TCP Keepalives failing over NAT
-
I have the following configuration:
LAN1 –-- pfSense FW ----- LAN2
LAN1: 10.200.0.0/16
LAN2: 10.210.0.0/24pfSense FW: 2.3.4-p1 with Intel Pro/1000 Gigabit NICs
On LAN1 there is a MS SQL Server 10.200.2.10 listening on TCP port 1433.
On LAN2 there are clients (one is 10.210.0.110) that connects to the server and performs various SQL queries.
LAN1 is the "WAN" i/f. LAN2 is the "LAN" i/f. Clearly NAPT is being used.
The problem is that about once every 10 - 20 hours or so, the client issues an RST to the server due to the server apparently not responding to the TCP keep-alives from the client after a while. As you can see in the attached trace (done on LAN2), the connection works fine until some random point where the server responds 1 retry too late to the client's tcp keep-alives, i.e. MS SQL Server having a limit of 5 missed keep-alives before issuing a RST. There are 5 missed retries and then the server responds but it is too late - the client issues an RST and causes an application level problem.
My questions are:
1. Why does this work fine for hours on end but only some times every 10 or 20 hours, the server seemingly stops responding to the tcp keep-alives?
2. Why does the server's ACK always arrive after it misses 5 packets? This is not coincidence - I reviewed many traces and in all instances the client only issues an RST after 5 missed tcp keep-alives AND the server responding with an ACK for the first missed packet?Take note that I confirmed the pfSense is at fault. I relocated some of the clients from LAN2 to LAN1, and they never experience this issue. The clients on LAN2 still experience this issue every 10 - 20 hours. I think it has something to do with NAPT and state management and the tcp keep-alives? Can anyone give me insight as to how I can fix this?
-
First thing I would do is why and the hell are you natting between rfc1918 address space in the first place?
2nd - You really have 65k nodes on what your calling lan1? /16 really?
3rd its Not a lan if its pfsense wan.. Its a transit network.. You can get around that with sure natting. But see first thing!
Where exactly are you sniffing? Where is the sniff on the other interface so you could validate pfsense is not sending it on. If pfsense was blocking the traffic because of a timeout, then it would be listed in the log.. Do you see out of state blocks in the firewall log?
-
1: Initially for security - the LAN2 interface has WinXP machines that cannot be upgraded due to legacy PCI cards and no newer drivers - LOB app that needs them. I guess I could have set up plain routing between the two subnets and block the LAN1 -> LAN2 traffic via the firewall, and only allow port 1433 for LAN2 -> LAN1.
2: No, it was a legacy thing where I merged multiple networks and wanted to keep some of the IPs the same - it is not a crime to use 10.200.0.0/16 is it?
3. Noted.
I did say I performed the sniff on LAN2 interface. I also did a sniff of a separate event on both interfaces and they basically mirrored each other, the LAN1 sniff showed the tcp keep-alive packets being sent on to the SQL Server but no responses arrived until after the 5th transmission. It looks like the firewall is doing its job, but as I said - take the firewall out of the picture and the RSTs stop.
Out of state blocks?
-
So if I do want to do away with NAT and set up simple routing - what do I need to change for that? How do I perform routing between two RFC1918 subnets without doing NAT? And will I still be able to use the firewall for specific port based access?
-
" it is not a crime to use 10.200.0.0/16 is it?"
No just stupid ;) And when you post on forum that is what your using - reflects on what your dealing with ;)
As to how to not nat between them.. Turn off nat.. Yes you would still be able to firewall. If you didn't have it setup as a WAN, then it wouldn't nat between them anyway.
Your only showing sniff on lan2 - where is sniff from lan1? Where is firewall rule log showing it blocked state… If you had a issue with states and your traffic became out of state then it would be blocked yes - but logged..
Do a sniff on both interfaces at the same time so we can actually follow the packets and either prove pfsense is not sending them on.. From your sniff you have nothing showing that pfsense didn't send them on and something else prevented them from getting there - or box just didn't freaking answer, etc.

-
No just stupid ;) And when you post on forum that is what your using - reflects on what your dealing with ;)
Not a very nice thing to say… As I said I had a reason to do this. Not the best reason, but also not just because I was ignorant.
So if I remove the GW from the LAN1 interface and disable outbound NAT, how would the box route packets from LAN2 to the internet should I want that?
See attached for a sniff on both sides. 10.200.2.1 is the FW IP on LAN1. It seems like the firewall is doing its job as I said, but why, when removing the firewall, does it work perfectly?
I do not see anything in the firewall logs about states being blocked.
-
Oh is this a tea party for little girls? It thought it was a tech forum where we exchanged info and gave honest input.. My bad if confused the locations and offended you in some way ;)
"So if I remove the GW from the LAN1 interface and disable outbound NAT, how would the box route packets from LAN2 to the internet should I want that?"
Via a WAN interface an a tranist network on pfsense would normally be how you would do that when pfsense is being used as a downstream firewall/router.. Without some understanding of your overall network layout I can not help you with how you would give downstream networks internet access.
You could still leave an interface as "wan" with default route out, and not do nat.. And then just nat it at your edge. But like I said without understanding of your overall network and what is upstream of pfsense have no idea what would be the best setup.. Other than I can tell you for sure natting between rfc1918 on your own local network where you control the IP space is NOT the optimal setup for sure ;)
More than happy to look at some traces for you, etc.. But put up the pcaps direct vs this text… But thought you said you disable nat??? Clearly you did not since on your lan1 sniff all the traffic is from 2.1
But you can clearly see the traffic sent from from pfsense to 10.200.2.10, multiple times and no answer from the 2.10 box.. So pfsense put the traffic on the wire.. It has no control on why the box doesn't answer back etc.. Until multiple retrans..
-
Oh is this a tea party for little girls? It thought it was a tech forum where we exchanged info and gave honest input.. My bad if confused the locations and offended you in some way ;)
I have no issues at all with criticism, as long as it is constructive. Telling me picking /16 vs say /22 is stupid, is constructive. Telling me that that implies I am stupid is not. Just saying…
Via a WAN interface an a tranist network on pfsense would normally be how you would do that when pfsense is being used as a downstream firewall/router.. Without some understanding of your overall network layout I can not help you with how you would give downstream networks internet access.
There are two things I'd like to get out of this. AFAIK doing NAT on RFC1918 addresses is not wrong - perhaps questionable but not wrong, meaning this setup should be working - right? In fact, the system handles about 30 or so complete SQL Server transactions per minute without issue for 10 - 15 hours straight, and only then encounters the issue I mentioned, but then resumes to work fine for the next 10 - 20 hours. PS: I used NAT as it was the simplest to configure - I wanted the PCs on the LAN side of the FW isolated. NAT is an inherent FW so I thought it was the most straight forward.
The other thing, is to reconfigure the network so that the problem is fixed.
More than happy to look at some traces for you, etc.. But put up the pcaps direct vs this text... But thought you said you disable nat??? Clearly you did not since on your lan1 sniff all the traffic is from 2.1
(Thanks for the assistance). Nope, I said "if I disable NAT" - those traces were from before I tried disabling NAT. They showcase the problem I am dealing with in the current configuration. I was unsure how to configure routing if I disable NAT, but I tried it yesterday night but ran into asymmetrical routing issues.
But you can clearly see the traffic sent from from pfsense to 10.200.2.10, multiple times and no answer from the 2.10 box.. So pfsense put the traffic on the wire.. It has no control on why the box doesn't answer back etc.. Until multiple retrans..
Sure, I agree with you, but the question still remains - if the PC is connected directly to the same LAN as the server, why do I never see these keep-alive timeouts / retransmissions? The firewall affects something, just not sure how.
So I agree - let me show you the current (NAT) configuration. I am simplifying a bit but it should include everything that is relevant.
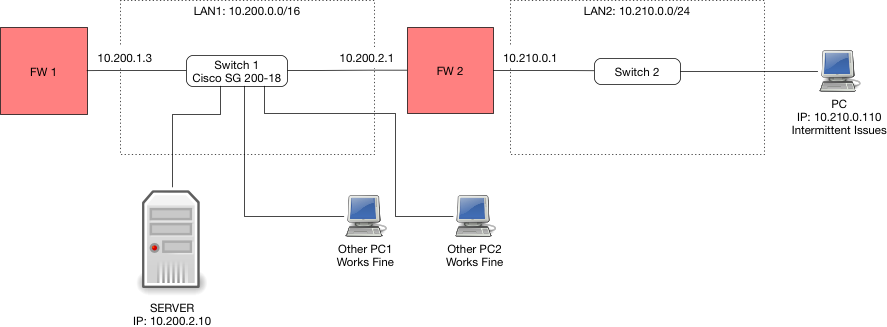
FW1 has a WAN interface (not shown) that is my uplink to the internet. FW1' LAN1 IP 10.200.1.3 is the default GW for all LAN1 devices. FW2 is the firewall I have been running the traces on. I cannot upload the pcaps as they contain actual data from the SQL server - which is sensitive information (yeah yeah no TLS - this is an old system).
So to reconfigure this without NAT, I tried the following:
1. I removed the GW from FW2's LAN1 interface (which was its "WAN" type interface due to the GW).
2. This removed the auto generated outbound NAT rules on FW2, but I furthermore changed it to Disable Outbound NAT.
3. For now I did not concern myself with internet accessibility for PC.
4. Clearly SERVER would not know how to reach 10.210.0.0/24 now, so I added a (non default) GW on FW1 pointing to 10.200.2.1, and added a static route that directs traffic destined for 10.210.0.0/24 to that GW 10.200.2.1.
5. I also added a firewall rule (very generous rule just to get things working) on FW2 LAN2 allow any to any, and FW2 LAN1 allow any to any.
6. I added a FW rule to FW1 LAN1 allowing all from 10.210.0.0/24 to LAN1 net and all on LAN1 net to 10.210.0.0/24.ICMP / traceroute worked fine both ways between SERVER and PC. However, TCP did not probably due to the asymmetric path the packets were traveling. A packet capture confirmed this - SYN was sent to the SERVER and received by it, a SYN/ACK was returned and received by FW1 but never made it to FW2. So what am I missing? Should I add a GW on FW2 pointing to 10.200.1.3 for all traffic destined to 10.200.2.10 (i.e. SERVER IP) to force it to route through the FW1 so that its state tables can be consistent? Or do I need to enable "Bypass firewall rules for traffic on the same interface" in pfSense FW1 and FW2 and leave the asymmetric path as is?
-
" FW1' LAN1 IP 10.200.1.3 is the default GW for all LAN1 devices."
You run into an asymmetrical mess without your nat sure..
"4. Clearly SERVER would not know how to reach 10.210.0.0/24 now, so I added a (non default) GW on FW1 pointing to 10.200.2.1, and added a static route that directs traffic destined for 10.210.0.0/24 to that GW 10.200.2.1."
Asymmetrical mess!!!
Your downstream network should be connected to fw1 via a transit network, no devices other than routers/ firewall should sit on a transit. If hosts sit on a transit then you need to use host routing to tell the how where to go so you do not run into asymmetrical issues. Yes one way to work around is via nat - but this is not a good or suggest solution but a lazy work around that has its own issues!! Downstream routers should always be connected to upstream routers via a transit network. Now you do not have to nat to work around the asymmetrical issues.. And easier to route and control, etc. etc. etc..
Clean your sniff to remove the sql info.. Just leave the keepalive stuff.
But I would suggest you sniff on the sql server to validate it actually gets the keep alives that you can clearly see pfsense putting on the wire!! So while you can try and blame pfsense - its only function is to put the packets on the wire.. It has nothing to do with if the device answers or how fast it answers, etc.
Even the acks that seem to be working early on in the the trace shows that your getting retrans.. You can see from the seq and ack numbers.. And the
[Reassembly error, protocol TCP: New fragment overlaps old data (retransmission?)]But again - pfsense only job is to move the traffic.. The device actually getting it or responding to it fast enough to not have it generate a retrans has noting to do with pfsense..
If your timestamps are to believe the packets are are moving across pfsense that is natting them in 0.000004 seconds.. So the delay is not the issue..
It would be far easier to look into the sniffs if they were actual pcaps.. Do you need help on filtering out the non keepalive traffic?
-
Thanks John - this is already super helpful. Let me try and set up a dump on SRV1. I am sure I can figure out how to run tcpdump to filter on TCP keep alive. If not I'll ask. Will get post it once the error happens again.
-
Ok it happened again, 17 Aug at approx 10:07:35 CDT, again at 10:08:16 CDT and again at 10:10:46 CDT (Central US Time). It is around the three RSTs in the trace file.
I captured a trace using netsh on the windows SERVER box (on LAN1), a trace on FW2's LAN1 interface and FW2's LAN2 interface. Since netsh cannot filter on anything more than protocol and IP, I could not filter only on keepalives. So I used wireshark with this filter:
(tcp.analysis.keep_alive_ack or tcp.analysis.keep_alive or tcp.flags.reset==1) and tcp.port==1433 and frame.number > 33000
I exported the displayed results as pcap. Clearly the frames will now have some gaps so the data you see is not exactly how it appears to me. I also included a txt export for each that resembles what I see better as this is based on the displayed results. I also included a summary txt export as before. Hope together they help.
Take note that IPs are different. SERVER is on 10.200.2.6, FW2 LAN1 is 10.200.2.16, FW2 LAN2 is 10.210.0.1, CLIENT PC is 10.210.0.100.
I see TCP keep-alives working fine, then suddenly the FW2 keeps on receiving keep alive requests from CLIENT PC, which it NATs to SERVER, however SERVER does not seem to be receiving them, it is however transmitting them to FW2 as well - not ACKING the keep-alives as it is not receiving them. What is your assessment? If you need the full files I can possibly send them to you privately.
-
"however SERVER does not seem to be receiving them"
I have not had chance to look at your sniffs yet… But from this statement sounds like fw2 is sending the traffic on - but not being seen on the server. If this case then you have issues in your network.. Since pfsense did what it suppose to and sent the traffic on.. Some real work issues working on now, but will be happy to take a look at the sniff when I get a chance..
-
But from this statement sounds like fw2 is sending the traffic on - but not being seen on the server. If this case then you have issues in your network.. Since pfsense did what it suppose to and sent the traffic on..
The other client machines are connected to the same Cisco SG200-18 switch as the server - so the path is really short (and the other clients work fine). FW2's LAN1 is connected to same switch. It has the latest firmware. (I updated the image to reflect this).
-
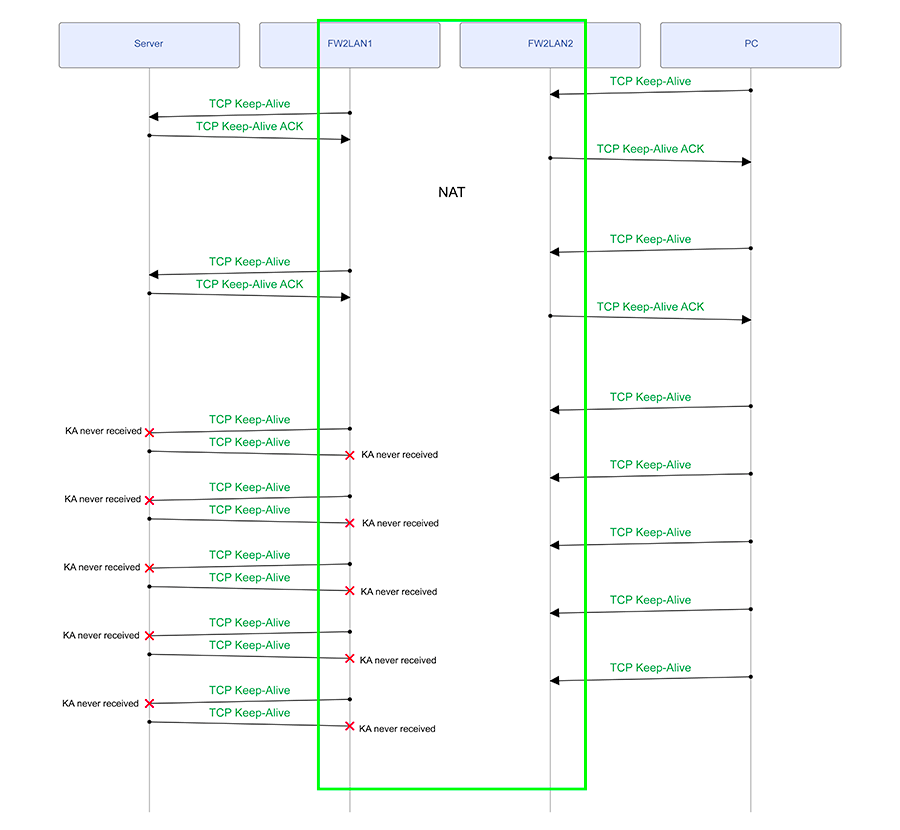
I have analyzed the packet traces and this is what I see. Take note that the packet captures were done on all lifelines shown here EXCEPT for the PC, but that is not important as the PC never has issues not receiving packets / sending packets. The issue seems to be on the LAN segment between SERVER and FW2LAN1.
-
"The issue seems to be on the LAN segment between SERVER and FW2LAN1."
Would make sense.. Can you check the layer 1 between, maybe move ports on your switch.. What specific switch you running and firmware? We had a really odd bug in cisco switch one time where all would work great and then all of sudden switch would not pass on packets that were inside specific vlan. You would see it enter the switch, but not leave..
Oddest freaking thing - took a bit to track it down. and work around until we updated the firmware was just add an svi on that vlan - even if not being used, since it was just a layer 2 vlan.
If you can sniff right on your switch on this specific vlan might give you some insight you should see the packets twice, once when they enter the switch and then again when they leave the switch.
-
Will see what I can do once my client gets back to me with the switch's details.
-
So the switch is a Cisco SG200-18, and was on firmware 1.3.7.18 (I was told it was latest, clearly it was not). I just updated it to 1.4.8.6 - so I guess I have to wait and see. Just weird that this is the only issue we have on this network segment - nothing else is broken (AFAIK).
PS: There are no VLANs configured on this switch - all nodes use the default VLAN. And as far as I can tell, even though this is a managed switch, nothing non standard has been configured.
-
So no - the firmware update fixed nothing, in fact, it seems worse now - these issues appear once every 1 - 2 hours now. I cannot do a packet capture on the switch. Not sure how to troubleshoot this further.
-
Any ideas?
-
Here is the thing your sniffing on the devices connected to the switch.. And you see 1 device send the packets, and the other device does not get the packets.. That really really points to the switch.. You don't have any patch panels between the devices right.
you have
device1 –- cable --- switch --- cable --- device2If your sniffing on 1 and 2, and you see 1 send but 2 does not get.. Its the switch or the cables - and have never seen a cable drop packets just now and then.. If they are bad they are normally bad! all the time. But to rule it out you could change the cables.
Have you changed the ports the devices are connected to on the switch?