My IPSEC service hangs
-
My IPSEC service seems to hang requiring a reboot for the page to load and every so often.
Also My existing Tunnels seem to disconnect and struggle to reconnect.
-
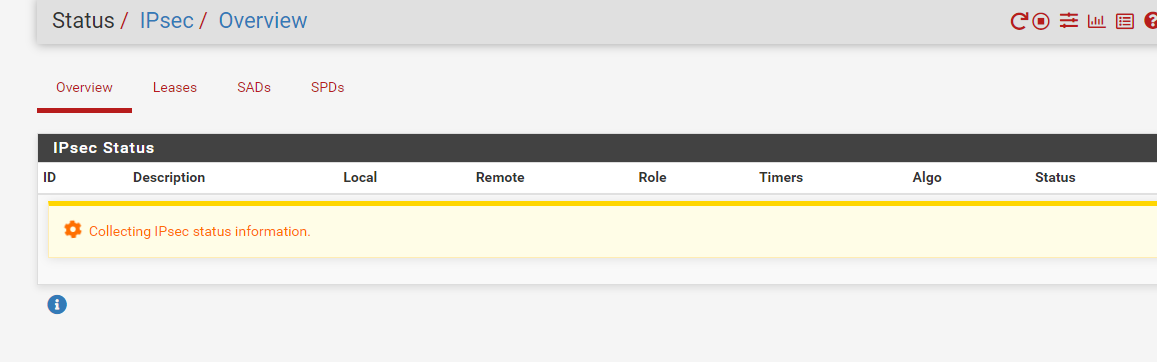
-
@auroramus I've seen this problem when the IPSEC log file reaches maximum size and the IPSEC service just hangs. I'm not sure if the logs rotate successfully or not, but rebooting is the only solution I've found to getting the service back. I've curtailed IPSEC logging to avoid this issue.
-
if it was a one of or every now and then i wouldnt mind but seems like i have to reboot it everyday.
-
I wonder if this is related to an issue I am having. When you are having the issue, if you run
netstat -Lanwhat is the output?In my case it seems to be a charon.vici overflow issue as the result shows "unix 4/0/3 /var/run/charon.vici". System logs also show an influx of sonewconn Listen queue overflow entries.
I believe the issue is related to this:
https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=262743 -
I'm also having the same issue. All IPsec VPNs will randomly go down and won't come back up unless I reboot the firewall. Sometimes they'll stay up for a day, but sometimes it happens multiple times per day (3 times today).
I've attempted manually reconnecting the VPNs via the IPsec status page and restarting the IPsec service, but neither of those end up doing anything and I'm forced to reboot the firewalls. When it happens, my system logs also show
sonewconn: pcb 0xfffff80095042200: Listen queue overflowentries. The process associated with that hex value always points to charon.The problem only appears to be happening on firewalls that have a lot of tunnels. Firewalls that only have a couple IPsec VPNs seem to be fine (thus far). All of the firewalls are running 2.6.0, but I've seen reports of people having the problem on some earlier versions as well.
I'd consider this a pretty serious issue, especially since IPsec VPNs can be considered a core component of firewalls and are heavily utilized throughout the industry. I'm almost at the point where I'm going to have to replace the firewalls with something else, since I can't keep having to reboot the firewalls throughout the day.
Hopefully this can be looked into and fixed. I'd be glad to provide any logs that may be needed.
-
@gassyantelope I've got a case open with Netgate support on this issue. They asked for a status output with IPSEC logging enabled when the appliance faults again.
-
@ablizno I'll check that when I submit my status output to Netgate. The odd thing is it only recently started, perhaps it is overall load related.
-
I have noticed it only occurs once the maximum amount of logs are hit so if set to 2000 and the logs reach that it crashes ipsec.
-
@auroramus Out of curiosity, where is the log setting you changed? I'm wondering if it is different than what I changed. I tried increasing the log space from 500KB to 20MB and still had the VPNs crash today within a few hours. So unless there is a different setting I missed, I'm thinking it may not be related.
-
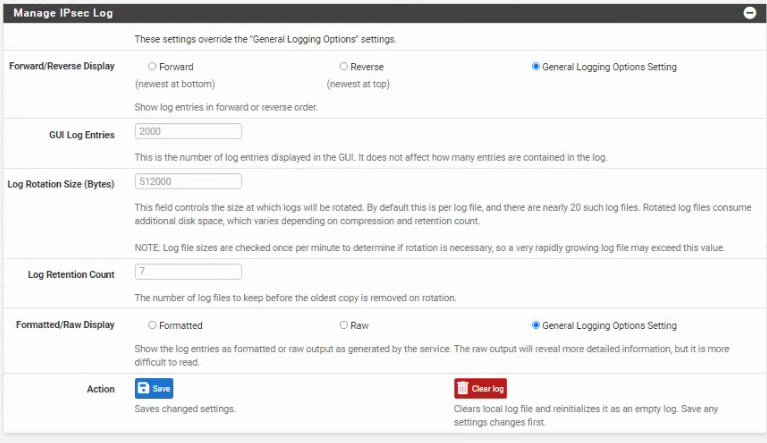
Hi so i go to Status>IPsec>
 >
>  and there you can set the log entries gui log entries i have set to 5 and left retention blank.
and there you can set the log entries gui log entries i have set to 5 and left retention blank. -
@glreed735 Hello, I am experiencing this exact same issue, see my log settings.
Have you received a resolution from support?
-
I do not have a support package in place.
-
@auroramus - Not yet, the first pass through the logs highlighted some issues, but they wanted a larger sample of data to work from pending the next failure.
-
I am no coding expert but it seems like once logs reach maxiumum capacity rather than overwriting the logs it crashes the ipsec service.
Thats what it looks like to me.
No matter what setting i change it to wether it is a low log count or high it maxes then kills service and unless you restart it will not work.
-
once i clear the logs i manage to go past the screen above i mentioned of collecting ipsec status info and see my connection but when you hit connect it attemps and stops doesnt do anything only way to get them connected back is restart
-
i also found this post;
This might be entirely normal behaviour; IPSec and many other forms of VPN tunnels connect only when there is traffic to transmit.
Take for example you have an 8 hour lifetime on the IKE (Phase 1) tunnel. The tunnel will connect upon some traffic being transmitted down the tunnel and will always terminate as soon as 8 hours has passed since it came up. Only if packets are still trying to be sent down the tunnel will the tunnel come back up again and continue transmitting traffic for another 8 hours. The down and up happens very quickly and packets may not even be lost. This is for security reasons to refresh the security associations.
Some people choose to run a ping or similar constantly down the tunnels so it always looks to be connected except for the brief milliseconds to reassociate. I find this to be generally unnecessary. -
@auroramus were you ever able to run
netstat -Lanand provide the output when all your tunnels are down? -
@auroramus The behavior occurring is definitely not normal. I understand what that post is saying and completely agree that is normal IPsec behavior. The issue here is completely different though. The tunnels will never come back up once they all go down. I can ping, send data another way, etc., and they won't ever come back up until a restart is performed.
I've had multiple cases where I had active connections over the tunnel (sending data the whole time) and then the issue occurs and all tunnels go down. This has occurred way before the default 8 hour life span (sometimes within an hour or two).
-
@gassyantelope Yes 100% the behaviour is wrong.
as it seems to crash the service. and this shouldnt happen.