-
Hi experts,
I am running PFSense, latest 2.4.5_1 on bunch or ALIX APU2/4 boards for 3+ years and I just love it. I am using OpenVPN tunnels to connect to several remote locations, UDP4, shared keys, hw encryption... nothing special and it just works for years...However last sunday I came to a situation which I was unable to resolve and namely understand and I need your help and advice. I will try to be as brief as possible.
The problem is that a connection to one particular site suddenly "nearly stopped working". I was installing all kinds of systems in a remotely connected location (both pfsense on my and their side same version 2.4.5_1, openvpn tunnel), spent several weeks daily connected for several hours without any problem. At one moment the connection became nearly unusable - I am able to connect to SSH to pfsense or any remote ssh enabled server or to some simple web interfaces on the remote site like proxmox web ui, also pfsense connection works but is way slower than usual (about 10 times slower), but other remote web sites like HP ILO 4/5 pages, unifi web UI, RDP gateway web site, FreeNAS web UI barely load in 10 minutes or so and are unusable. The same applies to RDP, which is the core of my work there. That basically never load. Tested RDP to any remote server, not just one.
Now comes the facts:
-
I can perfectly connect to the same remote pfsense openvpn without any problem when I use my iphone, MacBook or ubuntu ntb on LTE (completely outside my home network/pfsense), once iPhone, linux or MacBook is back on my network/pfsense (both wifi/lan) it fails again - so I believe it relates to my home pfsense, not the remote one.
-
I have two WANs on my pfsense and it does not matter which one I use for connection (by force disabling either WAN) - both WANs fail, Primary wan is wifi connection, the backup is LTE. So I do not think it relates to my provider.
-
tried all kind of restarts (all servers, all pfsense boxes) no luck
-
when I visit physically the remote site and connect to local network with the same my computer I use at home, all just works blazing fast. So I assume it is not in my computer.
-
at the time when it started to fail I was not doing any changes on neither pfsense box - both were untouched for several days. I even tried to restore about a week old backups of both pfsense boxes.
-
I have the same setup on other remote pfsense boxes and networks, nearly identical and they keep working - same version of pfsense, same remote servers and services, they work for years...
Now I hope I told you maximum I know and I would like to hear some of your ideas. So far I believe that there is some issue with some bigger packets perhaps? SSH and simple webs are OK, but complex RDP does not, but I have no idea how to prove it. Tried to adjust MTU to 1400, 1300, 1200 on WAN and on OpenVPN, no result. Also tested and check DNS, setup, use only one on the Pfsense box, all addresses resolve as expected...
The thing is there is no obvious error, no error message, it just looks like if I was on old 2400 baud modem or so...
What is the biggest miracle for me, why suddenly without touching it it stopped.
So I understand it is very complex and hard to nail down, but perhaps you can have similar experience If some logs are needed, please name them, I will post it.
-
-
It does sound like an MTU issue. Have you tested the tunnel MTU with large ping packets? How were you setting it for the tunnel? You should be using mssfix in the custom options for failing TCP traffic like that.
Try running pcaps at both ends (if you can) and see what's actually arriving compared to what is sent.
Steve
-
Thanks stephenw10,
it was also my assumption. For now I have UDP tunnel, I will need to set-up second one as TCP as well to be able to compare, which will take some time due to the speed of work :)For now I tested many combinations of
mssfix 1200
tun-mtu 1200with other values as well (1300, 1400, 1450) and it did not bring any positive results.
Also testing with larger pings (up to 4096) The results are as you would expect the smaller package the higher returns rate, starting with around 1280 to 4096 it did not either run at all or just a very few after a long time... The biggest reliable was 1270.
MBP:~ me$ ping 192.168.100.1 -s 512 PING 192.168.100.1 (192.168.100.1): 512 data bytes 520 bytes from 192.168.100.1: icmp_seq=0 ttl=64 time=53.226 ms 520 bytes from 192.168.100.1: icmp_seq=1 ttl=64 time=63.117 ms 520 bytes from 192.168.100.1: icmp_seq=2 ttl=64 time=63.599 msMBP:~ me$ ping 192.168.100.1 -s 1270 PING 192.168.100.1 (192.168.100.1): 1270 data bytes 1278 bytes from 192.168.100.1: icmp_seq=0 ttl=64 time=56.684 ms 1278 bytes from 192.168.100.1: icmp_seq=1 ttl=64 time=50.721 ms 1278 bytes from 192.168.100.1: icmp_seq=2 ttl=64 time=33.393 msAlso tested to my second reference remote site with exact same setup and I was getting same results - 1024 was the largest reliable one, no return with 2048-4096. Still this site works as expected.
For the packet capture, I will have to be on site, so I won't be able to do it now.
I am desperate :(
Anyway thank you, so far the best hit :) -
There should be no need to use a TCP VPN, UDP is almost always better. mssfix should apply to the traffic over it.
That doesn't sound good though.
Try pinging to the same site, over the same route the VPN is using, but outside the tunnel. Make sure you can ping with reasonable packet sizes there without loss.
We have sometimes seen issues with packet fragments not being correctly reassembled as they leave the OpenVPN daemon. In those cases assigning the interface can help as it changes how/where pf applies pfscrub. I would try assigning the interfaces at both ends. However be aware that will require you restart the OpenVPN service after doing it. You will lose connectivity until you do.
Steve
-
To exclude another bunch of possible reasons : skip the VPN part.
Connect to the (a) remote site, put in place some RDP NAT rules to some internal devices. You could use your own WAN IP in the rule as a source, which will exclude any security issues.
Now test.
If the speed is ok, you know it's a VPN only issue.
Still issues : it's the 'road' to the remote side, not the VPN. -
@Gertjan THANKS a lot for your input.
I have created a NAT and rule on the remote site to allow direct 3389 port translation and it behaves the exactly same way, I can barely initiate the security handshake, the RDP stays for long minutes on the welcome and eventually in 10+ minutes it opens a desktop, but I am unable to move mouse/windows.Again when tasing from my computer/phone directly over mobile data, it works blazing fast.
So this is to exclude the remote pfSense box for sure and also my home end devices.
Also as I can still be connected to the other older pfSense remote site and use RDP absolutely without any issue, I would also exclude the provider/lines.
I am now more convinced that the problem is my home pfSense. It starts to behave strange enough to reinstall it entirely. When rebooting or restoring configuration, I cant make it to load the pfblocker rules any more, it simply seems it has corrupted enough to be freshly reinstalled.
-
@stephenw10 I will also try to follow your advices before I entirely reinstall my box from fresh USB, will need to wait for the evening for users leaving the remote site.
Just to make sure I follow your advice, by "assigning" the interfaces you refer to the page "/interfaces_assign.php" to delete the assignment and assign them again?
-
@keson said in Unexplainable trouble with OpenVPN connection - beer for tip to fix it :):
When rebooting or restoring configuration
take note : we all share the pfSense 'core' files. What makes our system different, and as much a s "works great" up untill "doesn't work" is ... the config.
So, re installing, using the same config ... yields the same result.This is one of the reasons why you should you keep your setup as simple as possible. This enables you to create a new system from scratch if needed without takes hours to set it up.
Also : rdp traffic is as any other type of traffic, pfSense doesn't care less. It's handled with the same speed as all other traffic. Except if you are filtering using 'snort' etc
-
If the OpenVPN instances are already assigned as interfaces assigning them again will not do anything. They do not need to be assigned though, if they are not already assigned then I was suggesting assigning them. And yes on the Interfaces > Assign page.
If you see the same issue outside the tunnel it's unlikely to be a VPN issue anyway though.. It's possible it could be something at the firewall at one end or it could be something in the route between them. I would still try to find what size packets you can send across that outside the tunnel and whether you see packet loss there.
It's common to see ruleset alerts from pfBlocker aliases before it has loaded and populated them. That's not normally a problem, the rules will load once pfBlocker updates the alias.
Try going to Status > Filter Reload and forcing a reload. If you see new ruleset alerts at that point it's a problem.Steve
-
Gentleman, thansk for your feedbacks!
I do absolutely share this approach and like keeping things simple. I do not use any special setups, a bunch of port forwards to a bunch of services running at my home network, acme for letsencrypt certificates, pfblockerng to keep intruders out of my home allowing only few IPs in and remote access for my country and couple of openvpn servers connections. And a list of resolvers for all my internal servers to call them by names and not ips... Apart from that no hooks, no diverts or hacks, nothing.
I took now 2 months old backup (I do weekly backups) and I can say at least the pfblocker is healthy again. The system reported reinstalling packages which never went away due to a lock and I found in processes that it was a squid package which kept the system in installation phase (I have to confirm, that in past 2 months all my pfSense boxes behaved the same - squid does not update/reinstall to the final expected "green" status) so I killed the installation and uninstalled squid completely. After that and after several reboots the system does "look ok" again.
I have checked all the settings and mostly I found the cause, but it will take me 4 more days to find out.
This is my theory:
-
I have a primary WAN (a local net provider) and a secondary WAN (pcie LTE card with sim card). It seems there is a FUP limit on the card and most likely I run out of data. That woudl explain why it worked all the time in past weeks and "suddenly" stopped working.
-
Now you might ask, why do I use the secondary WAN and not the primary one. That is still a bit of a mystery for me - both WANS are in a group for failover (packet loss or high latency and tier 1 and 2) so basically the primary GW for a local provider shall always be used... Here comes the thing. All my other pfsense boxes are connected to all kinds of providers, but the one which I am talking about here is on the same provider. Lets say my ip address is 109.72.10.20 and the other box is 109.72.20.30. To me it seems like if my pfsense box automatically always uses the LTE secondary GW. When I mark the second LTE GW as down, I cant get to the remote server at all.
So my conclusion is that from some routing reason (I did not create any static routes, all are created by the system automatically...) whenever I want to go to my remote pfsense box hosted by the same provider as mine, I am taking the LTE path, where due to FUP applied I get not through. I guess it is because my IP address and the remote address are on the same B subnet. Just guessing.
Attached is the image of my routes.
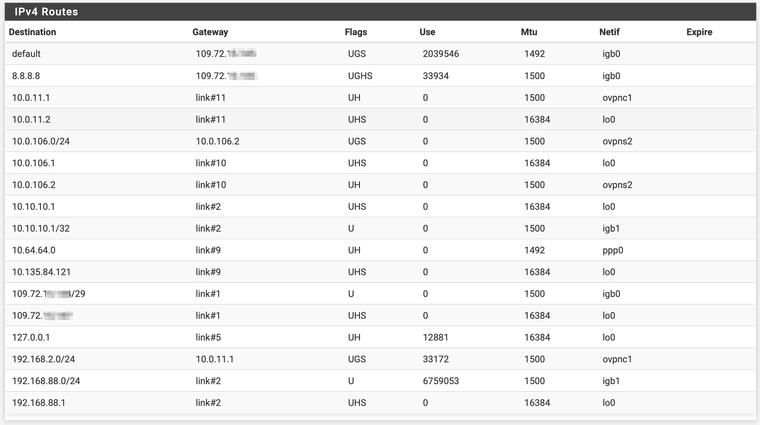
And how did I found out?
When I connect to the OpenVPN I could see on the remote box in currently connected clients my ip which is dynamic (from Vodafone) and not my fixed public IP:
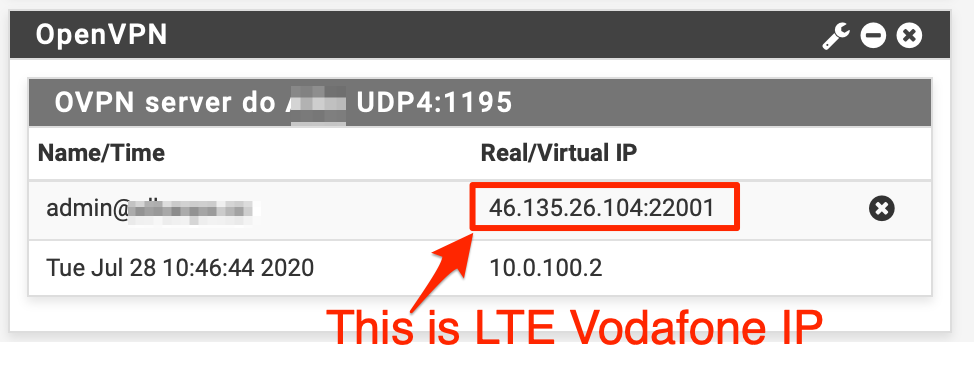
So I do expect, that once the FUP is reset, I will again be able to work.
I do thank to all of you for your ideas, I have learned many new things again from you guys! And I am sorry for not identifying the routing problem at the very beginning, those are the things I simply take as granted and do not even dare to question that.
P.S. If I can resolve the issue with routing to the remote site over my primary GW, it would perhaps resolve sooner. Would a static route help?
P.P.S. Yes, I have the primary GW as my default GW.
P.P.P.S. The pings to remote site behaved exactly the same way over VPN and outside vpn, because all go through the secondary LTE GW (now I know).
-
-
How is the server configured? Which interface is it listening on?
It's possible to have it listening on both WANs using a group or port forwards.
Is the remote client also configured to use an interface group?
It's possible to end up with the tunnel on the LTE WAN if the main WAN was down when it came up. It will not move back when the WAN comes back up, that does not break established connections.
If you had CGN and the twi devices were actually inside the same subnet then I could imagine it might choose to use that as a source. It's hard to imagine they are though. None of those IPs are CGN specific. And carriers do not normally allow internal connections between clients.
Steve
-
@stephenw10 Thanks steve for your reply,
Both server and client (server is the remote pfsense box, my side is the client) have the OpenVPN server/client listening/originating on the primary WAN interface. (the remote side has no other WAN interface, just one there).So the remote server does not use any interface group.
I have also created another OpenVPN for remote access exactly the same - both originating and listening interface is the primary WAN.
I have also tested all combinations of originating the connection form the interface group.
The Question related to the LTE WAN not switching back to the primary WAN also came to my mind, but I have rebooted / restored the whole box so many times and even disabled the LTE WAN entirely. As soon as I switch off the LTE, i get no connection - no ping to the remote site. The connection drops.
I have simplified everything to bare minimum, disabled all vpns and anything what could interfere, switched off LTE, set only one gateway, the primary one.
As soon as the LTE goes down I get no ping:
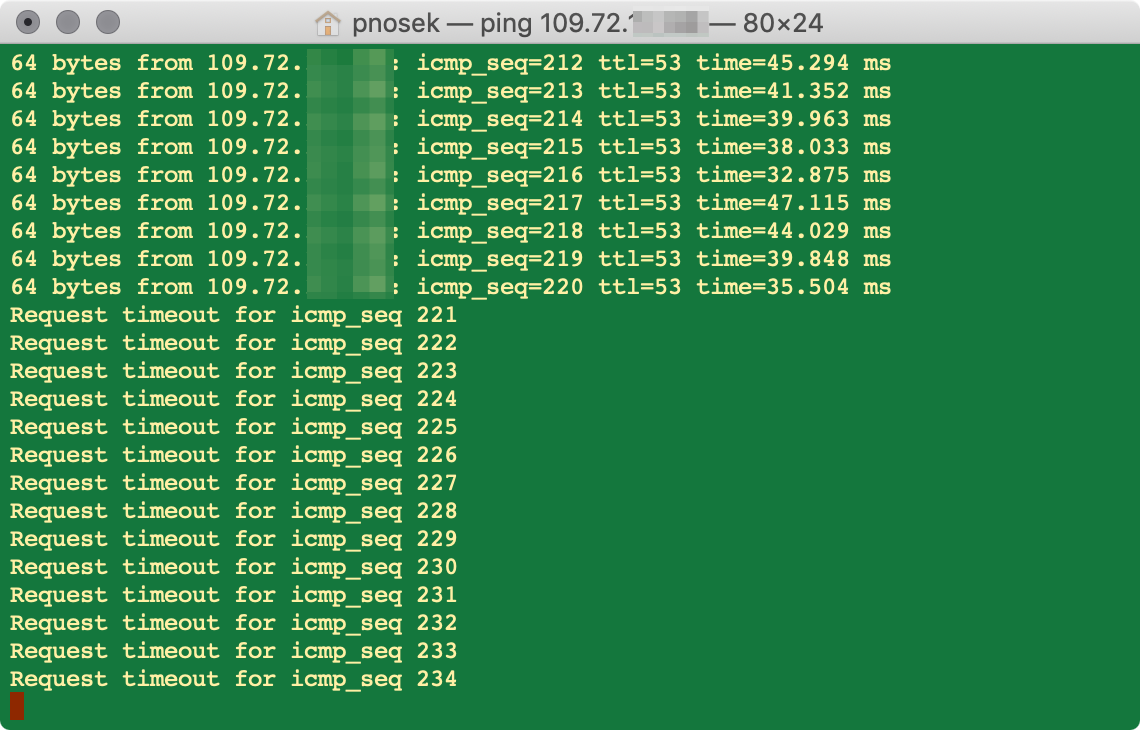
The interfaces look like this:

and the routes are also much simpler:
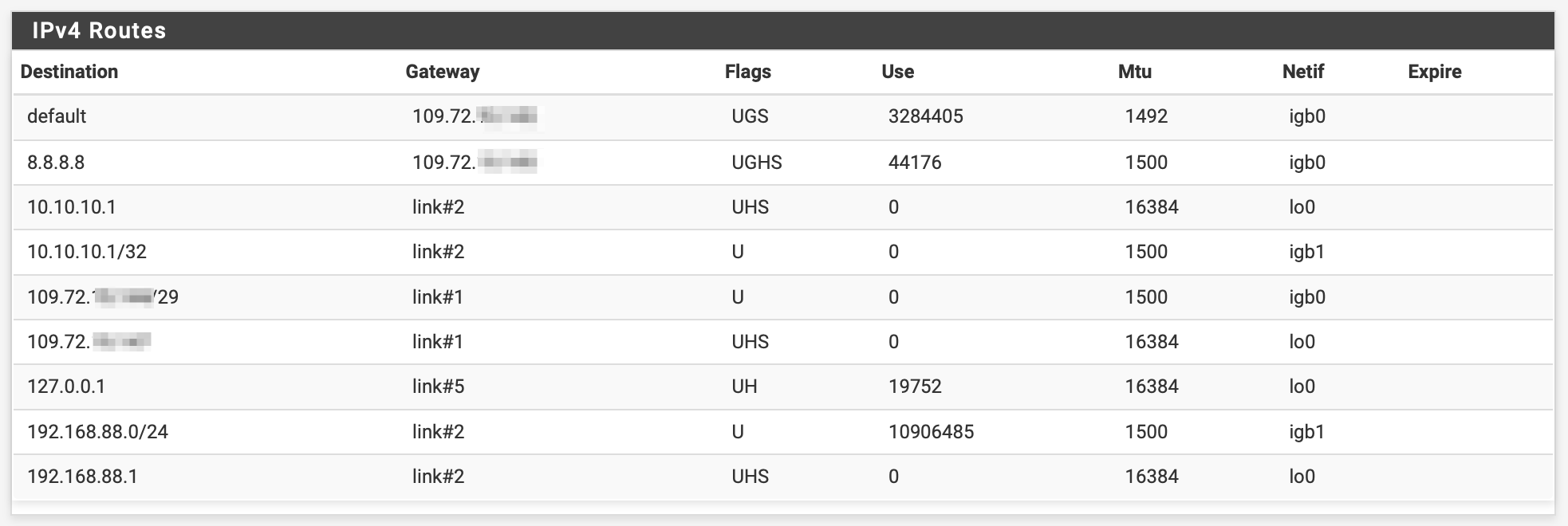
With this bare setup I can not ping the remote 109.72.xx.xx from my 109.72.yy.yy
I am nearly convinced that there is no error in pfsense logic nor configuration but the nature of this setup. Or perhaps even more: the internet provider is blocking this on the way... I can ping the gateway, but not the target and the trace route also ends:
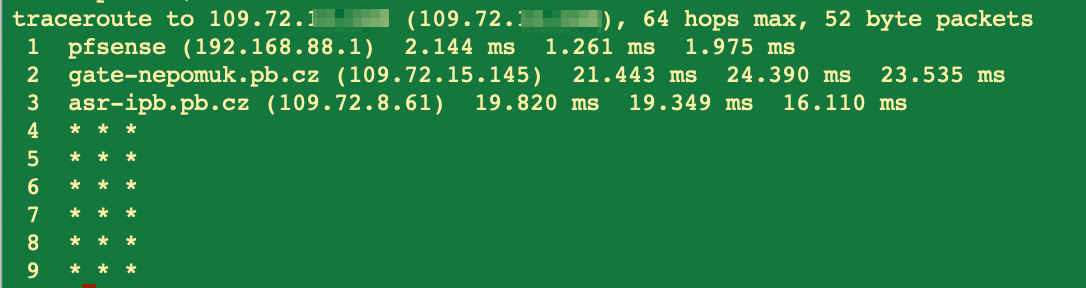
As you said, the career does not allow communicating between their end users.
And I am also nearly sure that as soon as my LTE sim card will be reset for FUP, I will be able to work again.
Steve, thank you for your great effort. I am rally grateful for all advices from you and @Gertjan.
-
So the tunnel stays up but somehow traffic across stops?
Or more like you lose connectivity to the other site entirely...
Like it's blocked in your ISP somehow.
The client then must have some failover setup, like two remote statements, since the WAN gateway would not go down.
STeve
-
@stephenw10 The tunnel drops as soon as I kill the secondary WAN. And it does not reconnect/connect any longer. PING also drops.
So yes, it must be the ISP blocking it.
The client (me) have the failover, which basically was what I was using without noticing it. As I had a plenty of data left on LTE and I really didn't check the other side what IP I am coming from, I simply setup a tunnel, it connected and I never really questioned it.
So it first failed when the failover was "out of data" and it created this whole thread.It is always the best path to figure out what it is and confirm, there is no mystery.
I owe you guys beer, whenever you stop in CZ, you are welcome :) Accommodation as a bonus ! -
So two remote statements with different binding IPs on the client?
I would not expect a failover group to come into play here as the WAN is not actually down, it's just that route that fails.
You might try switching to a TCP tunnel or using a different port. If something it deliberately blocking OpenVPN there it may pass it.
It could be an over-matching ACL at the ISP blocking traffic between any of their internal client IPs somehow. Not much you can do about that...
Steve
-
Good morning,
As of 1.8. I can confirm that the secondary WAN is up and working ”as before” - the FUP was reset.So it really is a ISP “feature” - they block access between their clients. So thanks to my multi WAN setup i was not aware of this limitation and “suddenly” i experienced that once the secondary WAN was not working thanks to the applied FUP.
Thanks to all of you for your support.
Copyright 2025 Rubicon Communications LLC (Netgate). All rights reserved.