Observations, 25.03.b.20250414.1838
-
@pst
[Unbelievable
Without limiters or traffic shaper.
That was never the case up to now.
Will also try with mpd5 again.]I stand corrected
Actually this can only be achieved with load balancing.
Latency still increases slightly under load, and you do need limiters.
Can't say there is any difference with the new kernel ppp driver. See post below
-
@netblues
this is with heavy limiting, for the shake of testing
-
Please share the core dump files here:
https://nc.netgate.com/nextcloud/s/zJfaxPfrfAAniwF -
@marcosm done.
-
@pst said in Observations, 25.03.b.20250414.1838:
This non-optimal handling of wireguard tunnels during boot has previously been reported on 24.05, and a bug raised.
The bug in question is https://redmine.pfsense.org/issues/15435
While the root cause is still to be determined, a possible cause could be that some of my WG peers are configured with ends point addresses using FQDNs, and resolving those during boot are causing the slow boot (TBC).
-
@pst said in Observations, 25.03.b.20250414.1838:
a possible cause could be that some of my WG peers are configured with ends point addresses using FQDNs, and resolving those during boot are causing the slow boot
I have just confirmed that the root cause is the use of FQDN in the peer end-point address. While a temporary work-around is to use IP addresses instead of FQDNs, FQDNs must be allowed as one of my providers specifies FQDNs for a pool of addresses.
-
@pst I have found a solution that works in my scenario, where Wireguard requires Unbound to be up and running before starting the service. By disabling the early shell command to start wireguardd, and let wireguardd start at the end of the boot sequence (no change required here), my slow/failed boot is no more.
Update: a local patch is required to stop wireguard from automatically reinstalling the early shell command. See redmine for details.
-
@pst said in Observations, 25.03.b.20250414.1838:
I don't think this is a real error. The VIP ::10.10.10.1/128 is set up when pfBlockerNG is configured. The ::151 will be part of the subnet that is set up when the WAN receives the IPv6 config, which is hasn't yet. LAN is tracking WAN in my IPv6 config.
Presumably
::10.10.10.1/128is on Localhost and::151is a static mapping on LAN - correct? The error itself seems correct - the address::151is not in the subnet::10.10.10.1/128. Would you share the full/usr/local/etc/kea/kea-dhcp6.confwhile the issue exists? You may upload it to:
https://nc.netgate.com/nextcloud/s/zJfaxPfrfAAniwF -
@marcosm yes, ::10.10.10.1/128 is on the LAN
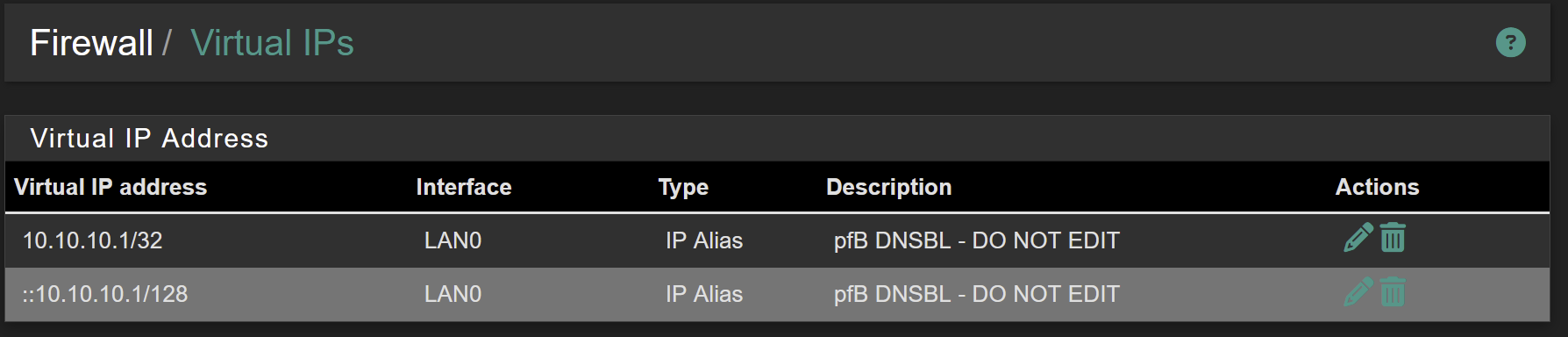
and ::151 is a static mapping on the LAN

I am uploading a zip that contains
- kea-dhcp6.conf.ATERROR which is the contents after I release the WAN lease (triggers the ERROR)
- kea-dhcp6.conf.AFTERSUBNETASSIGNED which is the working file after reception of the subnet config
- kea-dhcp6.conf.diff is the diff between the two
- dhcpd.log are the log entries for the renewal of the WAN lease
To me it looks like the error situation is present until we receive the IPv6 subnet configuration for the WAN which is then propagated to the LANs. I also saw this in 24.11 but paid less attention to it as it didn't trigger an alarm bell on the dashboard.
-
@marcosm I did some additional testing and managed to reduce the number of occurances of the error.
First I changed the WAN config, unchecked the "Do not wait for RA" (which was previously checked for some reason).
I then released the WAN lease, which triggered one error as seen before. When I renewed the WAN lease there were no errors, progress!
-
@pst DM'd with request for additional info.
-
Details and fix for the Kea error:
https://redmine.pfsense.org/issues/16154