Trouble with configuring Jumbo frames :(
-
I do not manage to configure Jumbo frames in my actual 24.11-RELEASE (amd64) .
I did try to define then MTU value of FW-interface / vlan GW to 9000. That should be possible I think see below, but it is not ^The MTU of a VLAN cannot be greater than that of its parent interface.^
Situation is as follows:
- I have a lagg towards my 10G-switch as trunk for vlans
- I defined that lagg as FW-interface to be capable to set the MTU (which is strange IMHO since that should be a on interface level not at FW-interface level.
- I did set the MTU value to 9000
- technically that lagg is known as opt5 and in the config it is 9000
- in menu interfaces / laggs the lagg is known as LAGG0
- in the config file there is a line '<shellcmd>ifconfig lagg1 mtu 9000</shellcmd>' To note that there has been a lagg1 in the past, but that lagg does not exist any more.
- I did experiment with changing that entry to 'lagg0' but that did not solve the issue
So what is wrong here? How to solve this?
.Note that for jumbo frames a MTU from 9000 is quite common, however:
- what does that imply for the trunk MTU-size and
- the vlan MTU-size
- ^in general L2-MTU versus content MTU^ 9014 seems e.g. relatively common
Using a ConnectX4 lx as 10G interface
-
@louis2 My understanding is the MTU is determined by the native interface, not a VLAN. All a VLAN does is insert a VLAN tag in the header.
The MTU determines the maximum size of the payload in an Ethernet frame. That payload is usually IP.
-
@louis2 so out of curiosity what do you think this gets you?
Is this a storage network that your routing? Are you seeing under performance on your 10ge interface with standard 1500 mtu and your trying to increase the performance? From what to what, from where to where? Are you using iSCSI over this connection? etc..
You know jumbo were a thing back in the day when the cpu had to process, so larger mtu meant less processing - but today, really it more of a hassle than anything.
If you had some SAN or something, and your NAS front end needed to get to its actual store over the 10ge link - and you were moving large chunks of data..
I would love to see your testing of 1500 vs jumbo in your transferring of data - where jumbo made such a significant difference that it makes sense to mess around with it..
-
There are a couple of advantages related to jumbo frames:
- less overhead at the NAS
- more efficient transport
- 6 times less packages to process in the FW
- more efficient at the destination.
I do not know how big the overall benefit is (at 10G), is to be tested.
But why should you not use jumbo frames(!?) given the nowadays much higher speed and high quality fiber connections!
-
@louis2 said in Trouble with configuring Jumbo frames :(:
But why should you not use jumbo frames(!?) given the nowadays much higher speed and high quality fiber connections!
Reply
Jumbo frames need to be enabled end2end. So if this is just flows within your network then go ahead. Out to the internet obviously wont work. I say use it and see if you get increased throughput.
In advanced networks Jumbo is a requirement (i.e. vxlan). If you want to toy around with that protocol you need Jumbo enabled.Firewall: NetGate,Palo Alto-VM,Juniper SRX
Routing: Juniper, Arista, Cisco
Switching: Juniper, Arista, Cisco
Wireless: Unifi, Aruba IAP
JNCIP,CCNP Enterprise -
Yep it is locally on my own network and all my switches do support jumbo frames no problem!
-
@louis2 and all your devices do - like your printer(s).. For jumbo to work it needs to be end to end with all devices involved.. And then I doubt your internet is jumbo, and for sure stuff out on the internet isn't - so you could run into stuff at your L3 having to be fragmented to go talk to something else, etc.. So guess what device your just pushing that extra work too.. Your low end firewall/router, etc..
To be honest other than specialty network, like a SAN.. and protocol like iSCSI it more than likely is not worth it..
If you want to setup a san between your pc and your nas at 10ge sure do that.. But what would that have to do with pfsense interface or a trunk/lag interface, etc.
I just don't see jumbo being something to even worry about other than some specialty setup - but sure have fun if you want, I just think its a waste time for at best a few % points, and a whole lot of extra headache..
So what would be interesting is sure do a test from your PC to your NAS using jumbo on the same network.. Now pfsense isn't even involved.. What speeds to do you get using jumbo, what speeds with 1500... And then what sort of difference in cpu do you see on your nas and your pc when doing 1500vsjumbo.
If its worth while to expand that to your whole network - great, now do other traffic like your PC using jumbo to and from the internet - do you see any performance difference, and difference in cpu load on pfsense or PC?
The only reason I can see for even entertaining changing the mtu, which is going to be some hoops is your 10ge at 1500 is not performing.. Are you getting enough speed to saturate your current disks both in read and write? Are your cpus on these devices just maxing out when you move a file? If your seeing full speed of your disks, and network is not the bottleneck - why mess with jumbo?
An intelligent man is sometimes forced to be drunk to spend time with his fools
If you get confused: Listen to the Music Play
Please don't Chat/PM me for help, unless mod related
SG-4860 25.07.1 | Lab VMs 2.8.1, 25.07.1 -
@michmoor said in Trouble with configuring Jumbo frames :(:
So if this is just flows within your network then go ahead. Out to the internet obviously wont work.
The router will not pass the jumbo frames, if not configured for them on both sides. This means Path MTU Discovery (PMTUD) will kick in, limiting the size of packets passing through the router.
I remember the days of token ring, which could handle even larger frames than 9000. 16K?
-
@louis2 said in Trouble with configuring Jumbo frames :(:
Yep it is locally on my own network and all my switches do support jumbo frames no problem!
WiFi? I know WiFi has it's own version of jumbo frames, but that's to improve WiFi efficiency. I don't know how well it will handle this.
-
@johnpoz said in Trouble with configuring Jumbo frames :(:
so you could run into stuff at your L3 having to be fragmented to go talk to something else, etc..
Fragmenting is obsolete. Path MTU discovery is used exclusively on IPv6 and largely on IPv4. With Linux, everything uses PMTUD on both IPv4 and IPv6. Windows uses it for TCP, but not other things. However, there's not much other than TCP that would have frames that big.
What speeds to do you get using jumbo, what speeds with 1500... And then what sort of difference in cpu do you see on your nas and your pc when doing 1500vsjumbo.
Maybe we should all go back to 576, as was often used in the early days of the Internet. I used to use that back in the mid 90s, when I first started using it with my dial up SLIP connection.
PfSense running on Qotom mini PC
i5 CPU, 4 GB memory, 32 GB SSD & 4 Intel 1 Gb Ethernet ports.
UniFi AC-Lite access pointI haven't lost my mind. It's around here...somewhere...
-
@johnpoz said in Trouble with configuring Jumbo frames :(:
Are your cpus on these devices just maxing out when you move a file?
Another reason is the interpacket gap, which is 9.6 nS at 10 Gb. This means there's no traffic passed during that time. With faster networks, it soon adds up.
-
@JKnott said in Trouble with configuring Jumbo frames :(:
Path MTU discovery is used exclusively on IPv6 and largely on IPv4.
And doesn't always work..
Lets forget all the details.. My overall point is - unless the connection is not performing to his needs there is little reason to try and squeeze some theoretical extra out of it.. or efficiencies
Can his disks even even read or write where he would notice 9gbps vs 6gbps for example? What is his cpu use on all the devices in the path doing?
For all we know he is doing 9.39gbps now and jumbo would get him to say 9.41gbps, but disks are a bottleneck with any over 3..
Without a baseline benchmark of what is going on currently - its pointless to fiddle with jumbo, for all you know without the baseline is you will lower performance..
Something as simple an iperf with -V would give you a place to start
$ iperf3.exe -V -c 192.168.10.10 iperf 3.18 CYGWIN_NT-10.0-19045 i9-win 3.5.4-1.x86_64 2024-08-25 16:52 UTC x86_64 Control connection MSS 1460 Time: Fri, 18 Apr 2025 21:11:28 GMT Connecting to host 192.168.10.10, port 5201 Cookie: w6mju6xodzvlngg2tpiirvcdjnkthkytzsvm TCP MSS: 1460 (default) [ 5] local 192.168.10.9 port 60804 connected to 192.168.10.10 port 5201 Starting Test: protocol: TCP, 1 streams, 131072 byte blocks, omitting 0 seconds, 10 second test, tos 0 [ ID] Interval Transfer Bitrate [ 5] 0.00-1.02 sec 409 MBytes 3.38 Gbits/sec [ 5] 1.02-2.00 sec 400 MBytes 3.40 Gbits/sec [ 5] 2.00-3.00 sec 408 MBytes 3.42 Gbits/sec [ 5] 3.00-4.01 sec 410 MBytes 3.42 Gbits/sec [ 5] 4.01-5.01 sec 407 MBytes 3.41 Gbits/sec [ 5] 5.01-6.01 sec 409 MBytes 3.42 Gbits/sec [ 5] 6.01-7.00 sec 400 MBytes 3.40 Gbits/sec [ 5] 7.00-8.00 sec 406 MBytes 3.40 Gbits/sec [ 5] 8.00-9.01 sec 407 MBytes 3.39 Gbits/sec [ 5] 9.01-10.01 sec 407 MBytes 3.41 Gbits/sec - - - - - - - - - - - - - - - - - - - - - - - - - Test Complete. Summary Results: [ ID] Interval Transfer Bitrate [ 5] 0.00-10.01 sec 3.97 GBytes 3.40 Gbits/sec sender [ 5] 0.00-10.02 sec 3.97 GBytes 3.40 Gbits/sec receiver CPU Utilization: local/sender 29.6% (4.3%u/25.2%s), remote/receiver 44.1% (1.3%u/42.8%s) rcv_tcp_congestion cubic iperf Done.So lets call it 400MBps - if the disks can not read or write at speed - anything over that is not going to get you much.. My rust drives can only sustain about 270MBps write anyway.. So even if I had 10ge vs the 5ge interfaces I currently have, and the NAS one is just a usb interface, so very limited there.. Going jumbo at best would lower some cpu usage..
Now possible some lowering of that cpu use could help - but the user is pretty low anyway.. And its not like my cpu is always near max while saving a few cpu cycles while moving files is going to make any significant difference in overall performance that would be notice.. What does if when I transfer some files my cpu goes to 45 vs 40 util? And keep in mind that is prob reporting on only 1 cpu, both my pc and my nas has multiple..
Now here is with Jumbo..
$ iperf3.exe -V -c 192.168.10.10 iperf 3.18 CYGWIN_NT-10.0-19045 i9-win 3.5.4-1.x86_64 2024-08-25 16:52 UTC x86_64 Control connection MSS 8960 Time: Fri, 18 Apr 2025 21:13:51 GMT Connecting to host 192.168.10.10, port 5201 Cookie: jld4lka6x63xveq3u3wayaearobxrduqycql TCP MSS: 8960 (default) [ 5] local 192.168.10.9 port 23452 connected to 192.168.10.10 port 5201 Starting Test: protocol: TCP, 1 streams, 131072 byte blocks, omitting 0 seconds, 10 second test, tos 0 [ ID] Interval Transfer Bitrate [ 5] 0.00-1.01 sec 425 MBytes 3.51 Gbits/sec [ 5] 1.01-2.01 sec 408 MBytes 3.43 Gbits/sec [ 5] 2.01-3.01 sec 414 MBytes 3.47 Gbits/sec [ 5] 3.01-4.01 sec 413 MBytes 3.48 Gbits/sec [ 5] 4.01-5.00 sec 412 MBytes 3.47 Gbits/sec [ 5] 5.00-6.01 sec 420 MBytes 3.49 Gbits/sec [ 5] 6.01-7.01 sec 417 MBytes 3.51 Gbits/sec [ 5] 7.01-8.00 sec 415 MBytes 3.49 Gbits/sec [ 5] 8.00-9.01 sec 423 MBytes 3.50 Gbits/sec [ 5] 9.01-10.00 sec 404 MBytes 3.43 Gbits/sec - - - - - - - - - - - - - - - - - - - - - - - - - Test Complete. Summary Results: [ ID] Interval Transfer Bitrate [ 5] 0.00-10.00 sec 4.05 GBytes 3.48 Gbits/sec sender [ 5] 0.00-10.01 sec 4.05 GBytes 3.48 Gbits/sec receiver CPU Utilization: local/sender 22.0% (3.1%u/18.9%s), remote/receiver 40.5% (1.8%u/38.7%s) rcv_tcp_congestion cubic iperf Done.So since since the 400MBps is way faster than my disks can write anyway.. The only benefit here is some lower CPU usage.. Is that small amount difference between 1500 and 9k really worth all the fiddling?
I don't really see it - and this is on a specific SAN connection just between my PC and my NAS - only used when they transfer files between each other.. So no worry about fiddling with any switches on my network, nothing to do with pfsense and no worry about talking to anything else on my network that just uses default normal 1500 mtu, etc.
I mean is that file transfer really taxing my cpu where a few percentage would matter? Here is my PC during a iperf test
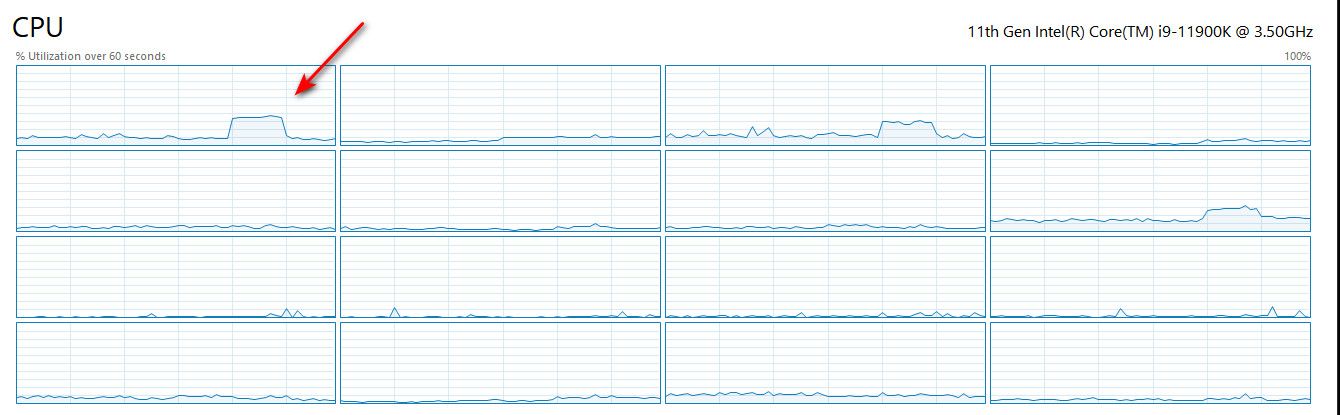
yup there is a bit of a bump there - is dropping that a few % points going do anything? But if I show summary view - it might be 1% util change at best..
So I would really do some sort of baseline benchmark with just using 1500.. And see if moving to jumbo would even do anything for you other some sort feeling that your more efficient..
With modern cpus and modern nics - I don't really see it doing anything worth doing unless you have some sort of specific use case.
-
I will have a detailed look at your mail later (at daytime)
The problem was that my config did contain a line which was probably generated in the past (automatically)
<shellcmd>ifconfig lagg1 mtu 9000</shellcmd>
Lagg1 did exist in the past but not any more !!!I manually changed that line to
<shellcmd>ifconfig lagg0 mtu 9000</shellcmd>
and uploaded / reloaded that configThat seems to have fixed the issue (not the reason that the config was wrong!!)
After the change I could assign 9000 to the related interfaces.No idea if the issue will return below the output of if config
also see pfSense https://redmine.pfsense.org/issues/3922Before the change
ifconfig lagg0
lagg0: flags=1008943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
options=ffef07bb<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,TSO4,TSO6,LRO,VLAN_HWFILTER,NV,VLAN_HWTSO,LINKSTATE,RXCSUM_IPV6,TXCSUM_IPV6,HWSTATS,TXRTLMT,HWRXTSTMP,MEXTPG,TXTLS4,TXTLS6,VXLAN_HWCSUM,VXLAN_HWTSO,TXTLS_RTLMT>
ether e8:eb:d3:2a:79:eb
hwaddr 00:00:00:00:00:00
inet6 fe80::eaeb:d3ff:fe2a:79eb%lagg0 prefixlen 64 scopeid 0xc
laggproto lacp lagghash l2,l3,l4
laggport: mce0 flags=1c<ACTIVE,COLLECTING,DISTRIBUTING>
laggport: mce1 flags=1c<ACTIVE,COLLECTING,DISTRIBUTING>
groups: lagg
media: Ethernet autoselect
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>after the change
[24.11-RELEASE][admin@pfSense.lan]/root: ifconfig lagg0
lagg0: flags=1008943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 9000
options=ffef07bb<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,TSO4,TSO6,LRO,VLAN_HWFILTER,NV,VLAN_HWTSO,LINKSTATE,RXCSUM_IPV6,TXCSUM_IPV6,HWSTATS,TXRTLMT,HWRXTSTMP,MEXTPG,TXTLS4,TXTLS6,VXLAN_HWCSUM,VXLAN_HWTSO,TXTLS_RTLMT>
ether e8:eb:d3:2a:79:eb
hwaddr 00:00:00:00:00:00
inet6 fe80::eaeb:d3ff:fe2a:79eb%lagg0 prefixlen 64 scopeid 0xc
laggproto lacp lagghash l2,l3,l4
laggport: mce0 flags=1c<ACTIVE,COLLECTING,DISTRIBUTING>
laggport: mce1 flags=1c<ACTIVE,COLLECTING,DISTRIBUTING>
groups: lagg
media: Ethernet autoselect
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL> -
I did configure jumbo frames by editing the config file. It is behaving strange
after reload the config
lagg0 is changed in lagg1 and MTU for 9014 to 9000. !!!???But in the mean time I had change the vlan settings to 9000 :( and it works.
Actual results below. Issues are:
- data from NAS to PC is OK
- data from PC to NAS can be / should be better :(
- loosing frames when copying NAS to PC for jet unknow reason
- PC is using a smaller frame size, not optimal IMHO see wireshark traces
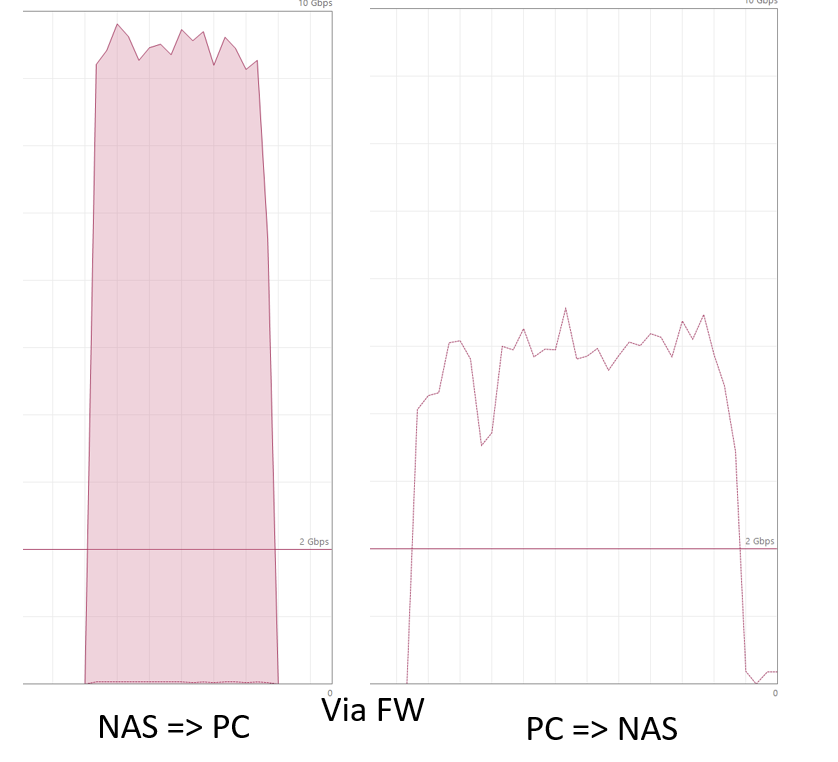

-
@louis2 and that is pretty meaningless without the baseline.. where your just using 1500..
And your length there in your pcap that is over your frame size would indicate your capturing on the sender device that has offload set, where the OS sends larger data and the nic sizes it correctly..
That part about missing previous segment doesn't actually mean anything was lost other not seen in your capture. start your capture earlier before you start sending data your interested in.
The difference could also just mean that the sender pc just not capable of sending any faster - could be disk limitation?
Why I would take the disks out of the equation and use something that just sends traffic on the wire, like iperf. As that an actual copy of data to/from disk?
As to 9014 vs 9000 - this could just be how nic/os displays the same thing - one counting the header, and one not..
For example my nas shows it as 9000, while my PC shows it as 9014.. But if you look at the interface it shows 9000

So your routing this traffic over pfsense, and your hairpinning it over a lagg with vlans.. So you really have no control over actual what physical path the traffic will take.. And your worried about efficiency?
-
John as written I do not know all answers. Know that!
- however it is for sure that the NAS seems to prefer 9014 at trunk level above 9000 (I tested); The NIC in PC, NAS and pfSense are all ConnectX4 Lx. And the default frame values for that nic are higher than 1500 and 9000.
- I do know exactly the route of the lagg
- I do not know why windows 'send-frames' are not the expected 9000 nor that I know how to change that
- the disk at both sides PC and NAS (truenas scale) are NVME-drives. It is fore sure that the NAS can send 10Gbe and the PC can write 10Gbe (see NAS to PC)
- I do not know why not in the opposite. However the smaller frame could be one of the reasons. That is the reason that I searched, but not found a way to change that.
- MTU is not like MTU not like L2-MTU. An MTU of 9000 does probably not imply a net transport capacity of 9000. Probably 'some' bites less needed for overhead. And on L2 the frame needs to be bigger due to again overhead. I assume that this is not new to you. But it makes that it is not all-ways clear what is mend MTU.
- pfSense hardly have, not to say does not have a L2 interface GUI. I think there are bugs in pfSense related L2-handling (as related to laggs). See my experiences.
- the trace was started before the lost frames did occur and it does occur multiple times,
- I assume the length as displayed by WireShark is the L2 MTU-size. The traces are made on the PC. I think that I am going to make taces on the NAS side using pfSense to check what happens there.
-
@louis2 said in Trouble with configuring Jumbo frames :(:
I do know exactly the route of the lagg
Not what I meant - when you though a bunch of vlans on a lagg - you really have no control over what physical wire the traffic will flow over..
you could be up down on the same wire (hairpin), or you could be up wire 1 and down wire 2..
No the len is not the mtu size. How would you think that, it is well over your 9k jumbo
And where is the baseline of 1500?
-
John, I will do a baseline 1500 test (promised!) , however I plan to do that after understanding ^completely^ what happens in the actual (jumbo) setup.
Which is not so easy ..
I did also make a wireshark trace of the traffic between NAS and pfSense and that seems not so 1:1 as I did expect. So one of the things I plan to to is to trace at the two sites of the firewall at the same time and compare them.
I also would like to understand what is causing the difference in transfer speed between NAS => PC and PC => NAS and why the PC is using significant smaller frames (and how to change that).
More issues like:
- what I am loosing packages !? And is that at both sites of the FW?
(using wireshark at pc and probably also pfsense capture is affecting / slowing down the transfer speed) - and the very doubtful way to setup frame/MTU size at pfSense
- what I am loosing packages !? And is that at both sites of the FW?
-
I did make a parallel trace of the frames at both sites (nas side and pc side) of the firewall. The NAS trace using pfSense the PC trace using wireshark.
You can see that the frames at both sites are nowhere the same. I am not yest sure what to think about that and how to improve that.
Hereby I share the captures (as picture)

-
John,
I am sill trying to improve the windows behavoir, but here the speed test I did form NAS to PC.
Which my actual PC NIC-connectX4 settings (jumbo 9000, send and receive buffers 2048 an RoCE on 4096, the rest default / on as far as possible) The figures are as follows:
- NAS => PC using jumbo frames via pfSense 9,3 gbit
- NAS => PC using 1500 frames via pfSense 6,8 gbit
- NAS => PC using 1500 frames same vlan 8.8 gbit
So the conclusion seems to:
- moderate gain for a same lan connection
- big gain with the firewall involved
Note there that the setup of my firewall is significant above average !!
Intel(R) Core(TM) i5-6600K CPU @ 3.50GHz
Current: 3602 MHz, Max: 3500 MHz
4 CPUs : 1 package(s) x 4 core(s)
AES-NI CPU Crypto: Yes (active)
IPsec-MB Crypto: Yes (inactive)
QAT Crypto: No