NTP not working
-
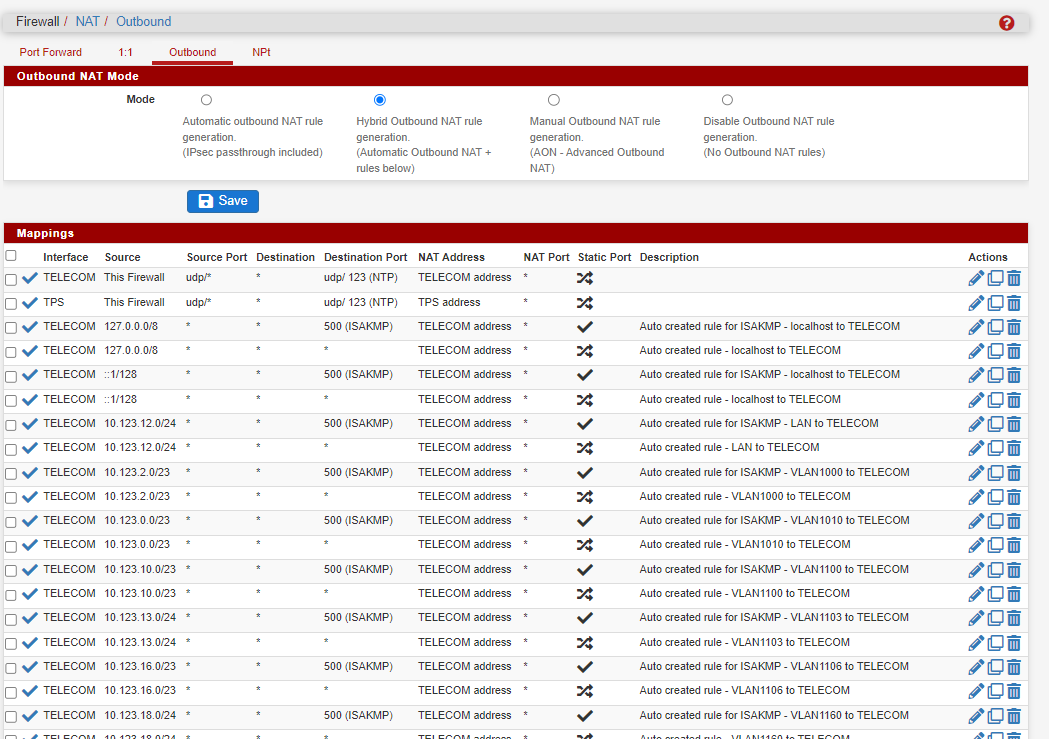
@dochy I might be missing something, but I don't see why those outbound NAT rules for NTP are required. Have you tried disabling them?
-
Have you tried a different pool?
-
@johnpoz said in NTP not working:
Not have a shitty connection? What non 377 reach that is not zero tell you is you send a ntp query and "sometimes" you get an answer.
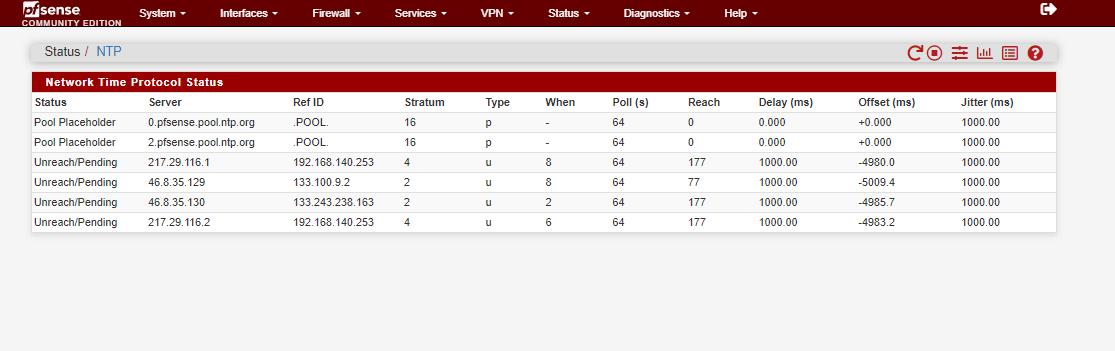
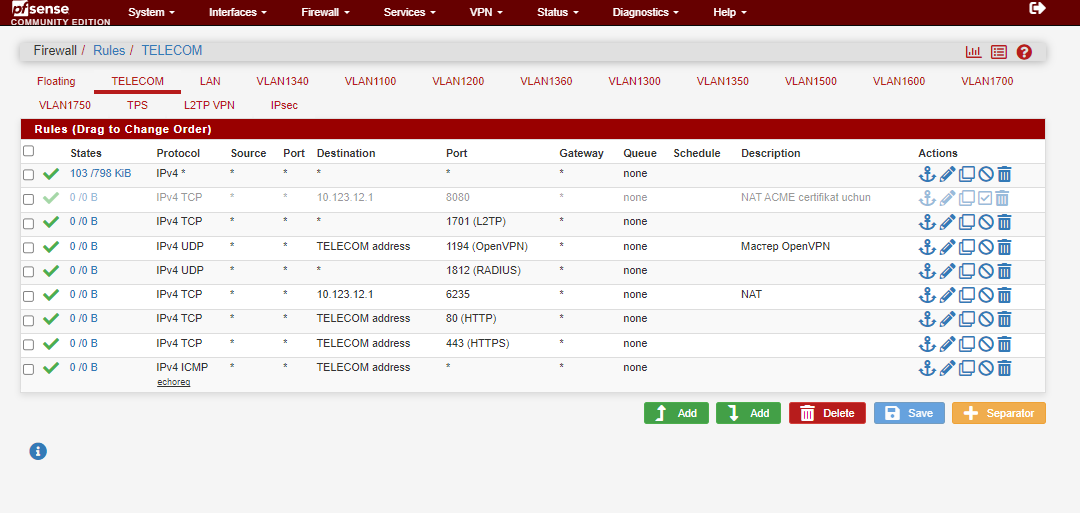
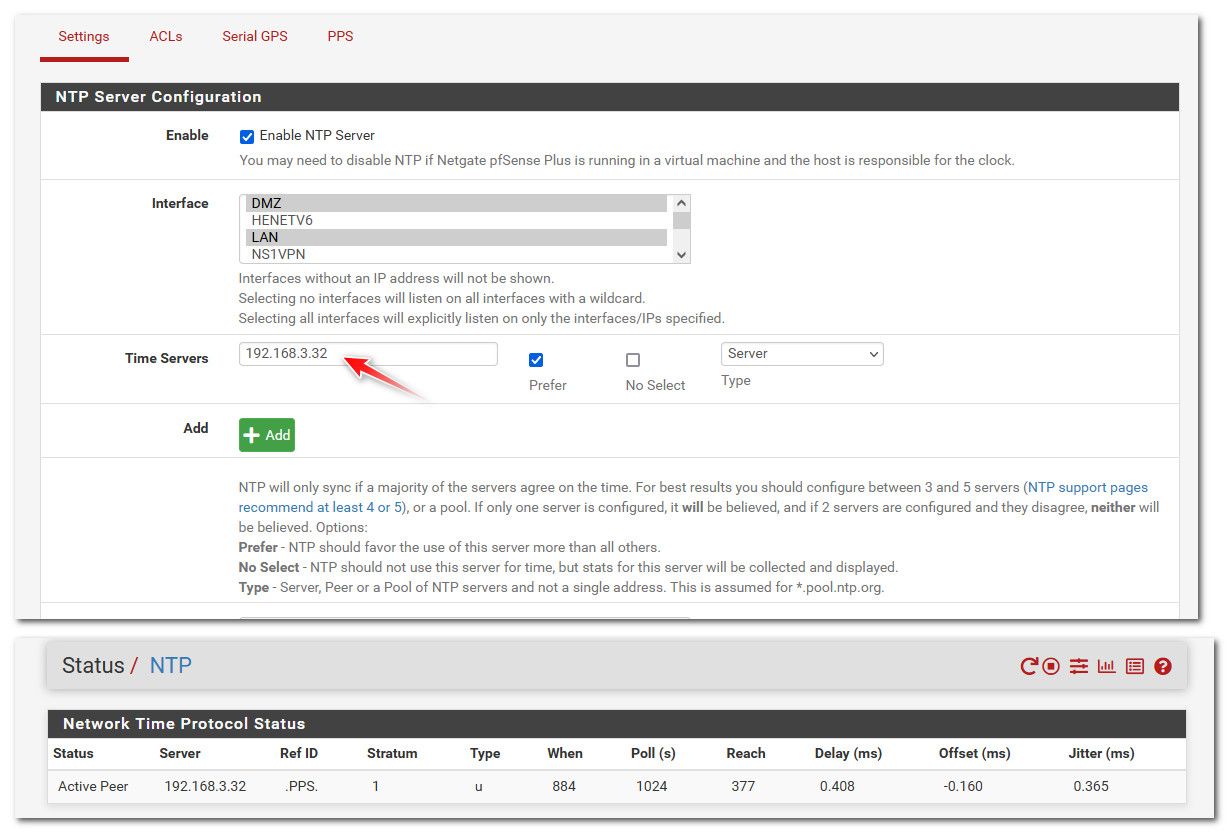
there are 3 ntp servers in my configuration, as you can see on pictures higher and 2 of them are local ntp servers in my network. If bandwith and latency are high why local servers are also unaviable?
P.S. my bandwith 120 mbps and here is traceroute time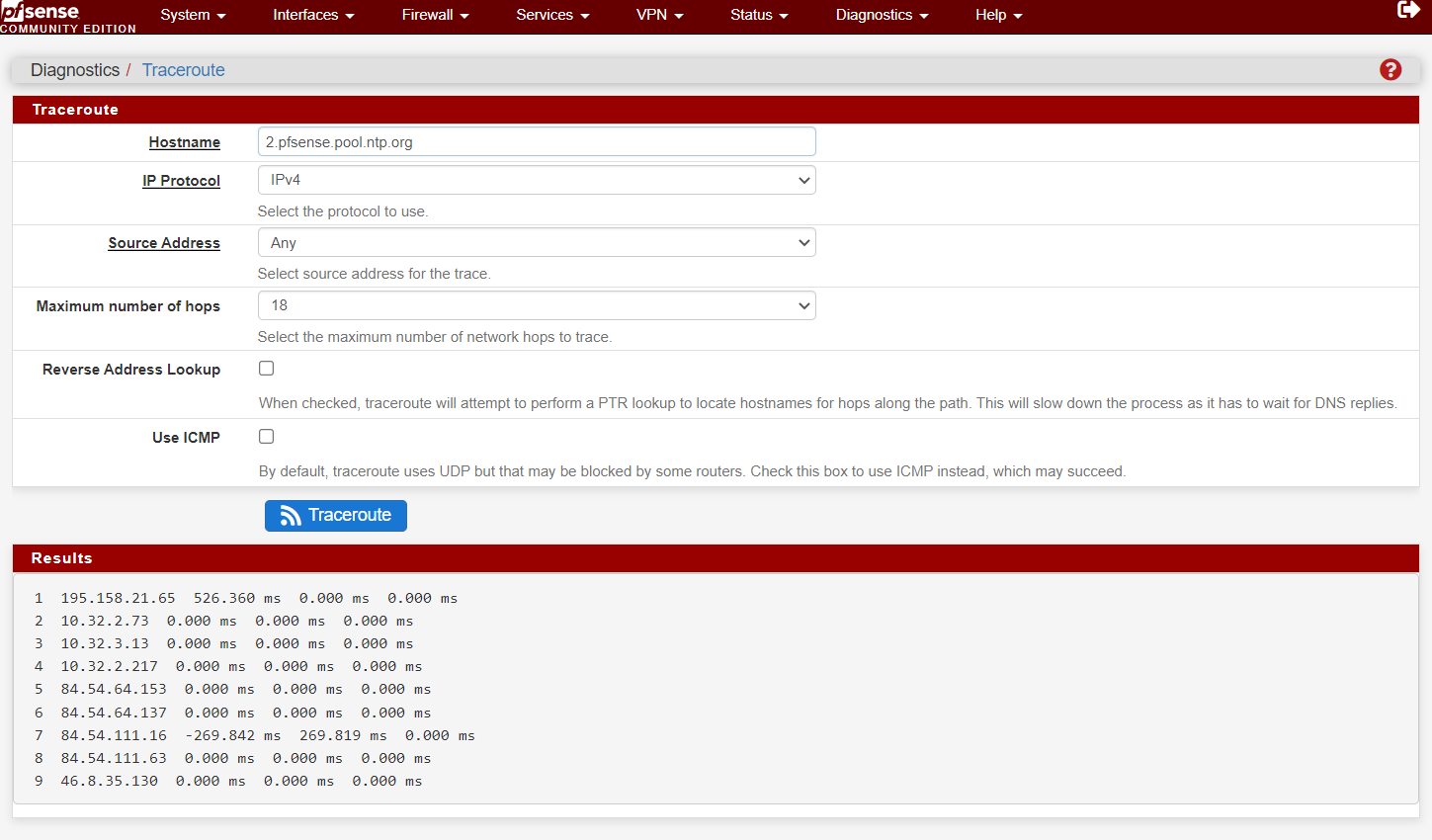
-
@jrey yeah i have tried time windows com and time apple com and also local servers.
-
@dem said in NTP not working:
I might be missing something, but I don't see why those outbound NAT rules for NTP are required. Have you tried disabling them?
i have read this issue in many forums for example here link
-
@dochy said in NTP not working:
2 of them are local ntp servers in my network.
Where is that - your pointing at pools - those are just going to be some random servers out on the internet that are joined into be in the pool.
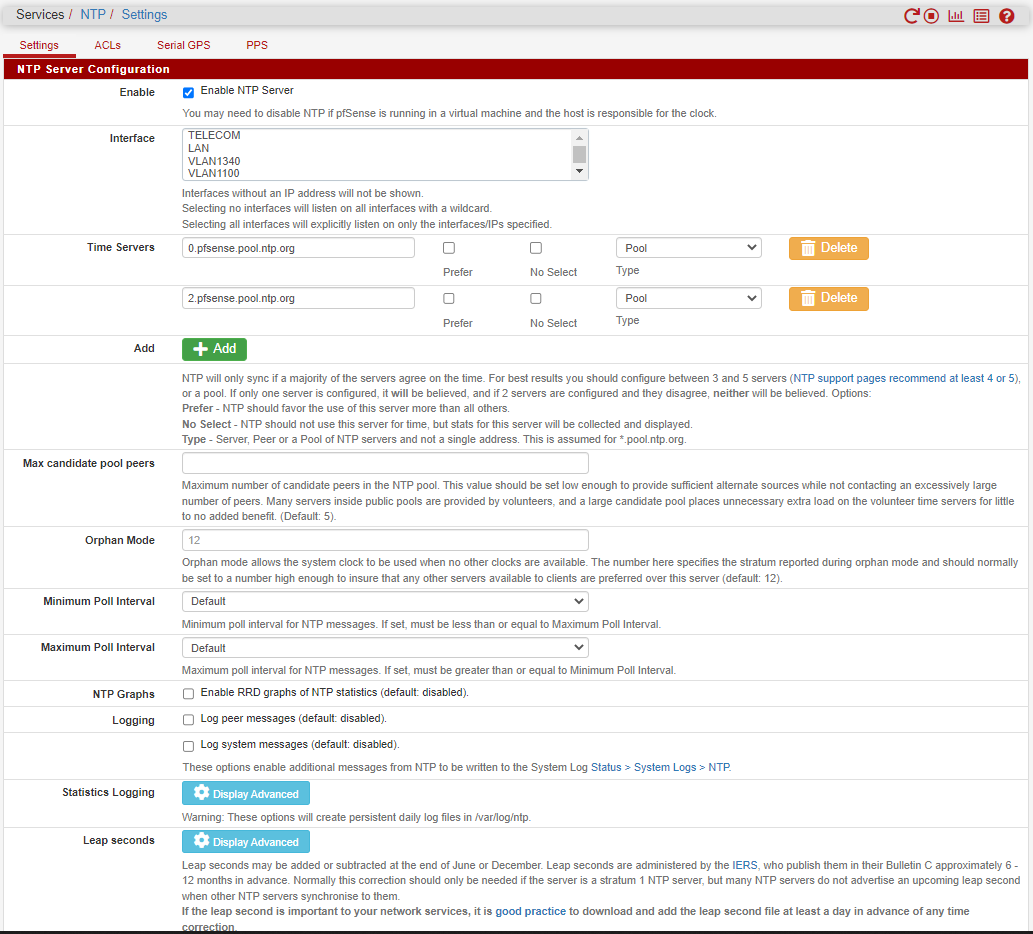
Did you setup 0.pfsense.pool.ntp.org and 2.pfsense.pool.ntp.org to resolve to your own servers? Why would you do that? If your running your own local ntp, then point to them..
And again doesn't matter where the ntp servers are, reach that is over 0 tells me your talking to them at some point
So here are the ntp stats for one of those IPs
https://www.ntppool.org/scores/46.8.35.129
You don't have a reach of 0, your talking to those servers.. Your just not getting consistent answers... If your reach was zero - then your not ever getting a response.. But clearly you are 177 for example would mean you missed only 1 out of the last 8...
But your jitter -1000, tells me your not getting consistent responses... So again - lets see a sniff to one of those IPs your talking to.. Upload the packet capture so can see the details of the query and what is in the response, and what was the response time of when you sent your query and when you got an answer..
But that link to outbound natting is not your fix or to do with your problem - because clearly from the reach you are talking to them and getting responses..
-
@dochy OK, I see that the purpose of those NAT rules is to change the outgoing NTP source port for networks where something interferes with incoming traffic on 123/UDP.
-
@dem said in NTP not working:
the outgoing NTP source port for networks where something interferes with incoming traffic on 123/UDP.
Huh? That is what pfsense does out of the box, with the normal nat..
Where in that link does it say to set static port?

Pfsense auto changes the source port by default.. NTP doesn't normally use a source port of 123 anyway..
Look at my sniff see the answers destination port, those are just random ports that ntp used to make the query, yes pfsense changes the source ports when it nats normally.
192.168.1.100:55555 ---> 1.2.3.4:123 (pfsense) publicIP:42512 ---> 1.2.2.4:123
Would be an example where pfsense changes the source port.. If that link said to set static ports then would be like this
192.168.1.100:55555 ---> 1.2.3.4:123 (pfsense) publicIP:55555 ---> 1.2.2.4:123
There should be no reason to set any specific outbound nat.. Pfsense should use the address of the interface it uses to talk to the ntp server.. To be honest there shouldn't be any nat from firewall when it talks to something on the internet. Only when devices behind pfsense do..
Unless it was using loopback as the source, there would be no reason to nat to the public IP. And if ntp was using localhost as its source it wouldn't be able to ever talk to ntp server inside anyway - because there is no nat on firewall talking to internal IPs..
if you want to get to the bottom of what the actual problem is - let see a sniff of the ntp traffic, attach the pcap.. Clearly from what he posted he is talking to ntp servers and getting responses - or his reach would be 0..
An intelligent man is sometimes forced to be drunk to spend time with his fools
If you get confused: Listen to the Music Play
Please don't Chat/PM me for help, unless mod related
SG-4860 25.07.1 | Lab VMs 2.8.1, 25.07.1 -
Went back and looked at your original post images, and as @johnpoz you are not pointing to anything local in that screen capture. You are pointing to external pools, nothing there is local.
Your most recent trace to the "pool" is of no value. Again as johnpoz explained, the pool is just a collection of somewhat random timeservers that participate in that particular "pool".
try doing a dig for the pool. You will see that most "pools" generally return 4 addresses, like this for example.
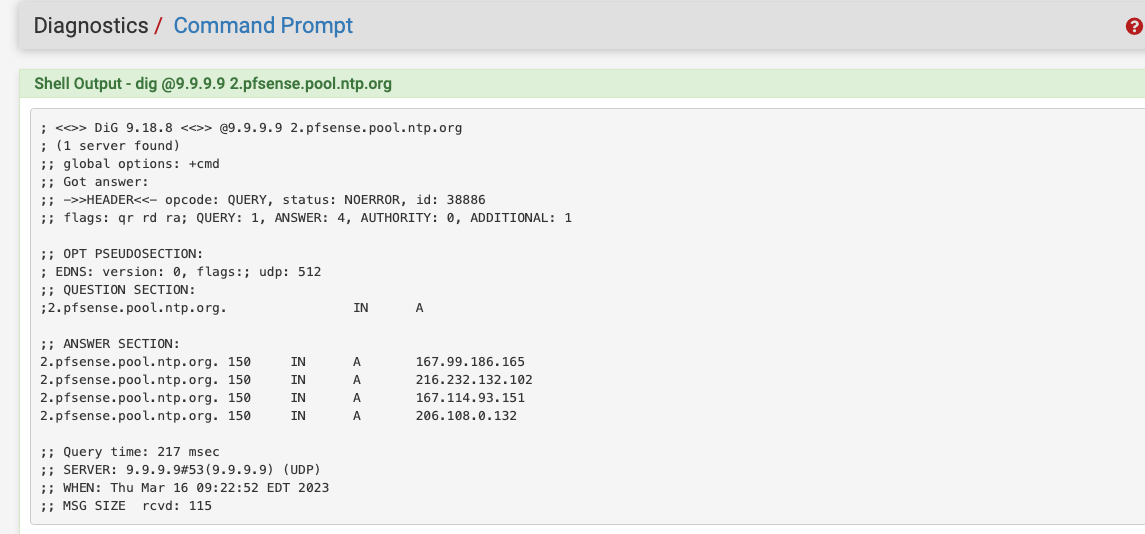
wait a few minutes and run the same dig again,
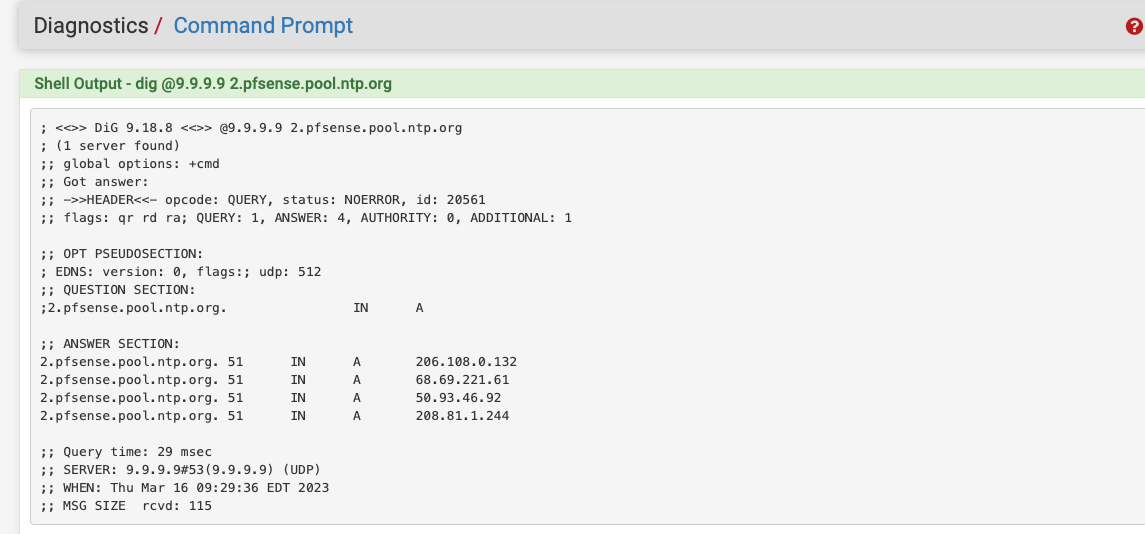
Notice the timeserver addresses returned are often different. That's the "pool" and you don't care..
Although selecting specific pools should not matter, depending on your location, it can. This can be that because your route path to all the specific addresses in a given pool is "response time challenged"
NTP is pretty good at eliminating the "slow responders" over time. The key there is over time. When NTP starts it will try the addresses in the pools you have selected, and start weed out the poor responders.
With 4 country specific pools selected in my configuration, I've seen as many as 15-20 addresses NTP first starts. Most will go away in the first several minutes. the longer it runs the more it will weed out.
Right now I'm showing 1 Active Peer, and 2 Candidate (all at 377). That will change as the response delay to/from those change (network congestion or whatever) NTP will look to the pool for other candidates and adjust itself.Personally I have no luck with the pfsense pools, even though a trace route to any of the specific servers (not the pool address) would suggest they should be within response limits (that is only at the point in time).
For me country local pools are much more reliable and the pfsense pools if I leave them configured (no harm in this), just get filtered out (ie servers in other pools provide much better response in regards to reliability), so I just no longer use the pfsense pools. Basically the Delay(ms) and Jitter(ms) on the pfsense pools goes way up for me.
you could always check www.ntppool.org and then just try a couple of other pools
"In most cases it's best to use pool.ntp.org to find an NTP server (or 0.pool.ntp.org, 1.pool.ntp.org, etc if you need multiple server names). The system will try finding the closest available servers for you. "
The higher up the pool tree you go, the longer it will take to "try finding the closest available for you) because it has more choices to filter through.
-
@johnpoz said in NTP not working:
NTP doesn't normally use a source port of 123 anyway..
According to the docs:
...note that NTP requires port 123 for both source and destination ports
Not all NTP server software behaves this way, of course.
Normally, traffic originating from pfSense itself will not be subject to NAT. So if NTP requiring a source port of 123 is a problem for a given network then a NAT rule like the ones above should randomize the source port. That is apparently why some people need these NAT rules to use NTP.
-
@jrey i have windows server in my local network and it is configured as ntp server, if i want to use it as ntp
server for pfsense should i select it as a peer of server? -
@dochy if your going to run a ntp server on your network and you want pfsense to sync time to this - then it would be a server.
Peers are ntp servers that work together to sync their time.. asking each other, they would really need to be the same stratum level, etc. You would normally set in pfsense to point to your local ntp server as a server.
But that is not what you have - pfsense is pointing to ntp pool, and your having a hard time from what you posted talking to them.. Not that you can't talk to them at all - but seems to be sporadic. If you have a local ntp, then sure use that.. I point my pfsense to my local pi running ntp with a gps had, and pps signal, etc.
I just rebooted my pfsense couple days ago to apply all the patches released.. So takes a few days to really get nice tight..
-
@johnpoz Unfortunately it didn't work. Here is my conf and NTP log file. I have tested 10.123.12.8 server with ntpcheck utility in my pc which is in
the same network with pfsense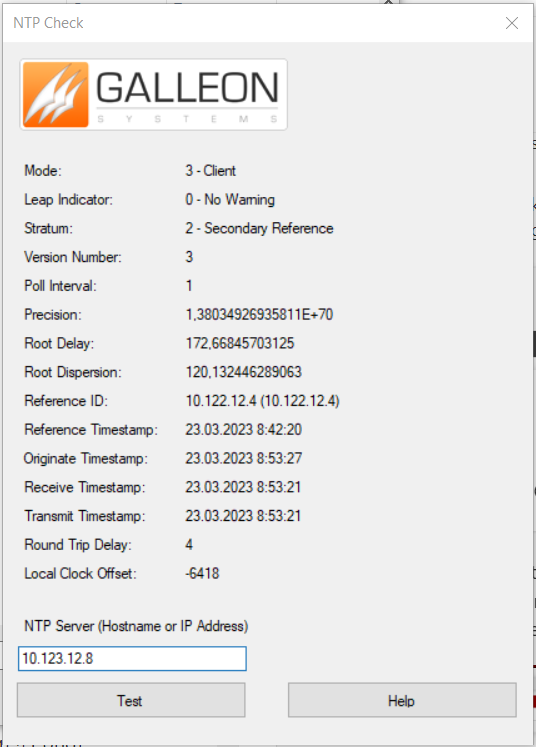
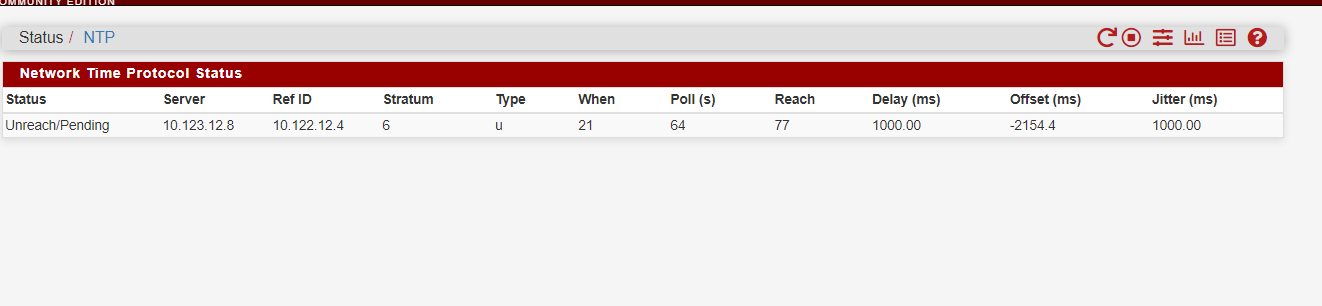
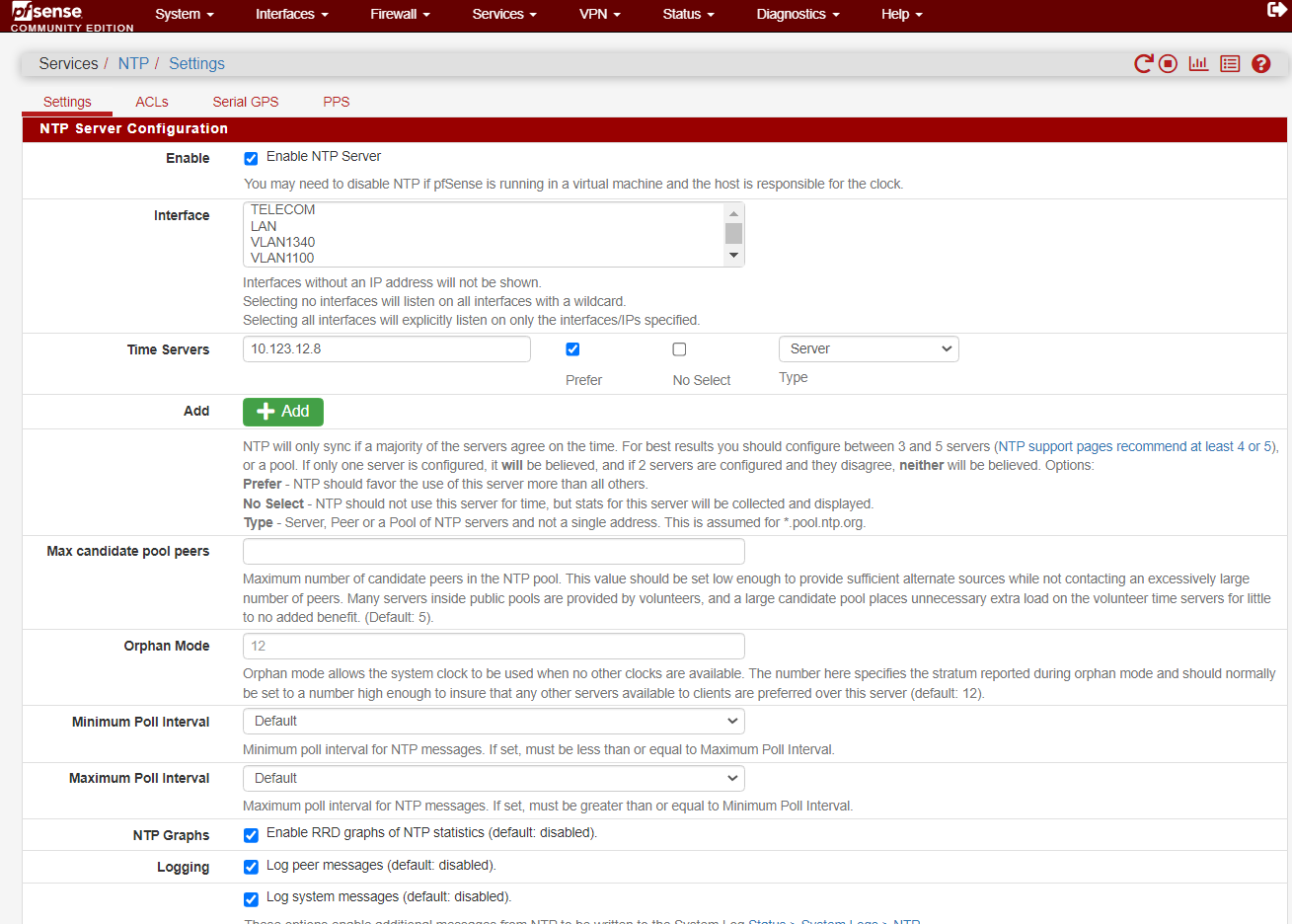
Mar 23 08:50:24 ntpd 65460 ntpd exiting on signal 15 (Terminated) Mar 23 08:50:24 ntpd 65460 10.123.12.8 9012 82 demobilize assoc 34521 Mar 23 08:50:24 ntpd 65460 10.123.12.8 local addr 10.123.12.1 -> <null> Mar 23 08:50:24 ntpd 65460 0.0.0.0 001d 0d kern kernel time sync disabled Mar 23 08:50:24 ntpd 85891 ntpd 4.2.8p15@1.3728-o Wed Jan 12 15:39:52 UTC 2022 (1): Starting Mar 23 08:50:24 ntpd 85891 Command line: /usr/local/sbin/ntpd -g -c /var/etc/ntpd.conf -p /var/run/ntpd.pid Mar 23 08:50:24 ntpd 85891 ---------------------------------------------------- Mar 23 08:50:24 ntpd 85891 ntp-4 is maintained by Network Time Foundation, Mar 23 08:50:24 ntpd 85891 Inc. (NTF), a non-profit 501(c)(3) public-benefit Mar 23 08:50:24 ntpd 85891 corporation. Support and training for ntp-4 are Mar 23 08:50:24 ntpd 85891 available at https://www.nwtime.org/support Mar 23 08:50:24 ntpd 85891 ---------------------------------------------------- Mar 23 08:50:36 ntpd 86042 proto: precision = 1000000.000 usec (0) Mar 23 08:50:36 ntpd 86042 proto: fuzz beneath 0.771 usec Mar 23 08:50:36 ntpd 86042 basedate set to 2021-12-31 Mar 23 08:50:36 ntpd 86042 gps base set to 2022-01-02 (week 2191) Mar 23 08:50:36 ntpd 86042 Listen and drop on 0 v6wildcard [::]:123 Mar 23 08:50:36 ntpd 86042 Listen and drop on 1 v4wildcard 0.0.0.0:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 2 em0 [fe80::20c:29ff:fe71:6839%1]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 3 em0 213.230.64.30:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 4 em1 [fe80::20c:29ff:fe71:6843%2]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 5 em1 10.123.12.1:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 6 em2 [fe80::20c:29ff:fe71:684d%3]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 7 em2 217.30.161.101:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 8 lo0 [::1]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 9 lo0 [fe80::1%5]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 10 lo0 127.0.0.1:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 11 em1.1300 [fe80::20c:29ff:fe71:6843%8]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 12 em1.1300 10.123.20.1:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 13 em1.1350 [fe80::20c:29ff:fe71:6843%9]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 14 em1.1350 10.123.24.1:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 15 em1.1500 [fe80::20c:29ff:fe71:6843%10]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 16 em1.1500 10.123.40.1:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 17 em1.1600 [fe80::20c:29ff:fe71:6843%11]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 18 em1.1600 10.123.48.1:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 19 em1.1700 [fe80::20c:29ff:fe71:6843%12]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 20 em1.1700 10.123.56.1:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 21 em1.1750 [fe80::20c:29ff:fe71:6843%13]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 22 em1.1750 10.123.64.1:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 23 em1.1340 [fe80::20c:29ff:fe71:6843%14]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 24 em1.1340 10.123.22.1:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 25 em1.1100 [fe80::20c:29ff:fe71:6843%15]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 26 em1.1100 10.123.15.1:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 27 em1.1200 [fe80::20c:29ff:fe71:6843%16]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 28 em1.1200 10.123.16.1:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 29 em1.1360 [fe80::20c:29ff:fe71:6843%17]:123 Mar 23 08:50:36 ntpd 86042 Listen normally on 30 em1.1360 10.123.32.1:123 Mar 23 08:50:36 ntpd 86042 Listening on routing socket on fd #51 for interface updates Mar 23 08:50:36 ntpd 86042 10.123.12.8 8011 81 mobilize assoc 2451 Mar 23 08:50:36 ntpd 86042 kernel reports TIME_ERROR: 0x2041: Clock Unsynchronized Mar 23 08:50:36 ntpd 86042 0.0.0.0 c01d 0d kern kernel time sync enabled Mar 23 08:50:36 ntpd 86042 kernel reports TIME_ERROR: 0x2041: Clock Unsynchronized Mar 23 08:50:36 ntpd 86042 0.0.0.0 c012 02 freq_set kernel 9.180 PPM Mar 23 08:50:36 ntpd 86042 0.0.0.0 c016 06 restart Mar 23 08:50:36 ntpd 86042 10.123.12.8 8014 84 reachable -
@dochy said in NTP not working:
My pfsense is in vmware server

Has anyone considered the warning/note shown at top of the NTP config page ?
/Bingo
-
@bingo600 In my case Vmware is not responsible for clock
-
@dochy how long are you waiting, what is your reach doing.. does it change.. It should move up from 0 to 377... Your is showing 77, so either its been running a long time and you are not getting all the responses or you just started it..
-
@johnpoz i have been waiting about 2 hours, yeah now status is 377 but still unreach/pending
-
@dochy if your reach is 377 and staying there - then you have too much of an offset possible, ntp will normally not sync if the offset is too much.. Do a manual sync of time so your closer - you can see in your test there with that gallon tool doesn't seem like any of your clients actually have very accurate time..
If I run that tool from my windows machine to my ntp server - my clock offset is 1ms or 0 or 2 etc..
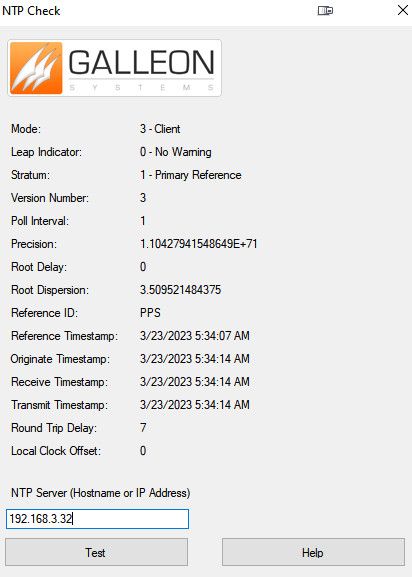
Curious why your pointing at 10.123.12.8 when its reference is 10.122.12.4 - why would you not just point to this 12.4 address? Also why is it saying where you pointing is a stratum 6? Your root delay and dispersion is crazy high as well..
-
@dochy
Have you looked at : these two
https://communities.vmware.com/t5/ESXi-Discussions/NTP-Why-will-my-host-NOT-sync-time-to-the-NTP-source/td-p/2826675https://kb.vmware.com/s/article/1005092
And this:
Please note that “An ESXi/ESX host, by default, does not accept any NTP reply with a root dispersion greater than 1.5 seconds (1500 ms).” (https://kb.vmware.com/s/article/1035833). Hence, the customer would have to add the “tos maxdist” configuration as a workaround if they want to continue using the same configured NTP servers. A flash valye of 400 can also indicate that the maximum distance threshold has been exceeded and that the tos maxdist configuration needs to be applied.