DNS ReBinding Error after updated 2.4.4

-
I seem to have a problem after upgrading to the newest version of pfSense.
I have a plex server that is hosted on 192.168.1.20 and although I have added the "Custom Option" to allow DNS ReBinding for plex.direct. It seems that this is now broken with 2.4.4, as I am no longer able to access the server.

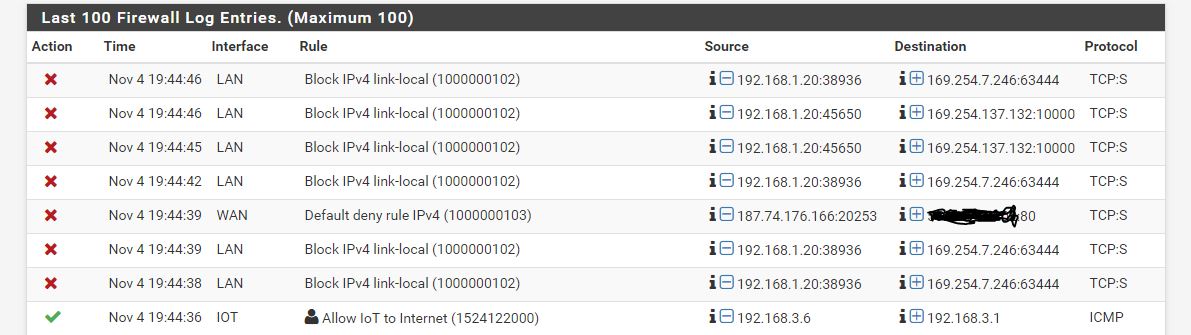
This is what I currently am seeing in my Firewall:
Can someone please point me in the right direction of what I am missing? How do I disable DNS Rebinding protection just to see if that is the issue that I am currently having? Any help you can offer will be greatly appreciated. -
Blocks to 169.254 has zero to do with your plex redirect. Unless your plex is broken and using an APIPA address.
Also I do believe doing the multiple
server:
Is going to cause you problems. At least it use to - before you should only need to call out the server: once in your custom section.Resolve your fqdn for the plex.direct what does it resolve too?
Fire up say web console in firefox and look to see what is going on when you try and log in withhttps://app.plex.tv/desktop#
You should see something like - then you can do a dns query for that fqdn.
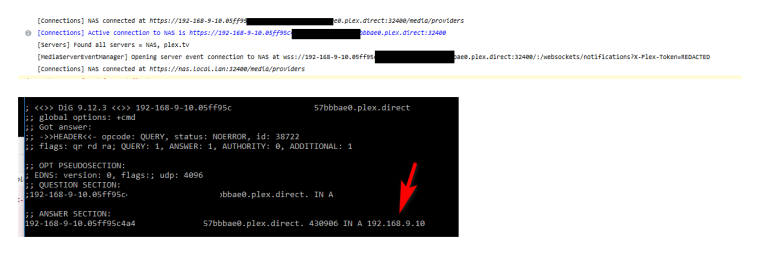
But to turn off rebind completely
System / Advanced / Admin Access

I am running 2.4.4 and have no problems accessing my plex... Which you can see is running on 192.168.9.10 on my local network.
If your returning a 169.254 address then yeah you have a problem with plex..
-
Thanks for the direction.
I checked that and none of the IPs that came up are in the 169.254..
One of them appears to be my DirecTV wireless bridge. The others I can not ssh/telnet/http them so I have no idea what they refer to our why my ReadyNAS (Plex Server) is sending packets to them.How would I find out what these IPs associate with in pfsense? I checked the ARP table and none of these address appear. They are obviously not in DHCP either.....
-
Yeah directv wireless bridge will have link local and send noise out on it, etc.
Here is the thing since that is dest IP, the client being really stupid says oh that not my IP let me send it to my gateway... Even though its a link-local address, ie 169.254
Only way to figure out if that is even on your network would be to check all your networks. 63444 is xsan - apples sort of stuff... You running any sort of time capsule or other apple devices on your network. Port 10000 is prob best known for webmin.. But lots of stuff could use that port - much of it BAD..
You probe have better luck looking on the device for the application that is trying to talk outbound on the ports.. this 192.168.1.20 box... What applications are trying to make outbound connections on those ports?
If you need it you need it to figure out the correct IP to use.. If not try turn it off at the client - or you could always just not log such noise.
But none of that has anything to do with your plex issue... Unless your trying to run plex on 1 of those 2 ports?
-
You sir were right. Unfortunately I believe it was my Readynas server. I restarted it and all my local:link firewall hits stopped.
I have it setup in a LAGG group and I believe one of the Ethernet ports must have lost it's "membership". After I rebooted I am now jot having any issues with the 169.254, and my Plex server is working beautifully. Interesting that this started appearing after my upgrade.
Thanks for the help.
-
How many clients do you have that lagg makes sense? Just curious.. You do understand its not 1+1=2 in a lagg, its just 1 and 1 for bandwidth.. An single client is not going to send traffic over both..
Are you using smb3 multichannel over the lagg at the same time? You can do that without lagg.
-
So great questions and my lack of knowledge may be why I chose this.
I currently have around 10 IPCS HD that use my Readynas as a NVR. That Readynas also runs my Plex (around 8 clients in and out of my home) , NextCloud server, and occasionally my Torrent client (I don't pirate, but do host raspberry Pi and Ubuntu torrents).
So I thought LAGG would help to make sure that I don't saturate that connection if all cameras are recording (after 9pm) and me and wife and kids have Plex streams going.Is this still overkill?
-
In the case of cameras to your NVR... No the lagg might make sense - depends on how much the streams are going to be and validation that they are actually being split across the 2 physical paths you created with the lagg.
And that also you don't have some other bottleneck that invalidates the lagg, etc.. Have seen this for example
X # of Cameras --- switch1 --- uplink 1gig --- switch 2 -- LAGG 2x1gig -- NVR
As to "overkill" not sure would use that word, more like overly complicated for no actual reason. And not actually used is normally more the case when users setup lagg.
Why don't I see 2gig in such a setup for example
PC - lagg 2x1gig -- switch -- lagg 2x1gig -- Server
But you mention that 1 of the lagg went down so your device used a 169.254 address? That gets me curious - so your NVR is getting 2 IPs? A loadshare over a lagg would normally only be 1 IP.. If each connection is getting its own IP seems unlikely the traffic would be split across the lagg, etc. Traffic path would depend on which IP being used, etc.
Just because you setup lagg on the switch side.. If the end device just sees it as 2 different connections doesn't mean your going to see split traffic unless you actually use the 2 different IPs, etc.