pfSense WAN connection hangs after about a minute
-
Greetings everyone
I'm a new user to the forums, but a long time pfSense user. Recently though, I've run into a strange issue that I can't figure out.
I recently purchased a Protectli Vault to replace an ancient desktop (also running pfSense as a VM) as my gateway router. I had no trouble setting up pfSense, but I've run into this issue where my WAN connection (500/100 FTTD connection using PPPoE) initially comes up okay, but just freezes after a minute or so. The PPPoE connection still shows as up, but no traffic flows after that initial minute or so, not even pings from pfSense to the WAN. If I manually cycle the WAN connection then it runs for another minute before freezing again and I have no idea why.
I've tried all the performance tuning and troubleshooting tips found on https://docs.netgate.com/pfsense/en/latest/hardware/tune.html without success. Thinking it must be some kind of incompatibility between the 210AT NIC and Telco box, I returned my existing vault and purchased a 6 port vault with the older Intel 82583V chips. Same problem with the new vault.
I also tried other router software with mixed success. OPNSense has the same problem as pfSense. Sophos XG works great (so the issue isn't pure hardware), but doesn't support UPnP. ClearOS doesn't die, but only runs at about 2/3rds line speed (it typically shows 250-300Mb/s where pfSense and Sophos are showing the full 500Mb/s).
I know it's not pure hardware because Sophos XG and ClearOS don't have the stall problem, but it's not pure software because my old box still works like a champ. Any thoughts on what might be causing this odd issue? I'd really like to stick with pfSense as my firewall if I can.
-
Check the PPP logs, are you seeing anything showing when it's not passing traffic.
Run a pcap on the PPPoE WAN are you seeing anything? Gateway pings even?
Run a pcap on the PPPoE parent NIC (assign it if you have to) do you see anything there?
Anything in the system log?
What is the telco box? It doesn't show the Ethernet link go down I assume?
If it's exactly 60s each time that seems like a timeout somewhere, probably in PPPoE and should be logged.
Steve
-
It's not exactly 60 seconds that it goes down. It seems to be dependent on amount of traffic. Trying a speedtest will kill it almost immediately. The page will load, but then trying to connect to a server fails. Also, if I leave it alone for a few minutes it'll sometimes accept a little more traffic, but dies within seconds.
For the NIC, I can't see the telco NIC as it's inside the telco side of my fiber box but the NIC on the pfSense side shows as connected and the WAN connection shows as up.
System and PPP logs don't show any errors that I recognize. The only entry in the system log after startup is my kicking the NIC into promiscuous mode for the pcaps and the last entries in the PPP log are the connection coming up. No reconnection attempt or link down messages there.
For the pcaps, I'm not the best at reading these, but I do see packets in both of them.
The both the WAN and em0 port (the NIC underlying the PPP WAN) show motly DNS protocol packets from the WAN IP, but only a handful of responses. There are also a few TCP ACKed unseen segment packets. I'm not sure what those mean.
-
You see the gateway monitoring pings though? And replies?
Seeing ACKs to traffic you didn't see might be some sort of ARP issue.
We'll need to see the logs really I think.
Steve
-
That I can do. I've attached the PCAP files for both the WAN PPP port and em0 (the underlying WAN NIC).
-
Hmm, so those were taken after it stopped responding?
It looks like your WAN IP is in the carrier grade NAT range, is that expected?
There are no replies to any pings shown in either cap even to the WAN gateway IP. Those succeed before for the 1min before it stops responding though?
There is some reply traffic though. It looks as though something is exhausted somewhere in the route, like a state table maybe. If the local telco device is NATing I could believe that but it's very unlikely given PPPoE and CGN.
Bringing down the PPPoE session and reconnecting it allows traffic to flow for a further minute?
Do you get a different WAN IP every time it connects?Steve
-
Both of the pcaps are during the period that it isn't responding. And yes, sadly, they are using Carrier grade NAT IPs as my 'public' address. :(
Pings were working during the first few seconds to minute that the connection stays up.
Bringing down and reconnecting the PPPoE session does allow traffic to briefly flow again and I'll double-check, but I believe the IP does not change when I reconnect.
-
Just a theory, more a guess - but if your gateway stops answering pings.. Then yeah your gateway will go down..
That might explain why your XG and etc. doesn't fall down - if they are not monitoring via ping your connection? Or if they do it less often, maybe some sort of rate limiting being done?
Turn off monitoring and just set the gateway to always be up... Does that allow traffic to work for more than your 1 minute?
-
pfSense will still send traffic via that gateway as it's the default even if it's marked down. But obviously the gateway itself will have stopped responding for that to happen. It could indeed be upstream responding badly to the gateway pings.
As suggested edit the gateway in System > Routing > Gateways and disable monitoring for it.If that does prevent it going down you can adjust the monitoring settings there to ping a lot less frequently.
Steve
-
I can't test this yet but will as soon as I'm done with work for the day. Thanks for the suggestion.
-
I tried disabling gateway monitoring and it didn't affect anything. Before disabling it, dpinger does show errors in the log. Example:
send_interval 500ms loss_interval 2000ms time_period 60000ms report_interval 0ms data_len 1 alert_interval 1000ms latency_alarm 500ms loss_alarm 20% dest_addr 64.37.18.5 bind_addr 100.64.24.89 identifier "WAN_PPPOE "
Also, I was wrong about the IP staying the same when I disconnect and reconnect the WAN port. It does increment by one each time I cycle.
And I confirmed I could ping the WAN IP, i.e. 100.64.24.89 in my above example, even when no traffic was flowing any further.
Another oddity was keeping a ping to 8.8.8.8 going from just after I reconnected the WAN. It kept working even when the interface seemed to die, but pings to any other public IP were failing. That seems very odd to me.
I keep thinking this has to be something up stream, but if that were the case then the same hardware should fail with other OSs, or my current pfSense box shouldn't work if it's the software.
-
@fulkren said in pfSense WAN connection hangs after about a minute:
send_interval 500ms loss_interval 2000ms time_period 60000ms report_interval 0ms data_len 1 alert_interval 1000ms latency_alarm 500ms loss_alarm 20% dest_addr 64.37.18.5 bind_addr 100.64.24.89 identifier "WAN_PPPOE "
That is not an error, it's what dpinger logs when it starts showing what IPs it's running on and what values it's using.
If it is exhausting something, like a state table, in the ISP router then I would expect existing states to stay open and continue to pass traffic but new states to fail. That would normally include the gateway monitoring pings though.
You have any other hardware device you can test pfSense on?
Steve
-
@stephenw10 said in pfSense WAN connection hangs after about a minute:
That would normally include the gateway monitoring pings though.
Not always the case.. We just had this discussion awhile back about icmp and states.. While we all know icmp is actually a stateless protocol - most firewalls track it, via an entry in the state table.. Pf does this..
So pinging especially twice a second would most likely keep such tracking active and allowed.
But its possible whatever is upstream isn't tracking it at all? And if it was having state issues, maybe icmp doesn't hit whatever issue that is be it exhaustion or whatever.
To me It really comes down to this - if you see pfsense sending traffic upstream, and you get no answer - then the problem is upstream. If pfsense was malforming whatever its sending, why would it not be doing that for the whole time - and it wouldn't even work for a minute?
Your saying you can only ever get a connection for exactly 1 minute, and then it fails? exactly 1 minute, or it just happens often? But it far more likely that its something upstream if your seeing traffic sent upstream with no reply.
An intelligent man is sometimes forced to be drunk to spend time with his fools
If you get confused: Listen to the Music Play
Please don't Chat/PM me for help, unless mod related
SG-4860 25.07.1 | Lab VMs 2.8.1, 25.07.1 -
It's not exactly one minute. The time it takes to stop responding typically varies from a few seconds to about a minute and appears to depend on how much traffic I load on the interface. If I just run one ping to a single address it'll stay up for a while, but much more than that and it goes down.
As for other hardware, that's the part that confuses me most. My current pfSense box is a VM on an old EVGA i7 mobo with two onboard gigabit NICs (Realteks no less) and it's working perfectly. Same version of pfSense and exactly the same config as is failing on the Protectli Vault I purchased to replace it. The only config differences I made were testing each adjustment recommended in Netgate's troubleshooting and tuning document for Intel NICs.
I originally thought it was a hardware compatibility issue between my Telco box and the Intel 210AT NIC chipset on the Vault and swapped it out for a Vault with the older Intel 82583V chipset. Unfortunately I run into the exact same behavior on the new Vault (what I'm currently testing with). And it can't be purely hardware because running Sophos XG or ClearOS on the Vault does work (although ClearOS seems to have a lot of overhead and is unable to saturate the 500Mb/s line).
So the problem isn't purely software or purely hardware and appears to be the combination of the software and the hardware that causes the issue. Maybe the combination of the Intel based NICS and the driver(s) that pfSense uses?
-
if traffic continues to be sent upstream, and response stop to be seen. That screams upstream problem.. Do a sniff while your connecting so you collect all traffic being sent upstream and downstream... See if you can see any changes in the traffic being sent.. Wireshark for example would show errors and any packets that are malformed, etc.
-
@johnpoz said in pfSense WAN connection hangs after about a minute:
But its possible whatever is upstream isn't tracking it at all? And if it was having state issues, maybe icmp doesn't hit whatever issue that is be it exhaustion or whatever.
Yeah, that's a good point. Or maybe it requires a new state for each ping and therefore breaks when it stops being able to open new states. Which seems like what we're seeing here.
I could believe the pings themselves are exhausting it except disabling monitoring did not appear to help.
Steve
-
A sniff of the traffic should show us if new states are what are being denied, or if we are loosing responses to existing traffic, etc.
I am just having a hard time coming up with any sort of issue where pfsense would continue to send traffic, but malform it or change it in some way that the upstream didn't like.. Have never seen such thing ever..
Sure some device have hard time talking to each other - but this is normally seen in just basic negotiation of speed and duplex, etc. Not working fine for X amount of time, and then start having issues with just some traffic.
-
Sorry for the delay in responding. I did another packet capture on em0 (the NIC underlying the PPP connection). This time I started the packet capture with the WAN cable unplugged, plugged it in, and recorded until it died (about 35 seconds later). I don't see any malformed packets (that I recognize as such) but I do see some spurious re-transmissions as well as a small number of RST packets.
I've attached the PCAP (as much as the forum allows, about the first 8k packets out of 22k total). Anything stand out to you?
If not, then I'm down to calling the Telco and seeing if they can offer any advice. Though I expect their response to be essentially "use our provided router or get stuffed". Regarding which, their provided router is just an ancient D-Link DIR-825 with stock software. Nothing exciting there.em0-2020-10-21-1.zip
-
I don't see how that sniff is from before you connected.. It starts with a flood of DNS..
Why would you be sending a syn (tcp) to 53??
Also - clearly your missing start of conversations... This one for example
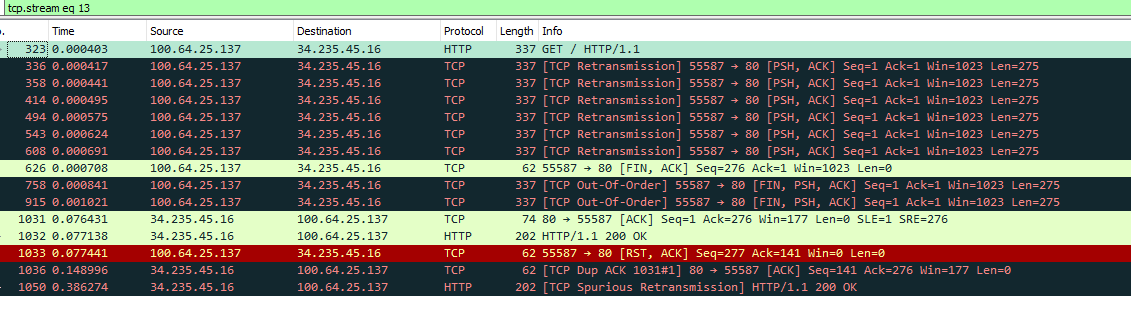
There is no syn here, you see sending http get, never getting a response.. So retran, then finally says screw it and sends fin.. Get a answer finally, then client side says screw it and sends RST..
But you never see the start of this conversation.
So how exactly did you start this sniff before you wan was even up? Make sure you clear all states if your going to do that again.. But default I believe is to flush all states when connection goes down, have you adjusted that setting?
Game is on - so that is my comments for now.. Will look later after the game, or maybe halftime
-
I haven't adjusted the settings for flushing states. And just to confirm I haven't accidentally borked anything up I have done a reset on the box settings and then re-configured for my local subnet, PPPoE connection, and DNS Resolver.
For the Sniff, my first attempt was to just unplug the WAN cable (LAN still plugged in), start the capture on WAN in promiscuous mode and then plug it back in. That just got me that flood of DNS packets as you saw. I also tried clearing states and then starting a pcap and, as quickly as I could, running "/usr/local/sbin/pfSctl -c 'interface reload wan'" from the shell but that seems to be giving me similar results to what I already posted.
Is there a better way for me to get good data during PPP startup?