PfSense: порядок прохождения пакетов
-
Я набросал очень упрощенную схему прохождения пакетов в pfSense, которая, надеюсь, отражает основные моменты, а также позволяет понять некоторые неочевидные вещи. За основу был взят pfflow.png, полную версию которого можно забрать тут: https://www.dropbox.com/s/0hht1fr9vxpa5zm/pfflow.png?dl=0. Я раскрыл блок "KERNEL PROCESSING" и ради упрощения удалил те блоки, которые не влияют на путь пакета, включая states, которые в общем-то не меняют сути, и binat, как частный случай NAT.
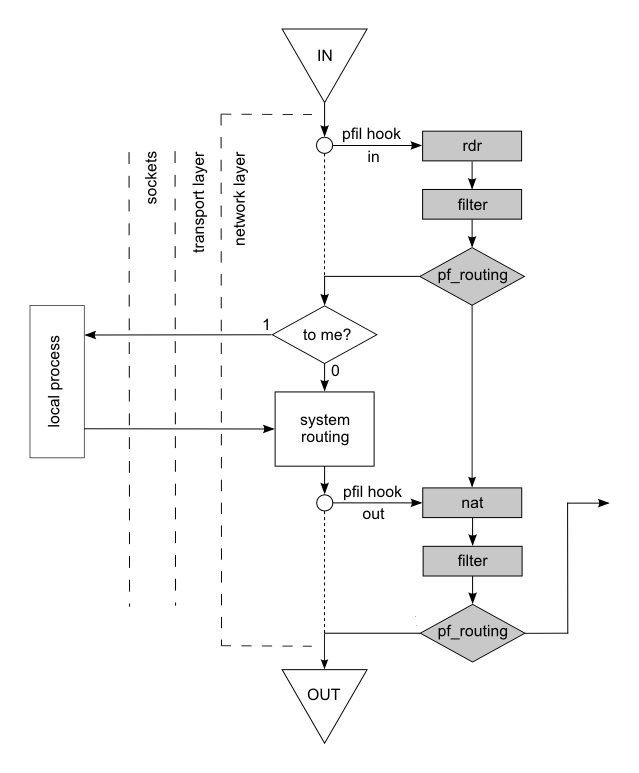
pfSense, как вы знаете, является надстройкой над pf (OpenBSD Packet Filter), а тот в свою очередь - надстройкой над сетевой подсистемой FreeBSD. На схеме блоки относящиеся к этой подсистеме изображены белым, а то, что относится к pf - серым.
pf интегрируется в сетевую подсистему с помощью предоставляемого последней механизма хуков ("hooks" - изображены на схеме маленькими кружками). Этот механизм позволяет сторонней программе добавить в сетевой стек собственную функцию инспекции и модификации пакетов, т.е. работать как фильтр и NAT. При прохождении каждого пакета через точку хука, стек вызывает данную функцию со ссылкой на пакет и, если пакет не проходит заданный функцией фильтр, он уничтожается самой функцией.
Если отключить pf (можно использовать команду 'pfctl -d'), то пакеты пойдут по пути обозначенному мелким пунктиром, минуя все блоки pf, т.е. останется просто сетевая подсистема FreeBSD. В блоке "to me?" система определяет предназначен ли пакет ей самой или какому-то другому хосту. Происходит это следующим образом: если в IP-заголовке адрес назначения совпадает с любым IP-адресом принадлежащим самой системе, то пакет считается предназначенным ей самой. В этом случае пакет поднимается по стеку на транспортный уровень (transport layer), где определяется его порт назначения. Далее происходит поиск сокета (sockets layer) "слушающего" на этом порту, и здесь тоже есть нюанс. Сокет - универсальный интерфейс между пользовательскими программами и сетевой подсистемой, может быть "привязан" (bound) к определенному адресу, принадлежащему системе, а может быть и нет. В последнем случае считается, что сокет "слушает" на всех собственных адресах.
Какой из всего этого следует практический вывод? Если определенный сервис не "привязан" к определенному адресу системы, то сервис доступен на любом из ее адресов. Предположим, что pf включен, и вы из соображений безопасности решили разрешить доступ к веб-интерфейсу pfSense только с компьютера администратора в локальной сети. Наивное правило сетевого фильтра pfSense (Firewall: Rules -> LAN) могло бы выглядеть так:
Block TCP !ADMIN * LAN address HTTPS * none
т.е. запретить соединение по протоколу TCP с любого хоста кроме хоста "ADMIN" и любого порта на LAN-адрес pfSense, на порт HTTPS (веб-интерфейс). При этом, если HTTPS трафик разрешен нижестоящим правилом (а он, как правило, разрешен), то искушенный злоумышленник-инсайдер может легко определить внешний адрес pfSense (WAN address) и прямо из локальной сети открыть в браузере https://pfsense_wan_address и попытаться подобрать пароль. Попробуйте, кстати, у себя.
Пакеты, не предназначенные самой системе, а также исходящие пакеты от локальных процессов попадают в блок "system routing". Основная задача этого блока - определить через какой интерфейс пакет должен покинуть систему, а также определить должен ли пакет быть отправлен непосредственно хосту назначения, или же он должен быть отправлен через внешний маршрутизатор (next hop gateway). Для примера, если pfSense шлет пакет хосту в LAN, то здесь между ними нет посредников. Пакет передается на канальный уровень, где определяется MAC адрес хоста назначения и далее - драйверу интерфейса LAN. С другой стороны, если pfSense отправляет пакет на один из DNS серверов Google, то ясно, что этот сервер не находится в одной физической сети с системой и пакет должен быть отправлен через посредника, т.е. через шлюз провайдера. В этом случае при вызове функции канального уровня ей параметром передается IP шлюза* (все гораздо сложнее, но в дебри мы не полезем) и она определяет уже не MAC адрес Google DNS, чего сделать в принципе не может, а MAC адрес шлюза, куда и отправляется в итоге пакет.
Определение исходящего интерфейса и при необходимости шлюза осуществляется с помощью системной таблицы маршрутов. В pfSense ее можно увидеть через меню Diagnostics -> Routes:
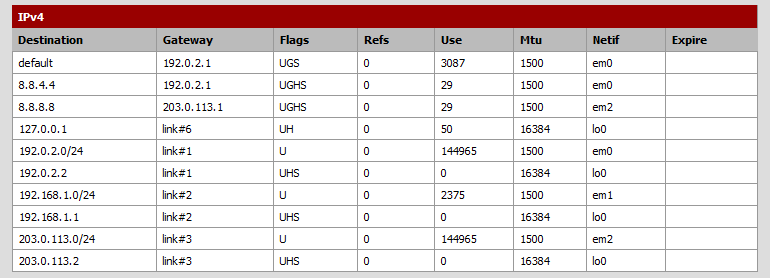
Здесь например локальная сеть 192.168.1.0/24 непосредственно подключена к pfSense через интерфейс em1 (LAN), что видно по столбцу Gateway, где для этого маршрута стоит: link#2 (подключение №2). С другой стороны, в системе есть статический маршрут до DNS сервера Google (8.8.4.4) через посредника - провайдерский шлюз (192.0.2.1) и интерфейс em0 (WAN1) - см. вторую строчку.
Имея такую таблицу, система по IP адресу назначения (Destination) легко определяет интерфейс, через который выйдет пакет, а затем и MAC источника и МАС назначения. В случае, если пакет не транзитный, т. е. исходит от самой системы, по таблице же определяется и какой из собственных IP адресов системы будет использован в качестве IP источника в сетевом заголовке. Мы видим, что есть две строчки link#2. Читается это так: для того чтобы отправить пакет в сеть 192.168.1.0/24, используй собственный адрес 192.168.1.1 и интерфейс em1.
Для обеспечения скорости поиска FreeBSD хранит таблицу маршрутизации в структуре данных называемой radix search trie - префикскном дереве, ключами которого являются биты адреса назанчения (Destination). Это накладывает некоторые ограничения. В таблице не может существовать двух маршрутов с одним и тем же назначением, а, соответственно, и двух маршрутов по умолчанию. Следовательно, не нужны и метрики маршрутов, и их нет. Однако, могут сосуществовать два маршрута одинаковым адресом назначения, но разными масками. Например 192.168.0.0/24 и 192.168.0.0/16. Алгоритм поиска всегда выбирает наиболее конкретный маршрут. Так на рисунке выше есть два маршрута к хосту 8.8.8.8 - default (0.0.0.0/0 - самый общий маршрут в системе) и статический маршрут в третьей строке. Будет выбран второй маршрут т.к. он ведет конкретно к этому хосту (можно сказать что его маска = 32). Таким образом, побеждает всегда наиболее длинная маска при условии, что все биты под маской в Destination совпадают с битами под той же маской адреса хоста, к которому ищется маршрут. Возвращаясь к маршрутам 192.168.0.0/24 и 192.168.0.0/16, понятно, что если мы ищем путь к хосту 192.168.1.1, то первый машрут не подходит, не смотря на более длинную маску. 192.168.0 в Destination не совпадает с 192.168.1 в адресе хоста. Будет выбран второй маршрут.
Это все, что я хотел сказать о сетевой подсистеме FreeBSD. Отмечу только, что в свете предыдущего абзаца FreeBSD, а, соответственно, и pfSense испытывает определенные трудности когда в системе присутствует два и более WAN интерфейсов. Т.е. трафик из LAN с помощью pf вполне можно распределить по разным WAN, но локальные процессы упрямо стремятся отправлять все через default gateway. Надо сказать, что оригинальный pf серьезно модифицируется разработчиками pfSense и например Squid в версиях 2.0 удавалось подружить с Multi WAN путем специального патча к pf.c. Однако, в версии 2.1 опять все сломалось.
Рассмотрим теперь блоки относящиеся к pf. Можно заметить, что три блока расположенных вверху (входная цепочка) подозрительно похожи на нижние три блока (выходная цепочка). Тот же NAT (DNAT вверху и SNAT - внизу), тот же фильтр, тот же роутинг. На самом деле - это одна и та же функция pf_test(), просто одним из параметров она принимает направление пакета - в верхних блоках это PF_IN, а в нижних - PF_OUT. Таким образом, для пакета проходящего через систему функция вызывается два раза - на входе и на выходе. Это существенно сокращает мне работу по описанию того, как работает pf ))
Блок rdr/nat занимается манипуляцией с IP адресами/портам в заголовке пакета. Вверху подменяется IP адрес назначения/порт назначения, т.е. происходит "Port Forward" в терминах pfSense. Внизу подменяется IP адрес источника/порт источника - имеет место "Outbound NAT". Необходимо отметить, что в отличие от большинства аппаратных роуеров класса SOHO в стоковых прошивках, для pfSense понятия WAN и LAN - не более чем условность. Иногда требуется сделать Port Forward или Outbound NAT на LAN интерфейсе и это все работает. В схеме есть только входная цепочка, независимо от интерфейса, к которому она относится, и выходная - также не зависящая от абстракций LAN/WAN. Не вижу смысла расписывать основы работы NAT во всех его проявлениях т.к. топик все же для продвинутого понимания. Укажу только на следующее: как вы видите, после блоков NAT в любом случае следует блок "filter". Таким образом мало пробросить порт или сделать Outbound NAT, необходимо еще и разрешить трафик после NAT в блоке "filter". Это фундаментальное правило имеет одно исключение: если вы пробрасываете порт не куда-то там хосту в LAN, а на один из собственных адресов pfSense, то последующие блоки схемы игнорируются, ни filter, ни pf_routing не имеют места (такой обход не отображен на схеме). Это звучит непривычно, но, тем не менее, pf действительно позволяет пробросить порт с входного интерфейса на один из собственных адресов системы (какая в сущности разница? это всего лишь IP адрес). Типичный случай - SQUID в прозрачном режиме. Когда вы "привязываете" (не путать с bind) SQUID к LAN интерфейсу, в системе создается скрытое правило pf:
rdr on em1 inet proto tcp from any to ! (em1) port = http -> 127.0.0.1 port 3128
т.е. перенаправить TCP трафик с портом назначения = HTTP входящий на LAN интерфейс и не предназначенный самому LAN интерфейсу на адрес 127.0.0.1 (loopback) и порт 3128 (SQUID). Этот трафик невозможно отфильтровать правилами сетевого экрана. Другой пример: в ситуации, когда у вас несколько WAN интерфейсов, вы можете завести несколько экземпляров OpenVPN серверов для каждого из интерфейсов, а можно привязать (bind) один экземпляр к LAN интерфейсу и просто пробросить порт 1194 c каждого из WAN на IP LAN. Это непривычно для владельцев SOHO роутеров, но абсолютно законно в pfSense, однако, фильтровать клиентов по их IP вы уже не сможете. Причем ни на WAN, ни на LAN, куда вы пробросили порт. На WAN фильтр обходится by design, а во входную цепочку LAN трафик просто не попадает потому, что это и невозможно, да и не нужно, ибо трафик предназначен самой системе и он "уже здесь".
В контексте описания путей прохождения пакетов через pfSense о блоке "filter" сказать особо нечего, кроме того, что в его правилах можно явно указать gateway (Policy Routing) и в этом случае блок pf_routing осуществит маршрутизацию самостоятельно, минуя системную таблицу маршрутов (блок "system routing"). На схеме это соответствует стрелке вниз от pf_routing входной цепочки к блоку nat выходной цепочки. Таким образом, если в pfSense вы настроили policy routing (например failover или балансировку каналов при нескольких WAN), но при этом хотите чтобы некоторый трафик подчинялся системной таблице маршрутов (например трафик между двумя LAN), то правило для этого трафика должно стоять выше правила с policy routing. Например:
* LAN1 subnet * LAN2 subnet * * none
* LAN1 subnet * * * WAN1FailsToWAN2 none- трафик из подсети LAN1 в подсеть LAN2 будет маршрутизироваться сетевой подсистемой FreeBSD, а остальной трафик (интернет) - блоком pf_routing pf. Если не создать верхнее правило, то трафик из LAN1 в LAN2 пойдет через WAN1FailsToWAN2, т.е. провайдерам, где и будет отброшен.
Где-то выше я уже писал, что в точках хуков вызывается одна и та же функция pf - pf_test с параметром направления пакета - PF_IN/PF_OUT. В этом смысле может показаться непонятной стрелка вниз от pf_routing входной цепочки к блоку nat выходной цепочки. Как же так? Ведь это разные вызовы функции в разных контекстах. Какая между ними может быть связь? Могу только сказать, что схема - это логический путь пакетов. На уровне вызовов все выглядит примерно так:
- pf добавляет два хука: pf_check_in() - входной хук и pf_check_out() - выходной.
- pf_check_in() вызывает pf_test(PF_IN, …), а pf_check_out() - pf_test(PF_OUT, ...)
- во входной цепочке pf_test() делает NAT, Filter и, в случае успеха последнего - pf_routing()
- pf_routing() знает правило Filter, которое привело пакет к нему.
- если в этом правиле указан gateway, то pf_routing() самостоятельно определяет выходной интерфейс пакета, вызывает pf_test(PF_OUT, oifp...) для этого интерфейса, т.е. проверяет проходит ли пакет выходной фильтр интерфейса и, в случае успеха самостоятельно выводит пакет на канальный уровень, вызывая if_output() - выходная цепочка заканчивается стрелкой pf_routing -> OUT.
-
Еще раз. Необходимо понимать, что в этом случае pf_test(PF_OUT, …) вызвана не хуком на выходе из системы, а из pf_routing() во входной цепочке (в этом весь смысл стрелки на схеме).
В выходной цепочке мы также можем создавать правила Filter (Floating Rules, direction = out, quick = yes) и указывать в них gateway. Если gateway не указан, то pf_routing() не вызавается из pf_test(PF_OUT, ...), т.е. пакет передается в блок OUT также как и в предыдущем случае. Если же в правиле Filter выходной цепочки указан альтернативный gateway, то все происходит как в последовательности действий приведенной выше, начиная с пункта 5. На схеме это отображено стрелкой ведущей из нижнего блока pf_routing в никуда (фактически пакет уходит в блок NAT выходной цепочки другого интерфейса).
По сути при определенных обстоятельствах мы имели бы дело с бесконечной рекурсией: pf_test() -> pf_routing() -> pf_test() ... если бы такие блуждания пакета не были ограниченны специальным счетчиком. Не случайно в оригинальном pfflow.png эта стрелка снабжена надписью "one time rerouting"* (см. ниже). Заплутавший пакет просто уничтожается.
Псевдокод функций:
01 pf_test(направление, интрефейс, *пакет) 02 { 03 NAT; 04 05 правило = найти_правило_фильтра(направление, интрефейс, пакет); 06 07 если (правило.шлюз != NULL) 08 pf_route(пакет, правило, интерфейс); 09 10 вернуть правило.действие; 11 }01 pf_route(*пакет, правило, интерфейс) 02 { 03 если (пакет->сечтчик_машрутизации > 3) 04 { 05 пакет = NULL; 06 выход; 07 } 08 пакет->сечтчик_машрутизации = пакет->сечтчик_машрутизации + 1; 09 10 выходной_интерфейс = найти_выходной_интерфейс(правило.шлюз); 11 12 если (интерфейс != выходной_интерфейс) 13 { 14 если (pf_test(PF_OUT, выходной_интерфейс, пакет) != PF_PASS) 15 { 16 пакет = NULL; 17 выход; 18 } 19 иначе если (пакет == NULL) 20 выход; 21 } 22 23 if_output(выходной_интерфейс, пакет); 24 пакет = NULL; 25 }Как мы видим, рекурсия ограничена не только счетчиком перемаршрутизаций, но и тем, что вызовы pf_route из pf_test и pf_test из pf_route не безусловны, т.е. происходят не всегда. Первый, как уже говорилось, не происходит если в правиле фильтра не указан gateway, а второй - если пакет уже выходит через правильный интрефейс. pf_route принимает параметр 'интрефейс' - интерфейс, на котором пакет был "пойман" правилом фильтра, затем по значению gateway правила определяет интрефейс, через который пакет должен покинуть систему - 'выходной_интерфейс'. Если интерфейсы не совпадают, то происходит вызов pf_test для выходного интерфейса (строка 14). Если пакет не пропускается выходным интерфейсом - пакет уничтожается (строка 16). Иначе (в строке 19) происходит проверка на существование пакета - дело ведь в том, что вызов pf_test для выходного интерфейса может повлечь за собой вызов pf_route, если на выходном интерфейсе есть правило с gateway (policy routing), и пакет может успешно покинуть систему в вызываемом pf_route (строка 23), а его ссылка на него очищена (строка 24). В этом случае вызывающему pf_route делать уже ничего не нужно и происходит выход (строка 20).
Реальное предельное значение для количества перемаршрутизаций пакета внутри системы почему-то - 4 (строка 03). Надо полагать, что либо оригинальный pfflow.png уже сильно устарел, либо этот счетчик увеличивается где-то еще, да и вообще не понятно как он инициализируется.
Литература:
FreeBSD: архитектура и реализация. Маршалл Кирк МакКузик, Джордж В. Невилл-Нил. КУДИЦ-ОБРАЗ, Москва 2006.
pf source - оригинальные и патченные под pfSense. Кстати могу выложить, если кому-то надо. В открытом доступе последние вы вряд ли уже увидите, ибо после того как некто собрал на их основе свой образ pfSense 2.2 и выложил ссылку на него на форум, "Electric Sheep Fencing" решила, что нарушены ее права на имя pfSense и удалила патчи из репозитария. Теперь нужно подписать лицензионное соглашение разработчика, чтобы иметь к ним доступ. Что дальше будет - не понятно, все в процессе.
pfSense: The Definitive Guide Version 2.1 (draft). Christopher M. Buechler, Jim Pingle - есть и такая книжка, хотя не законченная и взял я из нее немного. У нас в шапке болтается тема: "Благодарность разработчикам PfSense от нас с вами". Если есть желание отблагодарить, то по цене двух походов в макдачную еще и книгу получите: https://portal.pfsense.org/gold-subscription.php))
-
В блоке "to me?" система определяет предназначен ли пакет ей самой или какому-то другому хосту. Происходит это следующим образом: если в IP-заголовке адрес назначения совпадает с любым IP-адресом принадлежащим самой системе, то пакет считается предназначенным ей самой.
По научному это, кстати, называется "Weak End System Model" и характерна она не только для FreeBSD, а и для других систем, работающих в качестве маршрутизаторов. В этой модели IP адресует хост в отличие от "Strong End System Model", где IP адресует интерфейс. Поэтому в первом случае системе все-равно на какой интерфейс пришел трафик, если он предназначен одному из принадлежащих ей IP (т.е. самому хосту), а во втором IP назначения должен строго совпадать с IP входного интерфейса, в потивном случае трафик будет отброшен.
Посмотреть как "Weak End System Model" эксплуатируется хакерами можно в этом видео:
https://www.youtube.com/watch?v=r13ESXEfQVE
Оцените спектр подверженных атаке устройств. pfSense - одна из систем, где разработчики приняли меры против DNS rebinding attack и в ней это не работает, что не отменяет необходимости запретить доступ ко всем IP pFsense из всех подключенных к ней сетей, если вы хотите ограничить доступ к веб-интерфейсу пользователям.
-
Это фундаментальное правило имеет одно исключение: если вы пробрасываете порт не куда-то там хосту в LAN, а на один из собственных адресов pfSense, то последующие блоки схемы игнорируются, ни filter, ни pf_routing не имеют места
…
Этот трафик невозможно отфильтровать правилами сетевого экрана.Вот это кстати - чепуха, результат неверного эксперимента. Есть и другие ошибки помельче.
На неделе сделаю другую, исправленную и дополненную версию статьи. -
Это фундаментальное правило имеет одно исключение: если вы пробрасываете порт не куда-то там хосту в LAN, а на один из собственных адресов pfSense, то последующие блоки схемы игнорируются, ни filter, ни pf_routing не имеют места
…
Этот трафик невозможно отфильтровать правилами сетевого экрана.Вот это кстати - чепуха, результат неверного эксперимента. Есть и другие ошибки помельче.
На неделе сделаю другую, исправленную и дополненную версию статьи.очень бы хотелось почитать…
Также вопрос по поводу интерфейсных групп, пользуете ли, какова специфика, если да? -
очень бы хотелось почитать…
Что касается зачеркнутого, более подробно в конце этого поста: http://pfsensible.blogspot.ru/2014/04/blog-post.html
Ну и вообще, я в этот блог складываю всякое, что большинству не нужно. Здесь же писать не планирую, т. к. это будет просто кавардак из примечаний к первым двум постам.
В целом в них все верно.Также вопрос по поводу интерфейсных групп, пользуете ли, какова специфика, если да?
Сделайте тему на форуме. Сам не использую, на память, специфика в том, что сначала обрабатываются Floating rules, затем Interface group rules, затем Interface rules.
-
Выложите плиз картинку pfflow.png для наглядности, по ссылке ее нету
-
поправил
-
Большое спасибо за пост!