Playing with fq_codel in 2.4
-
I've been following this thread for a couple of weeks now but I'm still running into an issue.
If I have an in and out limiter set on the WAN interface, using the exact steps @jimp lays out in the August 2018 hangout, I get packet loss. If I stress the connection using a client visiting dslreports.com/speedtest to create load and I run a constant ping to my WAN_DHCP gateway, I have seconds of echo response loss while the test runs. DSLreports shows overall A, bufferbloat A, quality A. If I move the limiters to the LAN interface, making the needed interface and in/out queue adjustments to the floating rules, I do not see loss and DSLreports shows the same AAA result.
Can anyone else recreate this? My circuit is rated at 50Mbps down and 10Mbps up and I am limiting at 49000Kbps and 9800Kbps respectively after finding this to consistently work well in the past with ALTQ and CODEL on WAN. I am running 2.4.4 CE.
-
You should see some loss, (that's the whole point), but ping should lose very few packets. Are you saying ping is dying for many seconds? or just dropping a couple not in a bunch? It's helpful to look at your retransmits on your dslreports test, and ping itself, dropping packets. what do you mean by a "constant ping". A ping -f test (flooding) WILL drop a ton of ping packets but a normal ping should drop, oh, maybe 3%?
Part of why I'd like to run flent is I can measure all that. :)
-
@dtaht thanks for the quick response. I am pinging every 500 ms during the dslreports test with a timeout of 400ms for the response - typical latency between my WAN interface and gateway is less than 3 ms. Over the coarse of the entire test, download and upload, including the pauses, I see the following.
Packets: sent=86, rcvd=62, error=0, lost=24 (27.9% loss) in 42.513662 sec
RTTs in ms: min/avg/max/dev: 1.042 / 3.546 / 11.348 / 1.575
Bandwidth in kbytes/sec: sent=0.121, rcvd=0.087I'll take a look at flent and see what I can gather.
-
@dtaht I'm happy to expand on it. I understand what you would expect from a "burp" at the start of the test, and I did sometimes see circa ~30-40ms of latency at that time, but I never saw (or heard in the case of my Sonos streaming radio) any drops at the start of the test (or anywhere during the download test), only at the end of the upload test exactly when the graph dove down from it's "hump" it was drawing. I did try it about 6-7 times and it was repeatable whereby the internet radio would pause for a good 5 seconds and you'd be chucked out of any RDP session to an internet host at that specific time. Changed the quantum only down to 300 from 1514 and it made the difference that no connections were dropped despite another 7 or so tests today with everyone in the office working at the time and the Sonos playing. It was repeatable, so despite you saying it shouldn't help it appears however that it did.
-
@dtaht Ok, here is what I have set up to test my issue using spare hardware. I've confirmed what I was seeing with other hardware using a different topology and using Flent to produce the traffic. The limiters are 49000Kbps and 9800Kbps.
The test lab is laid out as such - all network connections are copper GigE.
flentuser@netperf2:~/flent$ flent rrul -p all_scaled -l 60 -H 172.16.21.76 -t UptownVagrant -o RRUL_Test001.pngI have included the graph created by Flent as well as attached the pfsense configuration (very close to stock) and the gzip output from Flent. During the RRUL test I was pinging the WAN-DHCP gateway every 500 ms with 60 bytes and a reply timeout of 400 ms for each echo request from the Thinkpad using hrping. I'm seeing huge loss when simulating this tiny traffic while Flent RRUL is running.
Packets: sent=146, rcvd=26, error=0, lost=120 (82.1% loss) in 72.500948 sec RTTs in ms: min/avg/max/dev: 0.538 / 1.004 / 1.865 / 0.340 Bandwidth in kbytes/sec: sent=0.120, rcvd=0.021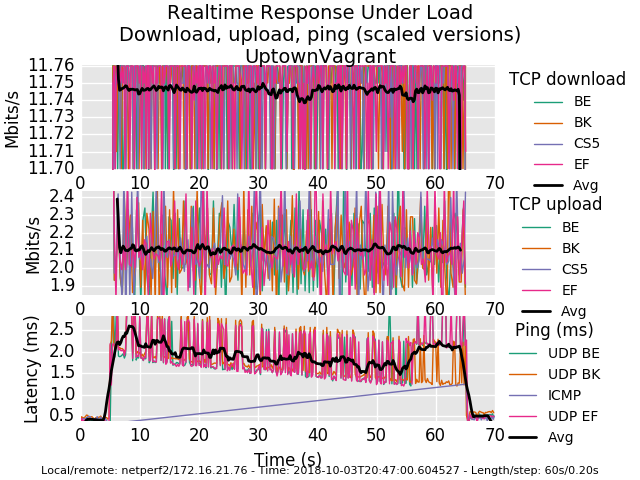
0_1538625522209_config-pfSense.localdomain-20181003200505.xml
0_1538625551026_rrul-2018-10-03T204700.604527.UptownVagrant.flent.gz
-
Beautiful work, thank you. You're dropping a ton of ping . That's it. Everything else is just groovy. It's not possible to drop that much ping normally on this workload. Are icmp packets included in your filter by default? (udp/tcp/icmp/arp - basically all protocols you just want "in there", no special cases). udp is gettin through.
You can see a bit less detail with the "all" rather than the all_scaled plot.
Other than ping it's an utterly perfect fq_codel graph. way to go!
-
while you are here, care to try 500mbit and 900mbit symmetric? :) What's the cpu in the pfsense box? Thx so much for the flent.gz files, you really lost a ton of ping for no obvious reason. Looking at the xml file I don't see anything that does anything but tcp... and we want all protocols to go through the limiter.
For example a common mistake in the linux world looks like this
tc filter add dev $DEV parent ffff: protocol ip prio 50 u32 match ip src
0.0.0.0/0 more stuffwhich doesn't match arp or ipv6. The righter line is:
tc filter add dev ${DEV} parent ffff: protocol all match u32 0 0
-
also, you can run that test for 5 minutes. -l 300. IF you are also blocking arp,
you'll go boom in 2-3 minutes tops.this is btw, one of those things that make me nuts about web testers - we've optimized the internet to "speedtest", which runs for 20 seconds. Who cares if the network explodes at T+21 and if my users could stand it, I'd double the length of the flent test to 2 minutes precisely because of the arp blocking problem I've seen elsewhere.....
I run tests for 20 minutes... (ping can't run for longer than that on linux)... hours.... with irtt.... overnight....
-
@dtaht Thanks again for your quick responses - I really appreciate your guidance on this.
The floating match filter rules I have, one for WAN out and one for WAN in, are for IPv4 and all protocols so everything should be caught and processed by fq_codel limiter queues. The match rules that place the traffic in the queues start at line 178 of the xml file I attached previously.
The CPU is an Intel Atom C2758 in the pfSense box. Below I've uploaded the graphs and flent.gz files for 500Mbit and 900Mbit - I ran each test for 5 minutes.

0_1538634767921_rrul-2018-10-03T231012.058529.UptownVagrant_C2758_pfSense2_4_4_500Mbit.flent.gz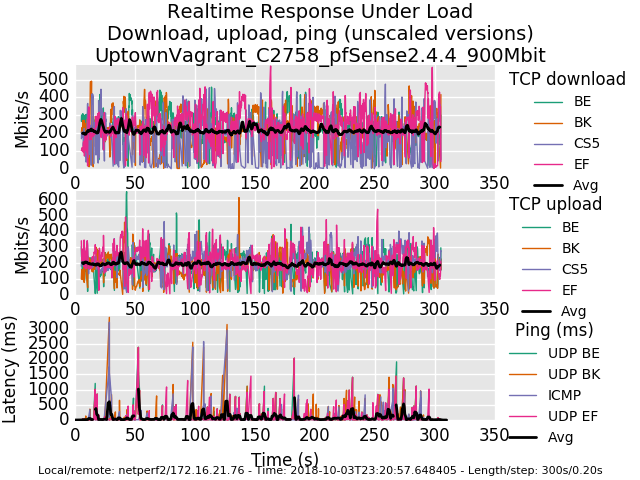
0_1538634784575_rrul-2018-10-03T232057.648405.UptownVagrant_C2758_pfSense2_4_4_900Mbit.flent.gz
-
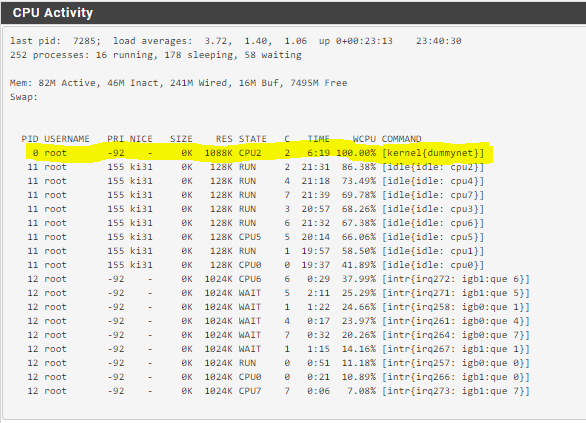
At 900Mbit a core is saturated on this C2758 by dummynet limiter.
-
This post is deleted! -
@strangegopher a floating match rule for your LAN interface should also do the trick - it works in my experience. That being said I'm also seeing strange behavior with ICMP and limiters applied to WAN when NAT is involved. I plan to test without NAT later today to see if the behavior changes. I believe I remember reading there were issues with limiters and NAT in the past but I thought they were remedied at this point.
-
@uptownVagrant yeah that works too, for me I have only 2 interface groups (guest vlans (3 of them) and lan vlans (2 of them)) so its not hard to apply the rules.
-
I followed jimp video on netgate monthly hangout, on a single wan setup. fq_codel works. but on my case I have dual wan. I have seperate rule for my two wan. If I enable the fq_codel firewall rule. my internet gets crappy.
00001: 24.000 Mbit/s 0 ms burst 0 q65537 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail sched 1 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 100fs quantum 1514 limit 10240 flows 1024 ECN Children flowsets: 1 00002: 764.000 Kbit/s 0 ms burst 0 q65538 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail sched 2 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 100fs quantum 1514 limit 10240 flows 1024 ECN Children flowsets: 2 00003: 12.228 Mbit/s 0 ms burst 0 q65539 50 sl. 0 flows (1 buckets) sched 3 weight 0 lmax 0 pri 0 droptail sched 3 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 100fs quantum 1514 limit 10240 flows 1024 ECN Children flowsets: 3 00004: 764.000 Kbit/s 0 ms burst 0 q65540 50 sl. 0 flows (1 buckets) sched 4 weight 0 lmax 0 pri 0 droptail sched 4 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 100fs quantum 1514 limit 10240 flows 1024 ECN Children flowsets: 4 ```! -
@strangegopher said in Playing with fq_codel in 2.4:
- For those experiencing traceroute issues, the fix is to not have a floating rule. Instead add pipes to your lan interface rule to the internet.
So is it safe to say this wouldn't work properly for multiwan setups? If WAN1=1000Mbit and WAN2=50Mbit (e.g.) then piping them both thru the same limiter seems like it would never achieve the correct results.
-
@luckman212 you can create 2 identical rules out to the internet in lan, one for wan1 and other for wan2. But make sure to select the wan interface (gateway) in advanced settings to be wan1 for first rule and wan2 for second rule.
-
@uptownvagrant from the xml file (thx for the guidance) you are running with the default quantum of 1514. Can you retry with 300 to see if the ping problem still exists?
I note that quantum should generally match the mtu - 1518 if you are vlan tagging - and yes, below 40mbit or so, 300 has been a good idea.
The other thing I can think of is adding an explicit match rule for icmp as a test.
The other other thing I notice is the slope changes a bit and the height of the graph is ~3ms on the 500Mbit test rather than about 2ms. This implies there's a great deal of
buffering on the rx side of the routing box, and your interrupt rate could be set higher to service less packets more often.Lastly, while you are here, if you enable ecn on the linux client and server also
sysctl -w net.ipv4.tcp_ecn=1
you'll generally see the tcp performance get "smoother". (but I haven't reviewed the patch and don't remember if ecn made it into the bsd code or not)
-
@luckman212 yes, if you have two different interfaces at two different speeds you should set the limiter separately.
-
@uptownvagrant yep, nat can be a major issue for any given protocol, and it would not surprise me if that was the source of the icmp lossage with load. I'm still puzzled about "the burp at the end of the test" thing (which also might be a nat issue, running out of some conntracking resource, etc)
-
@strangegopher cablemodems do ipv6 by default now, so I would stress that future shapers/limiters always match all protocols. Otherwise (see wondershaper must die).... as for your performance closer to the spec, does the limiter have support for docsis framing? The sch_cake shaper does, and we can nail the upstream rate exactly. It's like, 3 lines of code in sch_cake....