Another XMLRPC communication error
-
Hi there,
I try now for second day to configure a HA installation of pfSense on a hetzner cloud and fail badly.
This message appears on sync attempts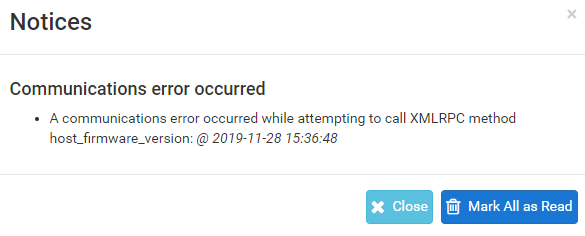
Both firewalls are same (2.4.4_3), both run on same hardware in a hetzner cloud.
Configuration synchronization between master and slave doesn't work for unknown reason.
Synchronisation goes via a dedicated interface (192.168.4.0/24 ... master and slave in a /28 subnet, see picture). Both are reachable.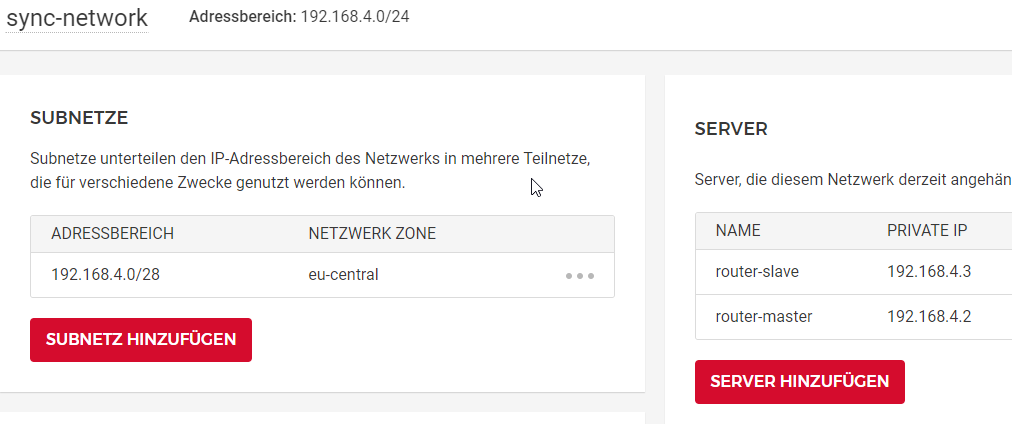
Rules for the SYNC interface are defined on both sides like this

User is 'admin' and Passwords are on both sides correctly for sure.Any idea what I missed maybe? Any help would be appreciated.
Kind regards,
Michael -
@mse said in Another XMLRPC communication error:
User is 'admin' and Passwords are on both sides correctly for sure.
But can they ping each other via Sync interface? (and I'd enable ICMP on Sync, too)
-
Thanks for your response. Ohhh... they seem to not to see each other...
Changed rules on both sides
(any ICMP for simplicity... at now)
And ping from master to slave fails.
PING 192.168.4.3 (192.168.4.3) from 192.168.4.2: 56 data bytes
--- 192.168.4.3 ping statistics ---
3 packets transmitted, 0 packets received, 100.0% packet lossHmm...
The interface seems to be configured correctly... or is the /32 CIDR wrong here?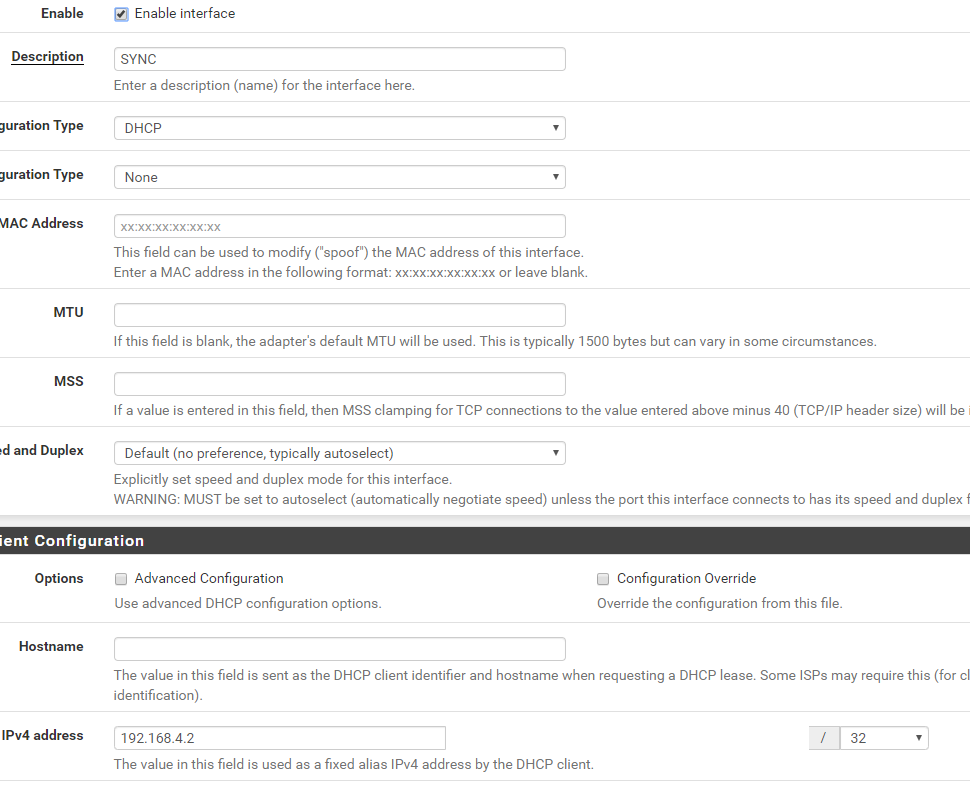
At console all interfaces seem to be OK too. On other side same. Only different adresses in same subnets.

Gateway is on SYNC interface comming from DHCP and is 192.168.4.1 I think.
Really, this drives me crazy slowly.


-
Perhaps, the SYNC Adresses are at System -> Advanced -> Admin Access -> Alternate Hostnames too.
-
OK, ping works. And the message changed now to
A communications error occurred while attempting to call XMLRPC method host_firmware_version: Unable to connect to tls://192.168.4.3:443. Error: Operation timed out @ 2019-11-28 16:53:47
-
Then you can't connect to the webgui there. Is the other side set to run the webgui on https/443?
What happens when you use Diagnostics > Test Port to test 192.168.4.3 port 443?
What is logged on the secondary in the system and maybe firewall logs?
There is also zero reason to pass the CARP protocol on the sync interface. See the sticky post in this category for explanations. If anything you should be passing pfsync, not CARP.
-
@mse said in Another XMLRPC communication error:
The interface seems to be configured correctly... or is the /32 CIDR wrong here?
/32 is wrong, you need at least a /30 or /29 to set up the net between the two nodes.
Set node 1 to 192.168.4.1/30 and the other to 192.168.4.2/30 and it should work. I'd use a ICMP any any rule for testing so to not run into problems with sync_net or sync_address.
With using the correct subnetting perhaps your XMLRPC error will vanish, too.
Also don't understand how you use DHCP but manually configure an IP in the fields below. Should simply be Static IP IMHO. And how are those other interfaces (WAN/LAN) able to work with each other if you configure them as /32? You have to use the correct netmask of the subnet, not a single IP /32. How else should node 1 be able to reach its peer on LAN/WAN when trying to speak CARP? That setup seems very buggy.
-
@Derelict
Thanks. The admin UI is running at 443. Port-Ping works and I can see log entries for synchronisation attempts too (all green). But the sync message is still failure.A communications error occurred while attempting to call XMLRPC method host_firmware_version: @ 2019-11-29 08:39:53

I set the rule for CARP following this
https://vorkbaard.nl/how-to-set-up-pfsense-high-availability-hardware-redundancy/I'm new to the funky firewall business
 I try to find a solution to secure a public cloud.
I try to find a solution to secure a public cloud.
Or better to say to turn a cloud with public IPs on the nodes to a private one, where only
some edge nodes are accessible. All traffic among the nodes goes trough private network and doesn't leave the box. Of course, I could apply rules for ufw to block all traffic at any port on the public network, but thie solution with a firewall sounds for me more sexy.
My idea is:- Install a private network (works fine)
- Put router/firewall (HA in any case) in front of the nodes (current topic)
- Turn off public IPs (works too)
- Provision the nodes (Key management system, Rancher cluster, Kubernetes cluster and storage
)
If things work I can document and roll up the configuration on another cluster of nodes to prepare a production system. For now its an experiment, to get familiar with this topic and to avaluate if I'm riding a dead horse or not.
-
@JeGr
Ohh ja, its a very small network with /32 CIDR. Actually its an /24 and the two pfSense nodes are in a /28 subnet (/30 would do too). WAN is DHCP with additional floating IPs which are static.
WAN and LAN work fine.
Not sure if this is the right place to configure them (Alias IPv4 address in interface configuration) but the WAN addresses of the pfSense nodes have additional floating IPs. -
It seems not to work at all (on this hardware?) or I'm missing something essential.
I don't see any reason why it doesn't work.-
Both pfSense instances are up to date (first thing done after activating WAN)
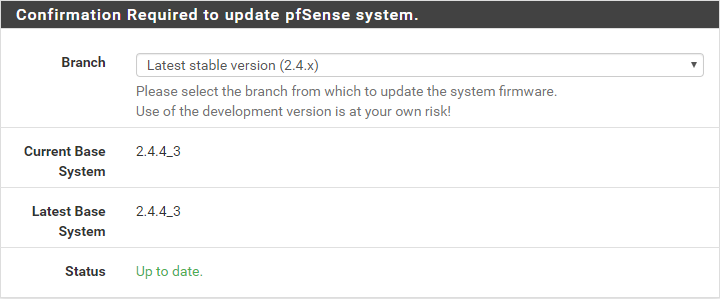
-
Interfaces
WAN -> DHCP (works)
LAN -> DHCP (works) 10.70.64.0/21 (pfSense in subnet /24)
SYNC -> DHCP (works) 192.168.4.0/24 (pfSense in subnet /29)
pfSync-Master has IP: 10.70.64.2 (LAN), 192.168.4.2 (SYNC)
pfSync-Slave has IP: 10.70.64.3 (LAN), 192.168.4.3 (SYNC)- Rules on both sides on the SYNC interface wide open
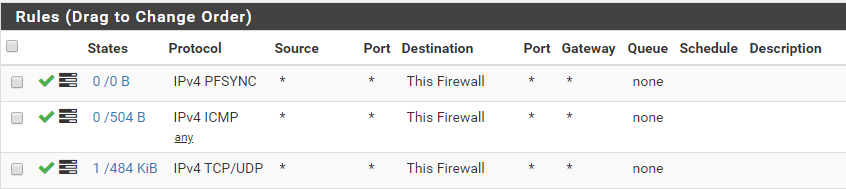
-
Port-Ping from Master to Slave works fine
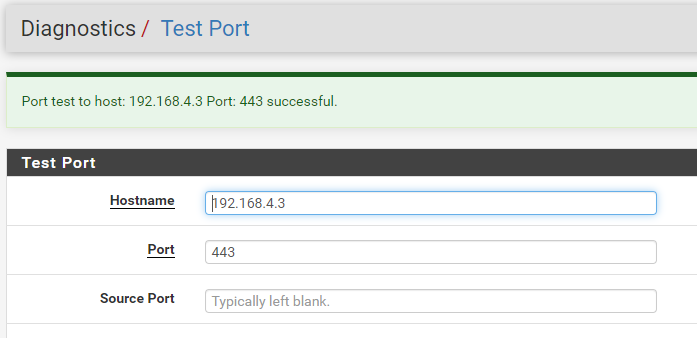
-
XMLRPC fails always
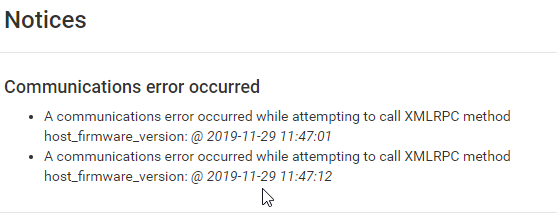
-
Logs on target site contain successful connection attempts

-
Logs on source site contain following messages
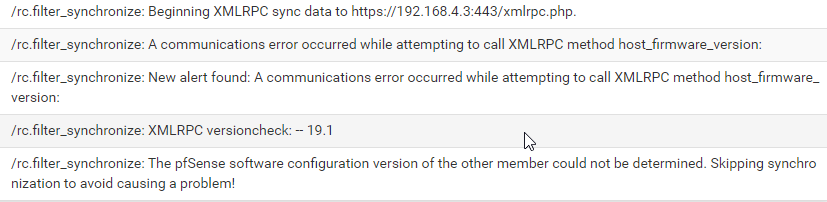
-
-
What is logged on the secondary?
-
i have issue the same.
you resolved it, please help me -
@Derelict
Tried it today again. Same errors. On secondary the only noticeable log entry is maybe this from nginxNov 30 10:24:17 router-slave.localdomain nginx: 2019/11/30 10:24:17 [error] 65828#100098: send() failed (54: Connection reset by peer)
But nothing special in /etc/log/nginx/error.log to identify the reason.
-
Perhaps, I see people fight this issues for years now

https://forum.netgate.com/topic/122196/high-avail-sync-broken/19
Didn't find any solution by now. Tried IPFire but its a joke in comparison to pfSense. There is no HA available at all. Good to protect the own toaster maybe but not in production clusters. -
Well it works for many, many people, me included. You have something configured incorrectly or something wrong in your environment.
If it was me and I was stuck, I would pcap the exchange and see exactly what was happening.
-
@Derelict
Sure, maybe the reason are the virtual networks at Hetzner. Really I can't figure out, why it's not working. It fails checking the results of the xml rpc invocation
I took a look at the code of the 'host_firmware_version' function and tried it separately in script... all values (OS version, config version etc.) are there and can be parsed as expected. I give up. I think a scripted solution using iptables, UCARP and BGP should do too. At least I can install this things unattended using terraform.Anyway. Thank you very much for your time and suggestions.


-
@mse said in Another XMLRPC communication error:
the virtual networks at Hetzner
Which are know for some "specialities" in IP "black-magic" and nasty /32 PtP routing etc. so that could very well be a case of it not working the way it should.
Did you try (just as a test) using LAN or even WAN as syncing interface just for fun? Perhaps that additional "private subnet" you use as SYNC isn't functioning correctly. Had some hassle with the new Hetzner vCloud in the past, too, as I was trying to setup IPv6 between two instances. One worked flawlessly, the other was bugged as hell. Only after opening a ticket and putting them through the hoops, they discovered the VM host where the second and buggy VM ran was incorrectly configured and thus not 100% IPv6 compatible... After they fixed, everything ran smooth.
-
@JeGr
Yes, it can drive one really crazy. UCARP doesn‘t work, because all floating IPs need to be attached to a physical node. I think using keepalived and a script to reasign the floating IP and ‚default route‘ to the slave in the virtual network should work. To switch between master and slave I had only to assign the floating IP (used as external IP of the network) to the slave and adjust the route for 0.0.0.0/0 to the slave as gateway. All traffic is routed via slave.
It works fine doing simple routing with UFW and turning the public IP off but I don’t trust this construct.
IPv6 was fun too with Ubuntu 18.04... i tried today Wireguard but failed for some reason... The interfaces stop to forward traffic when IPv6 is active on wireguard interface.
I didn’t understand why... found this here
https://angristan.xyz/fix-ipv6-hetzner-cloud/
but the cloudinit network configuration seems to be fixed in current version of the ISO... Hmm... I am beekeeper in my next life for sure. Really, whole week only issues with everything. Perhaps. pfSense on public interface synchronizes without any problems... but of course, not a good idea I suppose
Really, whole week only issues with everything. Perhaps. pfSense on public interface synchronizes without any problems... but of course, not a good idea I suppose -
@mse I have the same exact problem with hetzner Cloud , the same as you.
After two days of trying to sync 2 nodes of pfsense (ver 2.4.5-1), I gave up , and try to look for another solution.
I must say that I appreciate heztner for there stability and there service.
But you can't win them all.Best regards ,
Koby Peleg Hen -
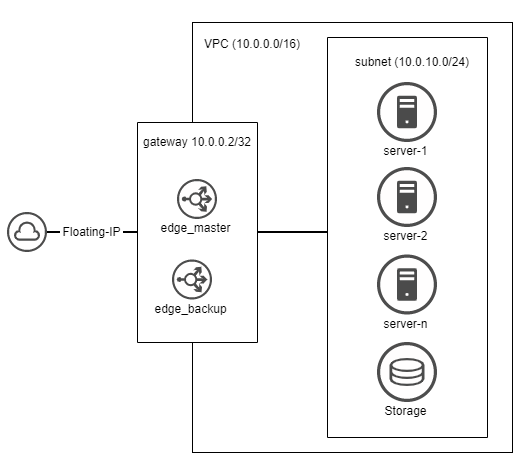
@koby-peleg-hen
By now hetzner supports loadbalancer and routing into virtual 'private' networks. But you need to allow at least outgoing traffic on public interfaces to be able to get anything from outside the cluster.
Two years ago I solved this using two edge nodes (the only once with public interface activated) in a HA setup with keepalived, ufw, nginx as reverse proxy and floating IP reassignment on node failures.
It looks like this:
This works fine but today I would use the loadbalancer instead and only limit the access of the nodes over public IPs.