Some help interpreting the crash files?
-
Hi all,
I've installed 2.5.0 snapshots to test on four ALIX devices, and now they all keep crashing and rebooting, often - on one device, it happened 14 times since yesterday afternoon.
I may have unsupported hardware, or it may be because I didn't remove extra packages before upgrading - but I can't interpret what the crash dump is trying to tell me. Can someone give me a pointer, please? If necessary, I will try to reinstall fresh, or whatever..
I've uploaded one set, these go up to .13 (but the forum doesn't like the extensions higher than .0 - and they seem to be are more of the same)
This may be the relevant part:
Fatal trap 12: page fault while in kernel mode cpuid = 0; apic id = 00 fault virtual address = 0x70 fault code = supervisor read data, page not present instruction pointer = 0x20:0xffffffff80ee68d7 stack pointer = 0x28:0xfffffe002d22c320 frame pointer = 0x28:0xfffffe002d22c360 code segment = base 0x0, limit 0xfffff, type 0x1b = DPL 0, pres 1, long 1, def32 0, gran 1 processor eflags = interrupt enabled, resume, IOPL = 0 current process = 40056 (unbound-anchor) -
@mi8088 said in Some help interpreting the crash files?:
I've installed 2.5.0 snapshots to test on four ALIX devices, and now they all keep crashing and rebooting
I highly doubt that. ALIX devices are not capable of running 2.5.0. Perhaps you meant APU devices?
What you want from that tar file is primarily the backtrace from
ddb.txt:db:0:kdb.enter.default> show pcpu cpuid = 0 dynamic pcpu = 0xb31c40 curthread = 0xfffff80005359000: pid 40056 tid 100102 "unbound-anchor" curpcb = 0xfffffe002d22ccc0 fpcurthread = 0xfffff80005359000: pid 40056 "unbound-anchor" idlethread = 0xfffff80004208000: tid 100003 "idle: cpu0" curpmap = 0xfffff80005a8c130 tssp = 0xffffffff82db3a20 commontssp = 0xffffffff82db3a20 rsp0 = 0xfffffe002d22ccc0 gs32p = 0xffffffff82dba658 ldt = 0xffffffff82dba698 tss = 0xffffffff82dba688 curvnet = 0xfffff8000406d640 db:0:kdb.enter.default> bt Tracing pid 40056 tid 100102 td 0xfffff80005359000 in_broadcast() at in_broadcast+0x27/frame 0xfffffe002d22c360 pf_test() at pf_test+0x201b/frame 0xfffffe002d22c610 pf_check_out() at pf_check_out+0x1d/frame 0xfffffe002d22c630 pfil_run_hooks() at pfil_run_hooks+0xa1/frame 0xfffffe002d22c6d0 ip_output() at ip_output+0xc85/frame 0xfffffe002d22c810 udp_send() at udp_send+0xb6e/frame 0xfffffe002d22c8e0 sosend_dgram() at sosend_dgram+0x33b/frame 0xfffffe002d22c950 sosend() at sosend+0x50/frame 0xfffffe002d22c980 kern_sendit() at kern_sendit+0x19f/frame 0xfffffe002d22ca20 sendit() at sendit+0x19e/frame 0xfffffe002d22ca70 sys_sendto() at sys_sendto+0x4d/frame 0xfffffe002d22cac0 amd64_syscall() at amd64_syscall+0x369/frame 0xfffffe002d22cbf0 fast_syscall_common() at fast_syscall_common+0x101/frame 0xfffffe002d22cbf0That particular backtrace doesn't look familiar, though. Are all of these identical? It's odd that it's claiming to crash in
unbound-anchorwhich manages trust anchors for DNSSEC, and the backtrace suggests that it's crashing while checking if an IP address is a broadcast address. That's a fairly simple operation, so I would tend to think it's actually a hardware operation failing there (e.g. memory/cpu/heat). Though why it would only happen on 2.5.0 and not before is less clear, unless it's a BIOS or other similar issue leading to instability.As for the crash dumps, you can rename them to
textdump.<n>.tarinstead. They are just.tarfiles but the way FreeBSD writes the crash dumps it tacks the number on the end since it's easier that way. -
I'd have to check to be sure - i've overtaken them from another person, who always refers to them as ALIX - they might be APU, though. I can't check now as not close at the moment. I do get a GUI and some functionality, so they are in some sense capable of running. just not very well

Some general info: I have packages frr on all four, acme on some (not used though), and blinkled packages. These were there before upgrading to 2.5.0.
Anyway, comparing the bit you refer to in all the files shows some differences, even though most are the same. I also find, instead of "unbound-anchor", "ntpd" (#7) and "dpinger" (#12) and "ospfd" (#13) in that part.
In dump #12, the corresponding part is
db:0:kdb.enter.default> show pcpu cpuid = 0 dynamic pcpu = 0xb31c40 curthread = 0xfffff8011a72d000: pid 15283 tid 101158 "dpinger" curpcb = 0xfffffe002d316cc0 fpcurthread = 0xfffff8011a72d000: pid 15283 "dpinger" idlethread = 0xfffff80004208000: tid 100003 "idle: cpu0" curpmap = 0xfffff8002097c130 tssp = 0xffffffff82db3a20 commontssp = 0xffffffff82db3a20 rsp0 = 0xfffffe002d316cc0 gs32p = 0xffffffff82dba658 ldt = 0xffffffff82dba698 tss = 0xffffffff82dba688 curvnet = 0xfffff8000406d640 db:0:kdb.enter.default> bt Tracing pid 15283 tid 101158 td 0xfffff8011a72d000 ??() at 0 ip_output() at ip_output+0x13f3/frame 0xfffffe002d316810 rip_output() at rip_output+0x2c3/frame 0xfffffe002d3168a0 sosend_generic() at sosend_generic+0x586/frame 0xfffffe002d316950 sosend() at sosend+0x50/frame 0xfffffe002d316980 kern_sendit() at kern_sendit+0x19f/frame 0xfffffe002d316a20 sendit() at sendit+0x19e/frame 0xfffffe002d316a70 sys_sendto() at sys_sendto+0x4d/frame 0xfffffe002d316ac0 amd64_syscall() at amd64_syscall+0x369/frame 0xfffffe002d316bf0 fast_syscall_common() at fast_syscall_common+0x101/frame 0xfffffe002d316bf0It's not impossible the hardware is the problem, but all of the devices ran for several years without problems, up to the last production version (2.4.4-p3). We then replaced them with new gear, and use them as test boxes. I'd would seem weird if they all had a hardware fault simultaneously..
I've made a new tar file with the complete contents of the 14 dumps.
(Uploading 100%) textdumps.tgz
They're turned off now, and tomorrow I'll try to reinstall one with 2.5.0 direct, or an older version.
-
If it's that random, it would have to be hardware/driver related. It's stable on my APU (first generation), but maybe if those are APU2 or some later revision it might be related to the network drivers.
-
Well, I've reinstalled all from memstick, no packages, basic config (basically the wizard) and they have been running without problems for 16 hours. Either the newer snapshot solved it, it's a package causing errors, or the upgrade process went wrong and caused errors.
They're APU, not APU2, by the way. Should be these, 4 GB RAM: https://pcengines.ch/apu1d4.htm
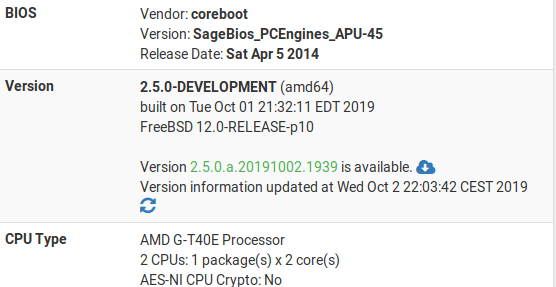
Going to go do the upgrade to the latest snapshot on two of these, see what happens then..
-
[Edited with new info]
Well, that didn't quite work, first time round
The update one the first device was stuck for about 2 hours, looking like this:
In the system log, I found loads of these lines (on all four devices):
Oct 3 09:04:59 check_reload_status 373 Reloading filter Oct 3 09:05:00 php-fpm 24759 /rc.newwanipv6: rc.newwanipv6: Info: starting on re1. Oct 3 09:05:00 php-fpm 24759 /rc.newwanipv6: rc.newwanipv6: on (IP address: 2001:1680:104:1:1::580b) (interface: wan) (real interface: re1). Oct 3 09:05:03 php-fpm 24759 /rc.newwanipv6: Removing static route for monitor fe80::290:bff:fea2:b929 and adding a new route through fe80::290:bff:fea2:b929%re1I went to the WAN interface and changed the IPv6 configuration type from DHCP6 to None. After that, the log doesn't have the lines above, and the firewall GUI seems more responsive - including actually running the update as expected. The interface which these APUs connect to on WAN does have DHCP6 activated.
I'm not promising that the DHCP6 config is perfect on the external pfSense box which servers as the DHCP server the for APUs, but the APUs basically had the default settings - something must be off somewhere?!
Updated two devices let's see how they run now. There's no hardware fault though, it seems.
-
All right, I'm now sure of when the crashes are provoked, I just have no idea what is causing them.
I have the following version installed:
2.5.0-DEVELOPMENT (amd64) built on Mon Oct 14 00:22:51 EDT 2019 FreeBSD 12.0-RELEASE-p10Furthermore, I have the FRR package installed, verion 0.6.3_1. Each of the four test firewalls is configured to connect via IPSec to two other units, in a "circle" configuration. On top of IPSec, they are configured with Phase 2 VTI and OSPF Routing.
The important setting is "IPv6 Configuration Type" for the WAN interface. It this is set to DHCP6, as it was by default, the firewalls crash regularly. If it is set to "None", there are no crashes (or at least they are so infrequent that I haven't seen them yet). Also, as described above, DHCP6 causes a lot of log entries and blocks updates.
Crash log attached:
fw3_20191014.zipIt's not impossible that the IPv6 config on the upstream pfSense box dealing as the WAN gateway and DHCP server is not ideal - but in any case, a misconfiguration here shouldn't cause crashes IMHO.
I can share config backups if needed, since this is a test system. I'm also fine with doing any more tests, but I don't know what.