Debug Kernel Build with Witness
-
Well @jimp It's been 17 days... 9 days ago I had it lock up, got nothing out of CTRL+T, and no panic/dump, so I just rebooted it and updated to the latest snapshot. It's been running fine for
9 Days 20 Hours 54 Minutes 26 Secondsso... /shrug, maybe someone fixed something betweenpfSense-kernel-debug-pfSense-SG-3100-2.5.0.a.20200808.0050andpfSense-kernel-debug-pfSense-SG-3100-2.5.0.a.20200817.1850(the one I'm running now).At any rate, I figured you were quite anxious to hear what was happening with this so thought I'd fill you in. Thanks again for putting up with us (us: the ungrateful community)!
EDIT: I swear, within 5 minutes posting that it locked up. I'm really wondering now if it has something to do with me logging in to through ssh and/or the web portal. I was able to issue a few commands (tcpdump, no packets, ps, dmesg, checked some logs...nothing interesting), but as soon as I ran a
netstat, the console locked up also. -
Ah hah! @jimp
Everything on the "pf rules(et?)" Wait Chain is waiting on a Lock. That appears to be ...
sys/netpfil/pf/pf_ioctl.c:
struct rmlock pf_rules_lock;
rm_init(&pf_rules_lock, "pf rulesets");sys/net/pfvar.h:
extern struct rmlock pf_rules_lock;
#define PF_RULES_RLOCK() rm_rlock(&pf_rules_lock, &_pf_rules_tracker)
#define PF_RULES_RUNLOCK() rm_runlock(&pf_rules_lock, &_pf_rules_tracker)...which gets called many times throughout
pf, in particular the ioctl handler/sys/netpfil/pf/pf_ioctl.c... If I'm a betting man, it's inpf purgeorng_queue(the two kernel procs with pages locked in core). Buuttt... most likely with in netgraph (I'm using the AT&T bypass).I've stripped down this
ps -ax1O flags,flags2to just the relevant (STAT L*) entries.UID PID PPID C PRI NI VSZ RSS MWCHAN STAT TT TIME COMMAND PID F F2 0 0 0 1 -16 0 0 112 swapin DLs - 0:00.62 [kernel] 0 10000284 00000000 0 1 0 0 20 0 3280 768 wait ILs - 0:00.05 /sbin/init -- 1 10004200 00000000 0 8 0 0 -16 0 0 8 pf rules LL - 0:00.37 [pf purge] 8 10000204 00000000 0 12 0 1 -92 0 0 16 pf rules LL - 0:39.99 [ng_queue] 12 10000284 00000000 65534 4229 3258 1 42 20 4416 2040 pf rules LNs - 0:00.02 /usr/local/sbin/ 4229 10004100 00000000 -- /usr/local/sbin/expiretable -v -t 0 8994 8958 1 20 0 21652 7352 pf rules L - 0:00.23 nginx: worker pr 8994 10000100 00000000 100 19467 1 0 20 0 71260 29648 pf rules L - 1:09.85 (squid-1) --kid 19467 10004100 00000000 0 38115 1 1 72 0 4736 2420 pf rules L - 0:00.01 /sbin/pfctl -e 38115 10004000 00000000 0 57945 1 1 20 0 9556 6004 pf rules Ls - 0:00.09 /usr/local/sbin/ 57945 10000080 00000000 0 76017 76011 0 -92 0 4804 2452 pf rules L - 0:00.01 /sbin/pfctl -vvP 76017 10004000 00000000 0 77566 77277 0 40 20 4736 2420 pf rules LN - 0:00.00 /sbin/pfctl -vvs 77566 10004000 00000000 0 77617 12439 0 20 0 4460 2120 pf rules LC - 0:00.00 /sbin/ping -t2 - 77617 10004000 00000000 0 78292 13859 0 20 0 12140 7224 pf rules Ls - 0:00.13 sshd: root (sshd 78292 10004100 00000000 0 55147 55120 1 93 20 4736 2420 pf rules LN u0 0:00.00 /sbin/pfctl -vvs 55147 10004002 00000000 0 77870 60115 1 20 0 5044 2588 - R+ u0 0:00.01 ps -axlO flags,f 77870 10004002 00000000 0 80126 73786 1 20 0 4932 2592 wait I u0 0:00.02 /bin/sh /etc/rc. 80126 10004002 00000000 ``` -
Well, after much frustration, here's my final findings before I switch back to 2.4.5.
There is a kernel memory leak, that is overwriting the priority tracker for the pf_rules_lock, which is causing the kernel to enter a deadlock, since it can't release the mutex(rmlock).
Here's some information if anyone else cares to try to figure out what is actually causing the memory leak.
https://github.com/pfsense/FreeBSD-src/blob/devel-12/sys/netpfil/pf/pf_ioctl.c rm_init(&pf_rules_lock, "pf rulesets"); -> This allocates a lock_object at 0xc1c77e78, as evidenced by the below kgdb, it is a static symbol (always at that address) (kgdb) print &pf_rules_lock $1 = (struct rmlock *) 0xc1c77e78 <pf_rules_lock> (kgdb) ptype pf_rules_lock type = struct rmlock { struct lock_object lock_object; volatile cpuset_t rm_writecpus; struct { struct rm_priotracker *lh_first; } rm_activeReaders; union { struct lock_object _rm_wlock_object; struct mtx _rm_lock_mtx; struct sx _rm_lock_sx; } _rm_lock; } (kgdb) ptype struct lock_object type = struct lock_object { const char *lo_name; u_int lo_flags; u_int lo_data; witness *lo_witness; }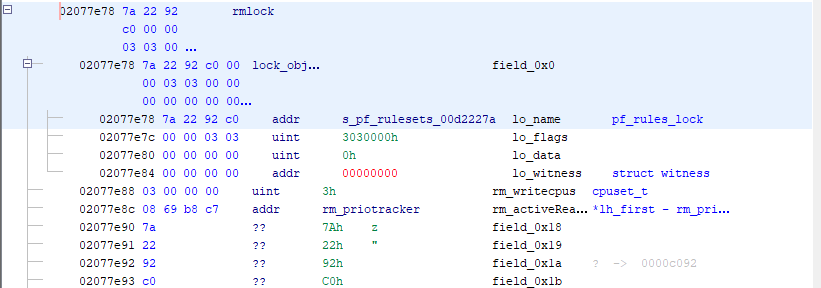

Note: This is from a vmcore dump, kernel memory virtual addresses (0xc0000000) are mapped to physical addresses at 0x00400000.
From the Ghidra image above, you can see where the lock object is allocated in memory and that it is populated with data (I didn't build out the full struct, only the parts I cared about). The lo_name correctly maps to the "pf_ruleset" string, but following the rm_priotracker, you can see the memory is corrupted. Those values don't match to what should be in the struct. Upon further investigation, that "spray" of data starts around 0x7f560000 and goes to 0x80000000 (0xAA000 bytes of data), it's a repeating pattern of 4 bytes + 0x00000100 (LE), but the values change periodically to a pattern I couldn't figure out.
I did a factory reset and re-installed my packages to let it run for a while, just to see... but no luck, it still locks up (same section of memory gets overwritten with garbage).
So, now I'm in the process of re-installing 2.4.5 on my SG-3100. Good luck to anyone else who attempts this.
-
Hi, it's hard to make any conclusions based on the debugger output, but if you are willing to try and reproduce the issue again, "procstat -kka" output would be most useful. It dumps the stacks of all blocked threads in the system. (I'm not 100% sure that it is reliable on that platform so it'd be worth checking that it gives sane-looking output before spending much time on it.)
I don't really understand your assertion that the fields following rm_priotracker are corrupted. The following four bytes are a pointer which represent the lo_name field of the lock object in the union following rm_priotracker, and I can't see anything further than that in the posted memory dump.
-
While testing, I tried
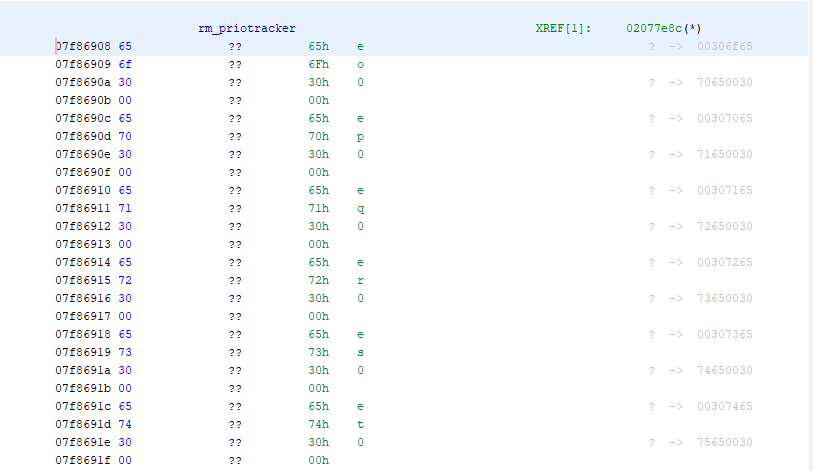
procstat, but it locked up my console. I'm assuming it tried to crawl the process structure and came across one of the dead locked processes?Let me explain the dump a bit more. In the top image the rm_priotracker pointer (which is actually called rm_activeReaders) is at offset 0x02077e8c (which would be vmem address 0xc1c77e8c, or pf_rules_lock+0x14). It's value is 0xc7b86908 (virtual), which maps to a physical address of 0x07f86908, which I've shown in the last image.
The first value of the rm_priotracker is actually
a pointer toa queuerm_queue rmp_cpuQueue, whose first value is a pointer, so this should have a pointer in it.(kgdb) ptype struct rm_priotracker type = struct rm_priotracker { rm_queue rmp_cpuQueue; rmlock *rmp_rmlock; thread *rmp_thread; int rmp_flags; struct { rm_priotracker *le_next; rm_priotracker **le_prev; } rmp_qentry; } (kgdb) ptype struct rm_queue type = struct rm_queue { rm_queue * volatile rmq_next; rm_queue * volatile rmq_prev; }So the value in the dump at 0x07f86908 should be a pointer to an rm_queue struct (which is a queue/linked list), however, 0x00306f65 is not a valid memory location (not in kernel memory anyway). When I checked this value on a live system (reading /dev/kmem), it mapped to a valid 0xc* address.
-
It's possible that one of the deadlocked threads held a lock required by procstat. If you're able to run kgdb against a vmcore you should be able to get backtraces with "thread apply all bt".
Why do you say that 0xc7b86908 maps linearly to physaddr 0x07f86908? ARM kernels do not use a direct map. Indeed, the base of the kernel map is 0xc0000000 but kernel virtual memory is allocated dynamically once the page table code is bootstrapped. Maybe I'm missing something - did you resolve the address using the kernel page tables?
-
Sorry, guess I should also have posted that!
I got the physical offset using readelf on the vmcore. Considering the information below, and the fact the pf_rules_lock->lo_name actually pointed to the string "pf rulesets" (that middle image, physical address 0x00d2227a maps to virtual 0x0c92227a), I figured it was accurate.
readelf --segments vmcore.0 Elf file type is CORE (Core file) Entry point 0x0 There are 2 program headers, starting at offset 52 Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align LOAD 0x001000 0x00001000 0x00001000 0x7ffff000 0x7ffff000 R 0x1000 LOOS+0xfb5d000 0x000000 0xc0000000 0x00400000 0x00000 0x00000 R 0x1000Edit, quick little python snippet I've been using (its not perfect, but should map the kernel offsets):
po = 0x00400000 vo = 0xc0000000 def p_to_v(paddr): return hex(paddr - po + vo) def v_to_p(vaddr): return hex(po + (vaddr - vo)) >>> p_to_v(0x00d2227a) '0xc092227a'Edit2:
Lastly, kgdb could not read the vmcore. It kept saying:Failed to open vmcore: cannot read l1ptMy assumption there (since my expertise is not in ARM) is that the "l1pt" (table?) was corrupted.
Edit3:
Really lastly, while I'm not willing to share the full vmcore, if you (or someone else) is really interested in figuring this out, shoot me a private message and I can carve out data from the vmcore if you have some offsets you want to look at. -
What I mean is that in general you cannot translate kernel virtual addresses by subtracting 0xc0000000. Lock names are strings embedded into the kernel, and the kernel image itself is indeed mapped linearly. However, rm lock priotrackers are allocated from kernel stacks, which are allocated and mapped dynamically.
Indeed, it sounds like the vmcore is corrupted or somehow unrecognized. l1pt is the root of the kernel page tables, needed to translate virtual addresses.
Are you able to break into the in-kernel debugger from the console? That might be another way to get info about the offending code if you are able to reproduce the problem. I'm much more familiar with FreeBSD than pfSense, so I'm not sure whether a debugger is included in the kernel configuration.
-
Right, which is why I used the PhysAddr/VirtAddr from the segments information in the vmcore to do the mapping (So <virtual address> - 0xc0000000 + 0x00400000 gets me the physical address).
I see what you are saying though about the rm_lock being allocated on the kernel stacks; however, everytime I run
(kgdb) print &pf_rules_lockagainst that kernel, it always returns0xc1c77e78. On my 2.4.5p1 build, when I run it I always get0xc1a3e2d4.As far as a debugger, I only just noticed (as I went to check)
/usr/lib/debug/boot/kernel/kernel.debug, which I was originally using for debug symbols, but now I realize I wasn't booting from that one, heh. That one of course has witness support (like jimp told me, but I was too thick skulled to realize I wasn't booting the correct kernel, smh), and also appears to have remote kgdb support.Alright, well If I get some more time, I'll try actually booting that kernel and see what I can find, but for now I need my SG-3100 to be stable.
-
-
@luckman212 Yeah, I used Ghidra to analyze the vmcore (kernel dump). I'm more familiar with IDA, but I chose this project to try my hand at learning Ghidra. I'm rather impressed by its functionality, but the scripting interface leaves something to be desired; can't beat the price though.
As for where to start to learn...that's a large question, but like most things, I start with a problem. Find some project that requires reverse engineering or debugging, and learn Ghidra as you go. If you're having trouble finding something, head over to hackthebox and check out their RE challenges.
If you are interested primarily in reverse engineering (or learning the deep internals of operating systems), I would recommend "The Rootkit Arsenal: Escape and Evasion in the Dark Corners of the System (2nd Edition)" (ISBN-13: 978-1449626365). Chapters 3 and 4 offer an excellent overview of hardware and system design. It focuses mainly (exclusively?) on x86/x86_64 and Windows, but the foundational knowledge is pretty solid IMO. I've got a copy of "Reversing: Secrets of Reverse Engineering" (ISBN-13: 978-0764574818), but honestly I found "The Rootkit Arsenal" more useful...check them both out if you can and see which you like.
Now, I tackled this from an RE perspective because that's where my knowledge lies, but there are probably other ways that the more seasoned FreeBSD dev's have of doing this. (I have a hammer, so everything is a nail)
As a side note, I had to use Ghidra because the vmcore was corrupted by the memory leak...otherwise I would have just used kgdb to crawl the vmcore. Also, I'm rather annoyed that I was never able to find the source of the problem. It now appears that others may be experiencing something similar with the official release of 2.5.0.
-
I had to troubleshoot some SG-3100 issues a couple of years ago, and now I have to do it again, with the Snort and Suricata packages crashing only on ARM 32-bit hardware.
For what it's worth, I think the llvm compiler for the ARM hardware (and maybe just the 32-bit ARM hardware) has some issues of its own that lend to it generating faulty machine code. Note that this issue with freezing seems to impact the SG-3100 hardware, which is a 32-bit ARM CPU, but not x86-64 hardware. But the actual C source code for FreeBSD is the same.
-
@bmeeks Yeah, its odd. It looks like FreeBSD devs are aware, if not quite how to fix it completely: https://reviews.freebsd.org/D28821
-
@torred said in Debug Kernel Build with Witness:
@bmeeks Yeah, its odd. It looks like FreeBSD devs are aware, if not quite how to fix it completely: https://reviews.freebsd.org/D28821
Yep. They had a long conversation about the solution. They settled on a memory barrier approach. I think the compiler is a little too aggressive with its optimizations. That was the issue with Snort a couple of years ago. The compiler was choosing the ONLY two instructions in the armv7 chip that did not do auto-fixup of non-aligned memory access. Snort's C source code has a number of those problems, but on Intel hardware the CPUs have always done an automatic fix-up at runtime and thus have hidden the bad code so that it persists.
-
@torred Great stuff. Thank you for taking the time for such a detailed reply. I am going to see if I can wrap my head around some of this.
-
It can be fun if you are into such things. In my younger days I did this with embedded systems things. Many of those used Intel or Texas Instruments embedded microprocessors with the code in EPROM. Dump the EPROM using a reader, start at the power-on reset vector in the EPROM code for the CPU and start disassembling the binary. I often wrote my own disassemblers using the datasheets from the CPU manufacturers to get the binary opcodes and their assembler mnemonics so I could properly code the disassembler.
I did it to satisfy my curiosity and not for nefarious purposes. Mostly just to see if I could do it. My wife did question my sanity at times when she found me poring over a stack of paper from a dot-matrix printer composed of pages of assembly code. I would be writing in comments as I figured out what a section of code was likely doing.
Luckily I recovered ...
 , and no longer suffer from that yearning.
, and no longer suffer from that yearning.