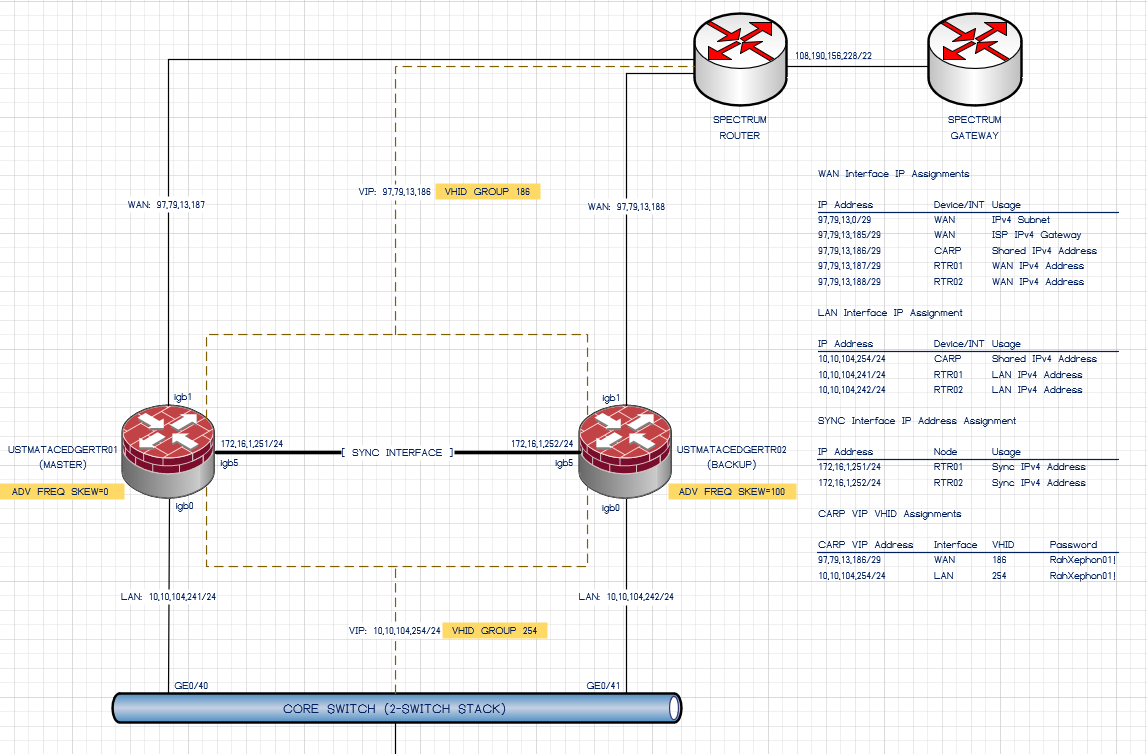
[image: 1760762744141-28314b2f-5d26-45d9-b6ae-381f978856b4-image.png]
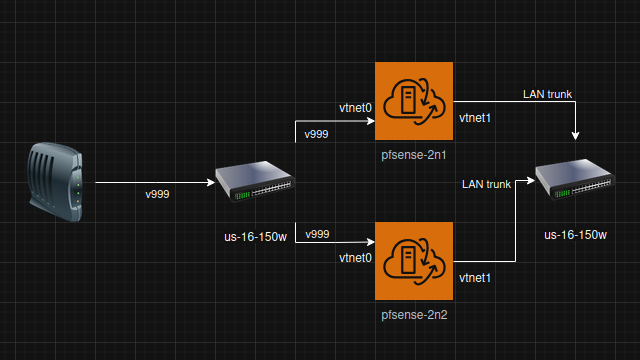
[image: 1760762785716-ee139398-adef-4d64-8ce4-bba8cce70782-image.png]
config-pfSense.home.arpa-20251018044835.xml.zip u/p=admin/pfsense
In case you are installing in the VM just import the machine into the Virtualbox, and install 2.8.1, then apply configuration.
pfsense28_small_export.7z
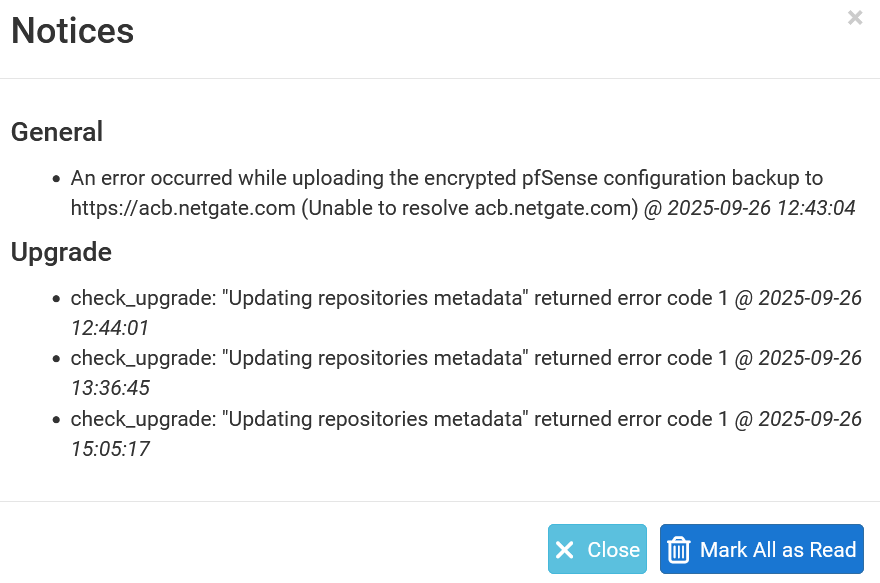
Should be resulted in:
[image: 1760763171045-f75dffbe-bbb2-4f11-87bb-4739d1928c76-image.png]
vtnet0: flags=1008943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
description: wan2
options=900b8<VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,VLAN_HWFILTER,LINKSTATE>
ether 08:00:27:9d:bc:aa
inet 10.0.2.15 netmask 0xffffff00 broadcast 10.0.2.255
inet6 fe80::a00:27ff:fe9d:bcaa%vtnet0 prefixlen 64 scopeid 0x1
inet6 fd17:625c:f037:2:a00:27ff:fe9d:bcaa prefixlen 64 autoconf pltime 14400 vltime 86400
media: Ethernet autoselect (10Gbase-T <full-duplex>)
status: active
nd6 options=23<PERFORMNUD,ACCEPT_RTADV,AUTO_LINKLOCAL>
vtnet1: flags=1008843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
options=4800bb<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,LINKSTATE,TXCSUM_IPV6>
ether 08:00:27:f9:2b:76
inet6 fe80::a00:27ff:fe9d:bcaa%vtnet1 prefixlen 64 scopeid 0x2
media: Ethernet autoselect (10Gbase-T <full-duplex>)
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
vtnet2: flags=1008843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
description: SYNC
options=800b8<VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,LINKSTATE>
ether 08:00:27:77:b8:2c
inet 10.0.222.1 netmask 0xffffff00 broadcast 10.0.222.255
inet6 fe80::a00:27ff:fe77:b82c%vtnet2 prefixlen 64 scopeid 0x3
media: Ethernet autoselect (10Gbase-T <full-duplex>)
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
vtnet3: flags=1008843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
options=4800bb<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,LINKSTATE,TXCSUM_IPV6>
ether 08:00:27:42:e3:96
inet6 fe80::a00:27ff:fe9d:bcaa%vtnet3 prefixlen 64 scopeid 0x4
media: Ethernet autoselect (10Gbase-T <full-duplex>)
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
vtnet4: flags=1008802<BROADCAST,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
options=4c07bb<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,TSO4,TSO6,LRO,VLAN_HWTSO,LINKSTATE,TXCSUM_IPV6>
ether 08:00:27:67:ea:41
media: Ethernet autoselect (10Gbase-T <full-duplex>)
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
enc0: flags=0 metric 0 mtu 1536
options=0
groups: enc
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
lo0: flags=1008049<UP,LOOPBACK,RUNNING,MULTICAST,LOWER_UP> metric 0 mtu 16384
options=680003<RXCSUM,TXCSUM,LINKSTATE,RXCSUM_IPV6,TXCSUM_IPV6>
inet 127.0.0.1 netmask 0x0
inet6 ::1 prefixlen 128
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x7
groups: lo
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
pflog0: flags=100<PROMISC> metric 0 mtu 33152
options=0
groups: pflog
pfsync0: flags=1000041<UP,RUNNING,LOWER_UP> metric 0 mtu 1500
options=0
syncdev: vtnet2 syncpeer: 10.0.222.1 maxupd: 128 defer: off version: 1400
syncok: 1
groups: pfsync
lagg0: flags=1008843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
description: LAN
options=4800bb<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,LINKSTATE,TXCSUM_IPV6>
ether 08:00:27:42:e3:96
hwaddr 00:00:00:00:00:00
inet 192.168.1.1 netmask 0xffffff00 broadcast 192.168.1.255
inet6 fe80::a00:27ff:fe42:e396%lagg0 prefixlen 64 scopeid 0xa
inet6 fe80::1:1%lagg0 prefixlen 64 scopeid 0xa
laggproto failover lagghash l2,l3,l4
laggport: vtnet3 flags=5<MASTER,ACTIVE>
groups: lagg
media: Ethernet autoselect
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
lagg1: flags=1008843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
options=4800bb<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,LINKSTATE,TXCSUM_IPV6>
ether 08:00:27:f9:2b:76
hwaddr 00:00:00:00:00:00
inet6 fe80::a00:27ff:fef9:2b76%lagg1 prefixlen 64 scopeid 0xb
laggproto failover lagghash l2,l3,l4
laggport: vtnet1 flags=5<MASTER,ACTIVE>
groups: lagg
media: Ethernet autoselect
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
vtnet0.87: flags=1008943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
description: wifiap
options=80000<LINKSTATE>
ether 08:00:27:9d:bc:aa
inet 10.0.87.2 netmask 0xffffff00 broadcast 10.0.87.255
inet 10.0.87.5 netmask 0xffffff00 broadcast 10.0.87.255 vhid 3
inet6 fe80::a00:27ff:fe9d:bcaa%vtnet0.87 prefixlen 64 scopeid 0xc
inet6 fe80::1:1%vtnet0.87 prefixlen 64 scopeid 0xc
groups: vlan
carp: MASTER vhid 3 advbase 1 advskew 254
peer 224.0.0.18 peer6 ff02::12
vlan: 87 vlanproto: 802.1q vlanpcp: 0 parent interface: vtnet0
media: Ethernet autoselect (10Gbase-T <full-duplex>)
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
pppoe0: flags=1008851<UP,POINTOPOINT,RUNNING,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1492
description: WAN
options=0
inet6 fe80::a00:27ff:fe9d:bcaa%pppoe0 prefixlen 64 tentative scopeid 0xd
groups: pppoec
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>