States
-
My PFSense is running well, but I exceeded the States limit a few days back (a release of all states fixed) , and have been checking on what States does. I am on 2.4.4
My defaults are 200000 states, and I have set the firewall adaptive timeouts to be 30 000 and 60 000, but these seem to do nothing.
Overnight (from midnight to 7:00 am) my states table increased by 101569, as that is how many states I cleared at 7:00 am using 'pfctl -F states' from the console shell. Two hours later, and I have another 61868 states cleared.
Looking at the 'state' entries from Diagnostics >> States, I see that many (by far most) are port 53, which is DNS lookups.
I host my own mailserver, and I do upwards of two dozen DNS lookups for all mail messages that pass through my server, when you count RDNS, DNSBL, SURBL as well as DNS looks up from zz.nerds.de to ascertain country of origin of the connection.I tried to create a firewall rule that allows this traffic, but doesn't create a state for it
I have two rules on my WAN interface
Action = pass
IPv4
UDP
source = ANY
Destination = ANY
Destination port range is 53 to 53
Description is DNS search
Advanced options - State type = noneThe second rule is a copy but with the 'invert match' selected for Destination
I also have an identical rule to the first one for my DMZ interface.I just can't stop the states being created, and they don't auto empty. I don't understand what I'm not doing correctly.
As an aside, the thing that I changed this week prior to getting state table full errors, was adding a Netgear LB2120 between my PFSense WAN port and my fibre optic connection (Australian NBN FTTP) to automatically fallback to 4G if my fibre optic connection was down. I can't believe that PFSense is capturing this device as it is a) bridged and b) set to an IP address outside of ANY of the PFSense interfaces.
My interfaces are
hn0 = WAN = IPv4 via DHCP
hn1 = LAN = 192.168.0.0/24
hn2 = DMZ = 10.0.0.0/28LB2120 = 192.168.55.1
Thanks in advance for any help
-
If all you're doing is DNS lookups from your LAN or DMZ hosts, why open UDP/53 on the WAN?
-
These are all outgoing lookups from my non-caching BIND9 server in my DMZ
I don't allow incoming port 53 connections that were initiated my my server...What am I missing?
-
It's probably me that's missing something.
Your first rule allows incoming UDP/53. Are you hosting DNS for your own domain?
-
NO I use the DNS of my Regisrar to host real domain records for the domains that I manage / operate.
(That may change, but I want my system to be very robust first)My Bind9 ONLY handles dns searches for my mailserver, and one or two machines on my LAN.
Most of my LAN users use the OpenDNS servers for normal lookups - as a way to control my users browsing habits (my kids really).I have a DMZ with my work servers on it (Mail server and Web server and this spam appliance- with Bind9 and not much else), and otherwise basically a normal home network with three teenagers. (I work from home).
And checking on GRC shields up , port 53 is blocked for incoming traffic.
-
I'm not certain of this but I don't think ShieldsUp checks UDP.
I also run my own mailserver (in a DMZ) and just use the resolver in pfSense. The only pass rules I have on WAN are TCP/25 to the mailserver and UDP/1194 to OpenVPN.
Mine is a postfix MTA and it queries DNS, RDNS and zen for each incoming email. Never had a problem with states but only 40 to 50 inbound emails/day..
You could disable your WAN UDP/53 rules and see what happens. Shouldn't affect your email or DNS lookups at all. Happy to send you an email, too, if you like.
-
@outbackmatt said in States:
I have two rules on my WAN interface
Action = pass
IPv4
UDP
source = ANY
Destination = ANY
Destination port range is 53 to 53
Description is DNS search
Advanced options - State type = noneIf your description is right and you have these rules on your WAN interface you have opened up port 53 of your pfSense to the world, which is pretty stupid. Read this: https://www.netgate.com/docs/pfsense/book/firewall/index.html thoroughly and post actual screenshots of your rules/configuration in the future, to avoid confusion.
-
Sure
@biggsy, you are correct - ShieldsUP is only RDP, not UDP
I have now removed those rules that I added last night for port 53Without those rules I was getting exactly the same behaviour anyway.
What I want to achieve id to NOT create two STATEs for each outgoing port 53 UDP connections - rather then creating hundreds of thousands of them each day.
How can I create a rule that doesn't make a STATE
-
every connection created states ... pfsense is a stateful firewall.
when a connection is closed/ends, the state gets removed.if your states keep increasing & they all appear to be from your bind server, then i suggest fixing your bind
==> this probably means your bind is not closing its connections -
So the settings at
GUI >> System >> Advanced >> Firewall & NAT >> Firewall adaptive timeouts
aren't meant to workAnd the
Firewall Rule >> Extra Options >> Advanced >> State type = None
Isn't meant to achieve anythingAnd to be honest, I'm not sure that any states get removed when a connection closes. It looks to me like all connections are staying open. Every time my max state limit is reached, pfsense just stops responding until I remove all states with a console shell command 'pfctl -F states' and they they start to build up again very quickly. Not all of my open states are from my BIND9 - it is just by far that most of them are. Over 200000 states in less than 10 hours - and this has only started to happen in the last week or so, probably since upgrade to 2.4.4
How can I check that states are actually getting removed?
And one other thing that is really weird - my traffic graphs are all over the place, it is like the time jumps backwards and forwards every few seconds
-
@outbackmatt said in States:
GUI >> System >> Advanced >> Firewall & NAT >> Firewall adaptive timeouts
aren't meant to work
And the
Firewall Rule >> Extra Options >> Advanced >> State type = None
Isn't meant to achieve anythingyes they are meant for to work. but in any normal situation, the default are fine.
if the numbers of states keep rising indefinately, then something is seriously wrong.if there is an issue with time, then lots of weirdness can happen ... are you running this in a VM ? if yes, disable host/vm time sync
-
are you running this in a VM ? if yes, disable host/vm time sync
Yes I am running on a hyperV
I have disabled time Sync, and that seems to have fixed my 'states' issue following a rebootMy traffic graphs till look a mess , but that's no big deal
Thanks for the host time trick
-
Perhaps that is not yet sorted
18 hours since last post and 126970 states just got cleared -
By default, a UDP state is automatically removed after 60 seconds of inactivity. Setting the firewall to Conservative in System > Advanced, Firewall & NAT increases that to 15 minutes.
pfctl -stwill show you the current timeouts.You would likely need two rules to pass the UDP traffic without creating any states:
INSIDE (LAN) Pass UDP source BIND_SERVER dest any port 53 State: No
OUTSIDE (WAN) Pass UDP source any dest BIND_SERVER port 53 State: NoAnd I think the following will work for TCP:
INSIDE (LAN) Pass TCP source BIND_SERVER dest any port 53 TCP Flags any State: No
OUTSIDE (WAN) Pass TCP source any dest BIND_SERVER port 53 TCP flags any state: NoYou probably also need floating rules that match these in the outbound direction on the other interface to keep states from being created there too.
Really hard to believe you're doing 100K DNS queries a minute though. I'd fix that instead.
-
The thing is that I really am NOT doing 100000 DNS checks a minute.
I just did another 'pfctl -F states' - the previous one was 16 to 18 hours ago, and 165109 states were cleared.I doubt that I have done even half that number of DNS checks in that same 18 or so hours.
My mailserver isn't very busy, I handle maybe 500 messages per day, and there should be about 20 DNS lookups for each of those, and perhaps a DNS check for some other incoming connection attempts (to see where the connection is from) for those accessing my websites, or trying to connect IMAP or POP (eg users and hackers). I have only about 80 or so users, and I block say six or seven hacking attempts per day.This just doesn't match the number of states at all. It is really hard to see how I could get to 200 000 states per day, even if most of them are duplicated, but for different interfaces.
It is like all of the states are remembered and none are dropped at all. I was thinking if I didn't record states for port 53, that it would lighten the load and I may get more than 24 hours without having to manually force the dropping of all states.
I can't check the web based GUI for states as the GUI times out when the states table is large, the states display doesn't show created time anyway. I have many tens of thousands of states that show NO_TRAFFIC:SINGLE or SINGLE:NO_TRAFFIC, not all of these are port 53, but many are.
There is clearly a problem in my setup, but I have no idea on how to track it down.
My entire rule set is three NAT Port forward auto generated rules.
#1 forwards mail ports to my mailserver
#2 forwards web server ports to my web server
#3 custom RDP port forward to my desktopThis isn't a fancy setup.
This is intended to protect my home office from outside attack, and safeguard my teenagers while they web surf.What could be causing the states to be persistent?
This seems to have started with 2.4.4 -
Really hard to say based on what has been shown.
pfctl -vvss | grep -A3 _some_criteria_where _some_criteria is something like a remote DNS server that gets used all the time and has a bunch of states but is manageable to work with. Something to narrow it down.That will show you when the state was created, when it last passed traffic, etc.
NO_TRAFFIC:SINGLE should drop off fairly quickly by default.
-
running 'pftcl --vvss | grep -A3 8.8.8.8:53 >/tmp/output.txt creates an output file that starts like this (37855 lines in total!!)
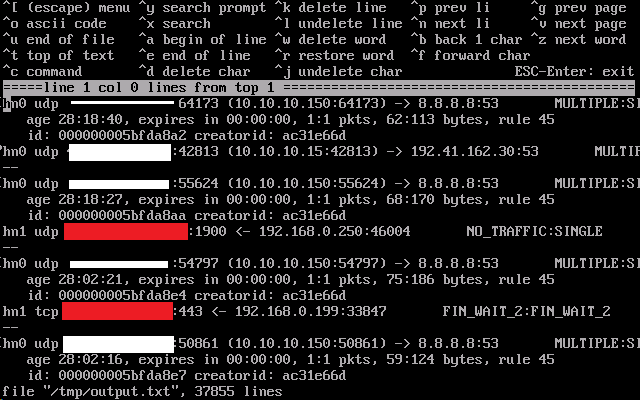
8.8.8.8:53 is Google DNS server which is queried reasonably frequently it seems from my BIND9
Does that first one look to be 28 hours, 18 minutes and 40 seconds old, and already expired?
Whiteout is my public IP address
Red-out is other public IP addresses -
This post is deleted! -
All of those
expires in 00:00:00are very very strange.It's like your states aren't expiring out of the state table when they should. I've never seen anything like that before.
I would completely revisit anything you have done to try to solve this problem. Custom rules, state timeouts, etc.
-
What is the output of
pfctl -st??