic and the OPNsense forum thread.
I performed a fresh install of OPNsense 25.1.4 using UFS on a fixed-size VHDX. I only imported the configuration that I use in production.
After about 12 hours during a high-load period in the morning the issue reappeared.
root@proxy01:~ # top -aHSTn last pid: 42090; load averages: 3.50, 1.88, 0.94 up 0+14:51:36 12:33:11 252 threads: 13 running, 226 sleeping, 13 waiting CPU: 1.5% user, 0.0% nice, 0.4% system, 0.0% interrupt, 98.1% idle Mem: 135M Active, 1875M Inact, 1813M Wired, 1100M Buf, 7823M Free Swap: 8192M Total, 8192M Free THR USERNAME PRI NICE SIZE RES STATE C TIME WCPU COMMAND 100004 root 187 ki31 0B 128K RUN 1 872:01 100.00% [idle{idle: cpu1}] 100009 root 187 ki31 0B 128K CPU6 6 871:57 100.00% [idle{idle: cpu6}] 100003 root 187 ki31 0B 128K CPU0 0 871:36 100.00% [idle{idle: cpu0}] 100007 root 187 ki31 0B 128K CPU4 4 871:35 100.00% [idle{idle: cpu4}] 100005 root 187 ki31 0B 128K CPU2 2 871:33 100.00% [idle{idle: cpu2}] 100116 root -64 - 0B 1472K CPU7 7 4:51 100.00% [kernel{hvevent7}] 100008 root 187 ki31 0B 128K RUN 5 871:22 98.97% [idle{idle: cpu5}] 100006 root 187 ki31 0B 128K CPU3 3 871:28 96.97% [idle{idle: cpu3}] 101332 www 21 0 537M 59M kqread 2 11:31 3.96% /usr/local/sbin/haproxy -q -f /usr/local/etc/haproxy.conf -p /var/run/haproxy.pid{haproxy} 100902 www 21 0 537M 59M kqread 4 12:29 1.95% /usr/local/sbin/haproxy -q -f /usr/local/etc/haproxy.conf -p /var/run/haproxy.pid{haproxy} 101333 www 23 0 537M 59M kqread 5 11:17 1.95% /usr/local/sbin/haproxy -q -f /usr/local/etc/haproxy.conf -p /var/run/haproxy.pid{haproxy} 101334 www 21 0 537M 59M CPU1 1 10:57 1.95% /usr/local/sbin/haproxy -q -f /usr/local/etc/haproxy.conf -p /var/run/haproxy.pid{haproxy} 100010 root 187 ki31 0B 128K RUN 7 867:24 0.00% [idle{idle: cpu7}] 100805 root 20 0 81M 52M nanslp 5 3:09 0.00% /usr/local/bin/php /usr/local/opnsense/scripts/routes/gateway_watcher.php interface routes alarm 100102 root -64 - 0B 1472K - 0 1:14 0.00% [kernel{hvevent0}] 100104 root -64 - 0B 1472K - 1 0:59 0.00% [kernel{hvevent1}] 100114 root -64 - 0B 1472K - 6 0:56 0.00% [kernel{hvevent6}] 100106 root -64 - 0B 1472K - 2 0:56 0.00% [kernel{hvevent2}] root@proxy01:~ # kldstat | grep zfs root@proxy01:~ # top | grep arcAs you can see, hvenvent7 is at 100% CPU. ZFS is not loaded, and there's no ARC entry visible in the top command.
I also have another router configured as a CARP secondary with the same configuration. If the primary goes down, the secondary experiences the same issue. However, on three other routers (also using CARP but with different usage patterns), I’ve never encountered this problem. Those routers have different loads and usage scenarios.
About a year ago, we were using pfSense and had the exact same issue, which led us to switch to OPNsense. We didn’t encounter the issue again—until the FreeBSD version was updated. If I downgrade to OPNsense 24.1 (based on FreeBSD 13), the problem does not occur.
-
Are you able to confirm if it still happens in FreeBSD 15? So in Plus 24.03 or later or 2.8-beta?
-
@maitops Yeah, it not ZFS or Dynamic disk related, had 2 incidences this week, both in the Tuesday/Thursday afternoons.
While WAN, LAN, and OpenVPN connectivity remain partially functional, OPT1/OPT2/IPSec become unreachable at that time.
In my opinion this issue is not just only a isolated Hyper-V problem, I've had the same on a bare metal setup twice over a period of 5 months since upgradet to 2.7(.2), with Hyper-V it happens on a weekly basis.
Things I've tried this week to mitigate the issue, based on my research with similar problems related to pfSense/OPNsense/FreeBSD 14:
Host
- disabled NUMA Spanning
- set powerplan to High performance
- disable guest timesync integration
VM
- created a loader.conf.local with following lines:
net.isr.bindthreads="1"
net.isr.maxthreads="-1"
hw.hvtimesync.sample_thresh="-1"
hw.hvtimesync.ignore_sync="1" - System Tunables
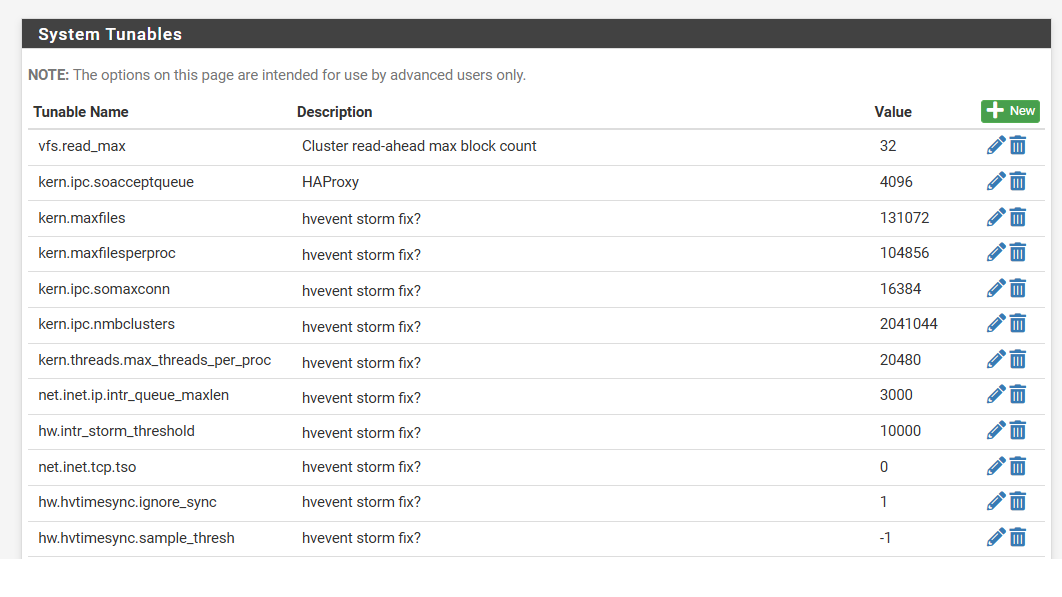
Disclaimer, some of those settings are pure guesswork, as desperation kicks in.
-
@stephenw10 Sadly I can't test on freebsd 15 easily, i don't have anymore the pfsense config, just the opnsense one.
-
@Bismarck Do you use the latest pfsense version with freeBSD 15 ?
All the VM that fail have the HAProxy service running ?The unavaibility of some service are not due because the core used by hvevent is flooded ? So if you're not lucky even the GUI is down.
If its not a Hyper-V issue, what cause a core to run at 100% ? The issue appaer for me on opnsense weekly mostly, sometimes under 12h, sometimes nothing for 15 days. It seem to be linked with high load on HAProxy, because my opnsense router just serve as a HAProxy host. -
@maitops Running pfSense 2.7.2 (FBSD 14) with HAProxy as the only VM. Load wasn't high during the events, even occurring once at 3 AM with zero HAProxy load. The issue may not be HAProxy itself, but a kernel resource over time exhaustion?
I also have another router configured as a CARP secondary with the same configuration. If the primary goes down, the secondary experiences the same issue.
I found this sentence very interesting. Why is that? Maybe that's a starting point?
-
@Bismarck I will provide more context.
I made a cron script that detect if the hvevent issue is triggering and force the router to enter in a CARP maintenance mode. So the secondary is suppose to take the lead when the hvevent occurs. Once the cron worked at 3am, at 6am the second router triggered the hvevent issue too. So the 2nd router probably didn't had an exhaustion over time, it didn't took a lot of traffic during 3h in the night.
Btw the CARP maintenance mode can fail to release some VIP when the hvevent issue occurs. I trigger the CARP Maintenance mode with the web API of the OpnSense (probably work the same on Pfsense).
The VMs are not run on the same host, but all hosts are hyper-v windows server 2022 on AMD EPYC Genoa CPU.