-
We run 2x XG-7100 pfSense boxes in High Availability.
Every night, between 12:00 am - 12:30 am the boxes failover, then failback.
Why? Or how can I find out why? I have looked in the logs and it just tells me they failed over and then failed back.
I don't believe it is supposed to be doing this.
-
Are there any package updates running around that time?
Is the failover the whole half hour or do you mean it happens at some point in that half hour? Maybe try pinging them from the WAN side during that window to ensure they actually drop offline?
-
@teamits no package updates during that time, this has been happening daily since we put this in last Christmas.
And this happens at some point between 12 and 12.30, it never lasts long, usually it's just seconds. It fails over then immediately fails back.
I know this as I get emails every night from pfSense.
-
What is in the logs? Status > System Logs, System, General would be where I look first.
-
@Derelict Thought I looked there before and just saw the switch over, but upon closer inspection, I see that 2 ports are dropping then reconnecting. They shouldn't be though.
I have a 4 Port addon card in each box, that has igx0-3. this is set up as LACP to 4 separate switches (2 that overlap with the second box) to a 6 switch stack.
The switches have never been down but I did notice I didn't have all the ports plugged in and not in the right spots either.
Have just corrected this so now both are 100% running on a 4 port LACP each.
Now the waiting game and see what happens tonight.
-
@eangulus So that didn't fix anything.
The 4 Ports are dropping out on the LACP. Yet the 6 Switch ERS5000 stack is always up and always running. I know this 100% as I have systems that are running thru the same switches that are very sensitive to drops. And they are not having issues.
Here is my logs:
Feb 20 00:32:20 check_reload_status Reloading filter Feb 20 00:32:20 php-fpm 13149 OpenVPN PID written: 68959 Feb 20 00:32:20 kernel ovpns1: link state changed to UP Feb 20 00:32:20 php-cgi notify_monitor.php: Message sent to support@krc.com.au OK Feb 20 00:32:20 check_reload_status Carp backup event Feb 20 00:32:20 kernel carp: 1@lagg1: INIT -> BACKUP (initialization complete) Feb 20 00:32:20 kernel carp: 1@lagg1: BACKUP -> INIT (hardware interface up) Feb 20 00:32:20 kernel ifa_maintain_loopback_route: deletion failed for interface lagg1: 3 Feb 20 00:32:20 kernel ifa_maintain_loopback_route: deletion failed for interface lagg1: 3 Feb 20 00:32:20 check_reload_status Carp backup event Feb 20 00:32:20 php-fpm 24358 /rc.newwanip: rc.newwanip: on (IP address: 10.0.0.251) (interface: LAN[lan]) (real interface: lagg1). Feb 20 00:32:20 php-fpm 24358 /rc.newwanip: rc.newwanip: Info: starting on lagg1. Feb 20 00:32:20 php-fpm 13149 /rc.carpmaster: Starting OpenVPN server instance on WAN because of transition to CARP master. Feb 20 00:32:20 php-fpm 13149 /rc.carpmaster: HA cluster member "(192.168.1.250@lagg0.4090): (WAN)" has resumed CARP state "MASTER" for vhid 250 Feb 20 00:32:19 check_reload_status rc.newwanip starting lagg1 Feb 20 00:32:19 php-fpm 57785 /rc.linkup: Hotplug event detected for LAN(lan) static IP (10.0.0.251 ) Feb 20 00:32:19 php-fpm /rc.carpbackup: HA cluster member "(10.0.0.250@lagg1): (LAN)" has resumed CARP state "BACKUP" for vhid 1 Feb 20 00:32:19 check_reload_status Reloading filter Feb 20 00:32:19 kernel carp: 250@lagg0.4090: BACKUP -> MASTER (preempting a slower master) Feb 20 00:32:19 check_reload_status Carp master event Feb 20 00:32:19 kernel igb3: link state changed to UP Feb 20 00:32:19 check_reload_status Linkup starting igb3 Feb 20 00:32:19 kernel igb2: link state changed to UP Feb 20 00:32:19 check_reload_status Linkup starting igb2 Feb 20 00:32:18 kernel igb1: link state changed to UP Feb 20 00:32:18 check_reload_status Linkup starting igb1 Feb 20 00:32:18 check_reload_status Linkup starting lagg1 Feb 20 00:32:18 check_reload_status Carp backup event Feb 20 00:32:18 kernel lagg1: link state changed to UP Feb 20 00:32:18 kernel carp: demoted by -240 to 0 (interface up) Feb 20 00:32:18 kernel carp: 1@lagg1: INIT -> BACKUP (initialization complete) Feb 20 00:32:18 kernel igb0: link state changed to UP Feb 20 00:32:18 check_reload_status Linkup starting igb0 Feb 20 00:32:17 kernel ovpns2: link state changed to DOWN Feb 20 00:32:17 php-fpm 24358 OpenVPN terminate old pid: 29823 Feb 20 00:32:16 php-fpm 24358 /rc.carpbackup: Stopping OpenVPN server instance on WAN because of transition to CARP backup. Feb 20 00:32:16 kernel ovpns1: link state changed to DOWN Feb 20 00:32:16 php-fpm 24358 OpenVPN terminate old pid: 8959 Feb 20 00:32:16 php-fpm /rc.carpbackup: Stopping haproxy on CARP backup. Feb 20 00:32:16 php-fpm 24358 /rc.carpbackup: Stopping OpenVPN server instance on WAN because of transition to CARP backup. Feb 20 00:32:16 php-fpm 24358 /rc.carpbackup: HA cluster member "(192.168.1.250@lagg0.4090): (WAN)" has resumed CARP state "BACKUP" for vhid 250 Feb 20 00:32:16 php-fpm 57785 /rc.linkup: Hotplug event detected for LAN(lan) static IP (10.0.0.251 ) Feb 20 00:32:16 php-fpm /rc.carpbackup: HA cluster member "(10.0.0.250@lagg1): (LAN)" has resumed CARP state "BACKUP" for vhid 1 Feb 20 00:32:16 check_reload_status Reloading filter Feb 20 00:32:16 check_reload_status Reloading filter Feb 20 00:32:15 check_reload_status Carp backup event Feb 20 00:32:15 check_reload_status Linkup starting lagg1 Feb 20 00:32:15 check_reload_status Carp backup event Feb 20 00:32:15 check_reload_status Linkup starting igb3 Feb 20 00:32:15 check_reload_status Linkup starting igb2 Feb 20 00:32:15 check_reload_status Linkup starting igb1 Feb 20 00:32:15 kernel ifa_maintain_loopback_route: deletion failed for interface lagg0.4090: 3 Feb 20 00:32:15 kernel carp: 250@lagg0.4090: MASTER -> BACKUP (more frequent advertisement received) Feb 20 00:32:15 kernel lagg1: link state changed to DOWN Feb 20 00:32:15 kernel carp: demoted by 240 to 240 (interface down) Feb 20 00:32:15 kernel carp: 1@lagg1: MASTER -> INIT (hardware interface down) Feb 20 00:32:15 kernel igb3: link state changed to DOWN Feb 20 00:32:15 kernel igb2: link state changed to DOWN Feb 20 00:32:15 kernel igb1: link state changed to DOWN Feb 20 00:32:15 kernel igb0: link state changed to DOWN Feb 20 00:32:15 check_reload_status Linkup starting igb0 Feb 20 00:31:13 SuricataStartup 70192 Suricata START for LAN(60231_lagg1)... Feb 20 00:31:12 SuricataStartup 67851 Suricata START for VDSL(50234_lagg0.4090)... Feb 20 00:31:12 php-cgi [Suricata] The Rules update has finished. Feb 20 00:31:12 php-cgi [Suricata] Suricata has restarted with your new set of rules... Feb 20 00:31:10 SuricataStartup 56185 Suricata STOP for LAN(60231_lagg1)... Feb 20 00:31:08 SuricataStartup 45638 Suricata STOP for VDSL(50234_lagg0.4090)... Feb 20 00:31:07 php-cgi [Suricata] Building new sid-msg.map file for LAN... Feb 20 00:31:07 php-cgi [Suricata] Enabling any flowbit-required rules for: LAN... Feb 20 00:31:05 php-cgi [Suricata] Updating rules configuration for: LAN ... Feb 20 00:31:04 php-cgi [Suricata] Building new sid-msg.map file for WAN... Feb 20 00:31:04 php-cgi [Suricata] Enabling any flowbit-required rules for: WAN... Feb 20 00:31:02 php-cgi [Suricata] Updating rules configuration for: WAN ... Feb 20 00:31:02 php-cgi [Suricata] Removed 0 obsoleted rules category files. Feb 20 00:31:02 php-cgi [Suricata] Hide Deprecated Rules is enabled. Removing obsoleted rules categories. Feb 20 00:30:56 php-cgi [Suricata] Snort GPLv2 Community Rules file update downloaded successfully. Feb 20 00:30:48 php-cgi [Suricata] There is a new set of Snort GPLv2 Community Rules posted. Downloading community-rules.tar.gz... Feb 20 00:30:47 php-cgi [Suricata] Snort rules file update downloaded successfully. Feb 20 00:30:11 php-cgi [Suricata] There is a new set of Snort rules posted. Downloading snortrules-snapshot-29150.tar.gz... Feb 20 00:30:10 php-cgi [Suricata] Emerging Threats Open rules file update downloaded successfully. Feb 20 00:30:05 php-cgi [Suricata] There is a new set of Emerging Threats Open rules posted. Downloading emerging.rules.tar.gz... -
If it is always after the Suricata rule reload it is probably more-related to Suricata taking the interface down than it is to HA/CARP. It looks like it is just doing what it should do if/when the interface drops.
-
So is Suricata supposed to be taking the interfaces down?
-
Are you saying that these are always coincident with a Suricata rule update?
-
@Derelict seems to looking at the logs.
-
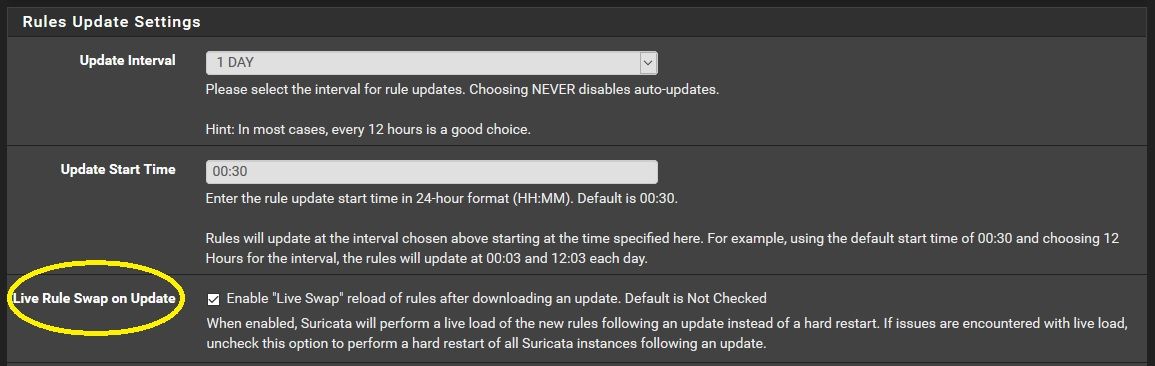
00:30 is the default rule update start time for suricata
suricata will do a hard reset unless you tick
Live Rule Swap on Update
̿' ̿'\̵͇̿̿\з=(◕_◕)=ε/̵͇̿̿/'̿'̿ ̿
Please do not use chat/PM to ask for help
we must focus on silencing this @guest character. we must make up lies and alter the copyrights !
Don't forget to Upvote with the 👍 button for any post you find to be helpful. -
Probably this: https://redmine.pfsense.org/issues/9934
-
@kiokoman said in HA Failover occurs like clockwork, why?:
00:30 is the default rule update start time for suricata
suricata will do a hard reset unless you tick
Live Rule Swap on Update
@kiokoman is correct. Checking the option to perform a Live Rule Swap will not restart the binary and should prevent cycling of the physical interface. Note this does require more RAM for a short period as two complete copies of the enabled rules have to exist in RAM during the swap over.
Killing of the physical interface is expected when using Inline IPS Mode as netmap will cycle the physical interface when it is enabled, but loss of the physical interface is not expected for Legacy Blocking Mode which uses libcap. The fact starting/stopping a PCAP binding on an interface is causing it to cycle down is unexpected. I am investigating what might be the cause as a result of the Redmine Issue @jimp posted a link to.
-
@eangulus said in HA Failover occurs like clockwork, why?:
We run 2x XG-7100 pfSense boxes in High Availability.
Every night, between 12:00 am - 12:30 am the boxes failover, then failback.
Why? Or how can I find out why? I have looked in the logs and it just tells me they failed over and then failed back.
I don't believe it is supposed to be doing this.
Can you check something for me and report back the results?
-
First, are you running with Inline IPS Mode or Legacy Mode Blocking enabled? If Legacy Mode, then continue with the steps below.
-
Go to SYSTEM > ADVANCED and then the Network tab and scroll down to the hardware settings for CSO, TSO and LRO. These are the hardware NIC offloading options. Tell me if they are currently checked or not checked?
-
If not checked, can you check those options to force offloading to disabled, restart Suricata on all interfaces and then see if the problem with HA Failover happens again at the next midnight interval?
To clarify the steps above, when using the "Live Rule Swap" option, Suricata is not restarted upon a scheduled rules update. With this option disabled (which is the default), then Suricata is restarted at the end of a rules update job.
When using Inline IPS Mode blocking, the
netmapdevice is used and that device will always cycle the physical interface when it is bound to the interface. So the stop/start cycle of Suricata will result in bouncing the physical interface when using Inline IPS Mode. There is no workaround for this. It is just hownetmapworks.When using Legacy Mode blocking, the
libpcaplibrary is used. This does not normally result in cycling of the physical interface when the PCAP binding is enabled. However, Suricata has built-in code within the binary that will poll the physical interface to check the status of checksum offloading. If not disabled, the binary will make a FreeBSDioctl()call to disable checksum offloading. When Suricata is stopped, another system call is made to restore the original checksum offloading state. I'm thinking maybe this forcing of the checksum offloading may result in a restart of the physical interface (causing a "down" then "up" cycle). That's why I want to know the current state of those settings on your box. -
-
@kiokoman said in HA Failover occurs like clockwork, why?:
00:30 is the default rule update start time for suricata
suricata will do a hard reset unless you tick
Live Rule Swap on Update
That was it. Turned on live update and last night was the first time the failover didn't happen.
Problem solved. Thanks.
Copyright 2025 Rubicon Communications LLC (Netgate). All rights reserved.