Problemas con perdida de conexión de la WAN
-
Buenos días a todos, os comento lo que me está pasando que me tiene loco, tengo varios pfSense montados sobre MiniPCS de amazon, de este estilo:
https://www.amazon.es/dp/B07DHBHQYR?ref_=ppx_hzsearch_conn_dt_b_fed_asin_title_1
https://www.amazon.es/dp/B0B6J12LGJ/?coliid=I2DS2H9ADNN6YL&colid=36J85P61Z63IW&ref_=list_c_wl_lv_ov_lig_dp_it
https://www.amazon.es/FakestarPC-generaci%C3%B3n-Firewall-Micro-Device/dp/B0DQBTBZ63/ref=sr_1_3?__mk_es_ES=%C3%85M%C3%85%C5%BD%C3%95%C3%91&s=electronics&sr=1-3El problema que estoy teniendo es que se quedan aleatoriamente colgados sin internet, se cae la WAN, tengo quitado el ASPM, tengo quitado en el gateway el monitoring action, tengo desactivado offloading TSO/Checksum/LRO
Algunas veces desde fuera es accesible, pero los equipos no navegan ni nada, en los logs, a veces veo lo siguiente, son de dos FWS:
Jun 6 00:24:12 dpinger 53814 exiting on signal 15 Jun 6 00:23:24 dpinger 53814 WANGW 192.168.1.1: Clear latency 359us stddev 169us loss 0% Jun 6 00:23:13 dpinger 53814 WANGW 192.168.1.1: Alarm latency 276us stddev 33us loss 33% Jun 7 13:09:51 dpinger 16274 WANGW 192.168.1.1: sendto error: 64 Jun 7 13:09:50 dpinger 16274 WANGW 192.168.1.1: sendto error: 50 Jun 7 13:09:49 dpinger 16274 WANGW 192.168.1.1: sendto error: 50 Jun 7 13:09:49 dpinger 16274 WANGW 192.168.1.1: Alarm latency 0us stddev 0us loss 100% Jun 12 14:50:05 dpinger 36722 send_interval 500ms loss_interval 2000ms time_period 60000ms report_interval 0ms data_len 1 alert_interval 1000ms latency_alarm 500ms loss_alarm 20% alarm_hold 10000ms dest_addr 192.168.2.1 bind_addr 192.168.2.1 identifier "IPSEC_Gateway " Jun 12 14:50:05 dpinger 28600 exiting on signal 15 Jun 12 14:50:05 dpinger 28963 exiting on signal 15 Jun 12 14:50:05 dpinger 28600 WAN_DHCP 192.168.0.1: sendto error: 50 Jun 12 14:50:04 dpinger 28600 WAN_DHCP 192.168.0.1: sendto error: 50 Jun 12 14:50:04 dpinger 28600 WAN_DHCP 192.168.0.1: sendto error: 50 Jun 12 14:50:03 dpinger 28600 WAN_DHCP 192.168.0.1: sendto error: 50 Jun 12 14:50:03 dpinger 28600 WAN_DHCP 192.168.0.1: sendto error: 50El GW sale así:
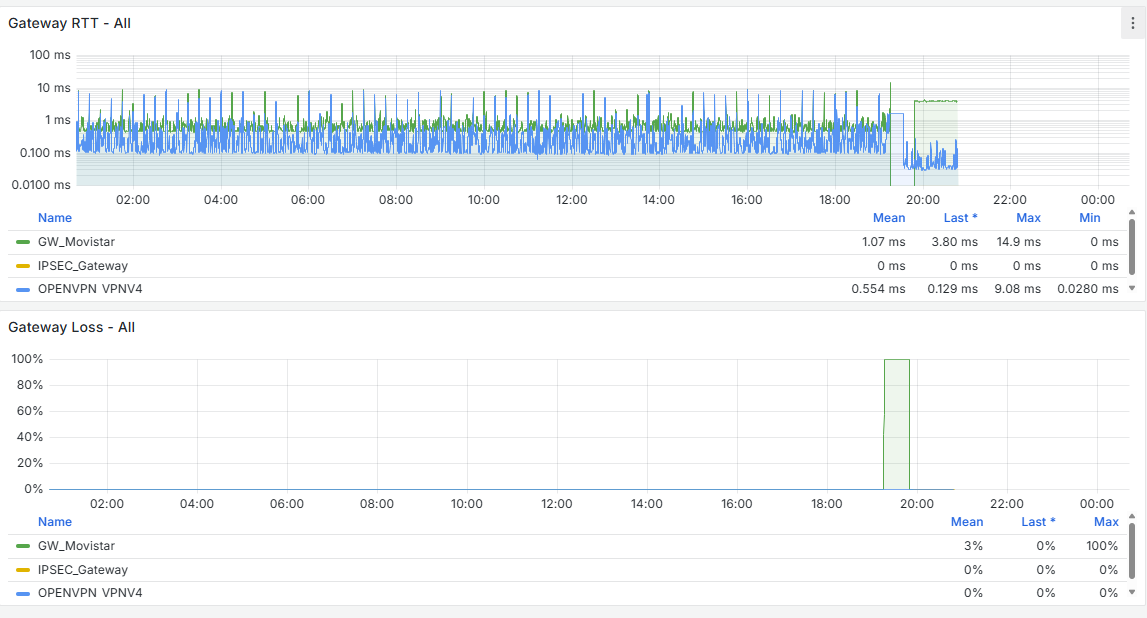
GW_Movistar 192.168.1.1 0.0ms 0.0ms 100% Danger, PacketlossAl hacer ping por ejemplo me sale esto:
PING 8.8.8.8 (8.8.8.8) from 192.168.1.254: 56 data bytes 64 bytes from 8.8.8.8: icmp_seq=0 ttl=112 time=3.423 ms 64 bytes from 8.8.8.8: icmp_seq=1 ttl=112 time=3.485 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=112 time=4.217 ms --- 8.8.8.8 ping statistics --- 3 packets transmitted, 3 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 3.423/3.708/4.217/0.360 ms Si hago ping a 192.168.1.1 no responde PING 192.168.1.1 (192.168.1.1) from 192.168.1.254: 56 data bytes --- 192.168.1.1 ping statistics --- 3 packets transmitted, 0 packets received, 100.0% packet lossLos túneles IPSEC están caídos, no los levanta, y estos son los logs de IPSEC:
Jun 21 20:44:59 charon 67161 01[CFG] vici client 19790 disconnected Jun 21 20:44:59 charon 67161 01[CFG] vici client 19790 requests: list-sas Jun 21 20:44:59 charon 67161 01[CFG] vici client 19790 registered for: list-sa Jun 21 20:44:59 charon 67161 05[CFG] vici client 19790 connected Jun 21 20:44:58 charon 67161 01[KNL] <con1|321> unable to delete SAD entry with SPI c7fe7ebb: No such process (3) Jun 21 20:44:58 charon 67161 01[CHD] <con1|321> CHILD_SA con1{1292} state change: CREATED => DESTROYING Jun 21 20:44:58 charon 67161 01[IKE] <con1|321> IKE_SA con1[321] state change: CONNECTING => DESTROYING Jun 21 20:44:58 charon 67161 01[IKE] <con1|321> establishing IKE_SA failed, peer not responding Jun 21 20:44:58 charon 67161 01[IKE] <con1|321> giving up after 5 retransmits Jun 21 20:44:54 charon 67161 01[CFG] vici client 19789 disconnected Jun 21 20:44:54 charon 67161 05[CFG] vici client 19789 requests: list-sas Jun 21 20:44:54 charon 67161 09[CFG] vici client 19789 registered for: list-sa Jun 21 20:44:54 charon 67161 12[CFG] vici client 19789 connected Jun 21 20:44:43 charon 67161 09[IKE] <con1|321> sending keep alive to IP_PUBLICA[4500] Jun 21 20:44:23 charon 67161 09[IKE] <con1|321> sending keep alive to IP_PUBLICA[4500] Jun 21 20:44:23 charon 67161 09[CFG] vici client 19788 disconnected Jun 21 20:44:18 charon 67161 12[IKE] <con1|321> delaying task initiation, IKE_AUTH exchange in progress Jun 21 20:44:18 charon 67161 12[IKE] <con1|321> queueing CHILD_CREATE task Jun 21 20:44:18 charon 67161 09[CFG] vici initiate CHILD_SA 'con1' Jun 21 20:44:18 charon 67161 09[CFG] vici client 19788 requests: initiate Jun 21 20:44:18 charon 67161 12[CFG] vici client 19788 registered for: control-log Jun 21 20:44:18 charon 67161 10[CFG] vici client 19788 connected Jun 21 20:44:18 charon 67161 09[CFG] vici client 19787 disconnected Jun 21 20:44:18 charon 67161 10[CFG] vici client 19787 requests: list-sas Jun 21 20:44:18 charon 67161 10[CFG] vici client 19787 registered for: list-sa Jun 21 20:44:18 charon 67161 08[CFG] vici client 19787 connected Jun 21 20:44:03 charon 67161 12[IKE] <con1|321> sending keep alive to IP_PUBLICA[4500]Routing tables que tengo son las siguientes:
Internet: Destination Gateway Flags Netif Expire default 192.168.1.1 UGS igc0 IP_PUBLICA 192.168.1.1 UGHS igc0 127.0.0.1 link#8 UH lo0 172.16.0.0/24 link#2 U igc1 172.16.0.1 link#8 UHS lo0 172.16.2.0/24 link#11 U igc1.2 172.16.2.1 link#8 UHS lo0 172.16.10.0/24 link#12 U ovpns1 172.16.10.1 link#8 UHS lo0 192.168.1.0/24 link#1 U igc0 192.168.1.254 link#8 UHS lo0 192.168.255.254 link#8 UH lo0Todo esto, mientras la WAN está marcada como caída y antes de reiniciar el FW, una vez que se reinicia, vuelve a la vida sin problemas, esto, me está pasando en varios, lo tengo montado de la siguiente manera:
Paquetes: ACME, Snort, pfBlocker, ntopng, Telegraf, Cron, Filer, OpenVPN client export, service watchdog y system partches
Las reglas las tengo puestas como reglas flotantes, solo permito hacía afuera el Ping y los puertos de navegación correo y poco mas según cada red, con vlanes para dispositivos móviles
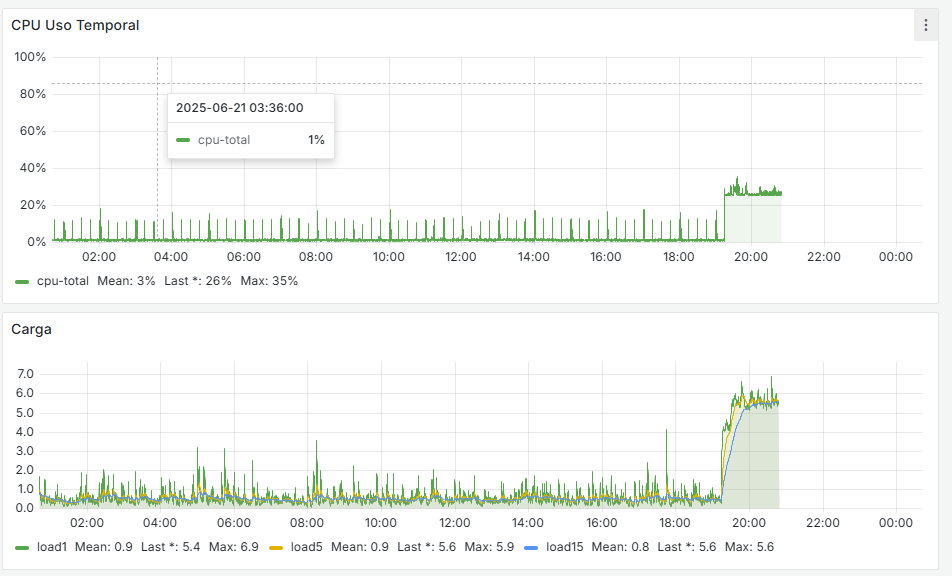
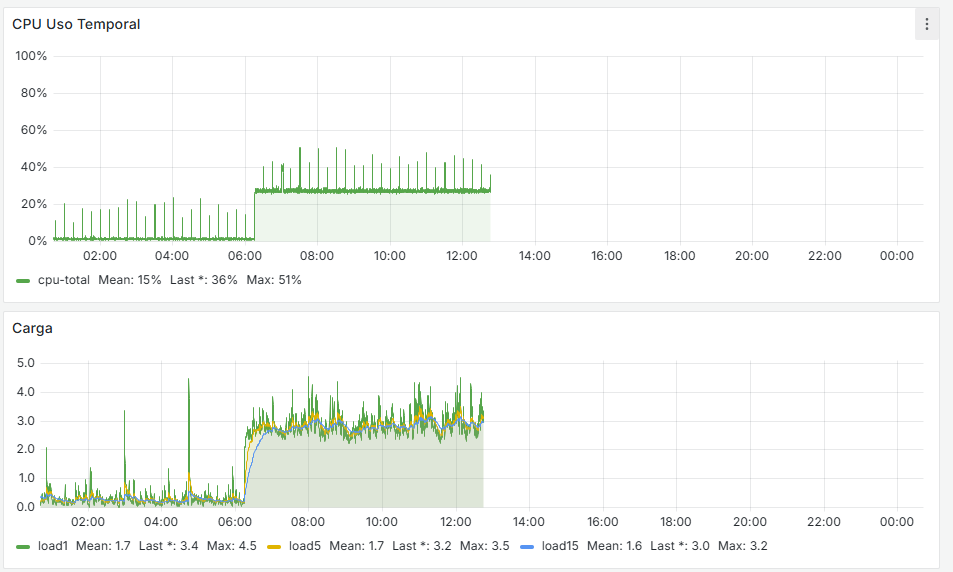
Una cosa que observo cuándo pasa es que en Grafana, se dispara el uso de CPU y la carga, como se ve en las imágenes:
Estoy desesperado, las versiones van desde la 2.7.2 y 2.8.0 a la plus 24.11, no se que mas datos daros para ver si alguien me puede dar luz con este tema.
-
@dcuadrados si tienes reinicios de la wan o inestabilidad claro que afecta a todas las VPNs y tendra reinicios es normal eso.
Ya probastes si tus proveedores de internet estan operando bien? yo me conectaria a cada uno y haria pruebas directo con ellos, fuera de pfsense.
Ahora es log es solo el gw, muestra a ese mismo dia/hora/minuto/segundo el de system, para ver que le sucede a el sistema cuando hay intermitencia.
Y ultima pregunta, tus NICs WANs y LAN como se llaman?
pregunta, tienes expuesto algu servicio hacia internet?
Si no, suricata es un paquete le carga la mano a las interfaces y se recomienda cuando hay servicos publicos, de lo contrario no tiene mucho sentido, al menos que andes buscando algo?Y por ultimo, por que reglas flotantes?, lo veo innecesario, pero espero que entiendas perfectamente como funciona su logica, es tu equipo tu decision.
Saludos.
-
@periko Bueno días, tras mirar bien la monitorización, descubrí que el problema era una tarea programada Cron que cada 15 minutos se ejecutaba al tener unas reglas con horario, la tarea elimina todos los estados cada 15 minutos, independientemente de cuando termine el horario, observé que en algunos de esos reinicios, el firewall se cargaba y ya sin remedio cada vez se iba cargando mas gasta que perdía la conectividad, al ser una regla que era una tontería la he quitado y listo todo funcionando como la seda