Pfsense not responding to large packet pings
-
Hi folks
I'm running some tests on my network and found that if I ping my pfsense box with large packets, say 20,000 bytes or more, then it won't respond.It's sitting on a HP server running ESXi. Other VMs respond to large packets ok on the same hardware from within the same subnet.
Simple test....
ping -l 65500 192.168.x.xOnly pfsense doesn't respond. I have to go down to around 10,000 bytes before it replies.
Even if I ping from another VM on the same host I have to reduce the packet size.
Any idea what might cause this?
Thanks in advance
-Matt
-
Update: 15,000 bytes works fine.
But 16,000 fails almost all pings. Maybe one ping in 10 will return an echo.It's so weird
-
Update 2: Pinging OUT from the pfsense to other devices on my LAN, if I set the packet to 25,000 bytes it takes around 1.7 seconds to respond to pings.
But, sometimes I get the message...
"Frag reassembly time exceeded"Why would it be taking so long to reassemble packets? Is there something to tune somewhere?
-
@gemeenaapje said in Pfsense not responding to large packet pings:
Is there something to tune somewhere?
Your idea of supporting "25000".
I guess you're talking about Jumbo frames.These could work locally, on your own LAN's.
Pumping them over the net : that's a no go. "1500" is the barrier.The NIC hardware (shift registers) must support them. Device drivers must support them. Etc.
@gemeenaapje said in Pfsense not responding to large packet pings:
Why would it be taking so long to reassemble packets?
Maybe because when it fails, it keeps failing.
-
@gemeenaapje said in Pfsense not responding to large packet pings:
ping -l 65500 192.168.x.x
Only pfsense doesn't respond. I have to go down to around 10,000 bytes before it replies.Does here
$ ping -l 65500 192.168.9.253 Pinging 192.168.9.253 with 65500 bytes of data: Reply from 192.168.9.253: bytes=65500 time=1ms TTL=64 Reply from 192.168.9.253: bytes=65500 time=1ms TTL=64 Reply from 192.168.9.253: bytes=65500 time=1ms TTL=64 Reply from 192.168.9.253: bytes=65500 time=1ms TTL=64 Ping statistics for 192.168.9.253: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 1ms, Maximum = 1ms, Average = 1msAnd via capture you can see that it has been fragmented and put back together
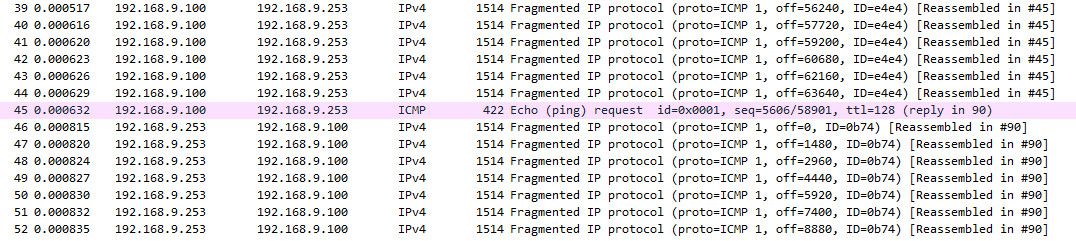
-
Thanks for the replies.
I think the problem is with the speed reassembling the packets. I don't know why though.
Forgot to mention I have a HP NIC:
https://h20195.www2.hpe.com/v2/GetDocument.aspx?docname=c04111479&doctype=quickspecs&doclang=EN_US&searchquery=&cc=th&lc=enIt has 2 10gbps SFP+ adapters (1 fibre and 1 ethernet).
I have the hardware offload settings disabled. I think that was default.
I'm not actually sure at what level the packets are reassembled if fragmented. Can anyone advise?
-
Read : https://en.wikipedia.org/wiki/OSI_model : Layer 3 - Network Layer.
-
Mmm, I'd guess it exhausted the frags table if you're sending a lot of pings. Though that is normally logged in the system log.
You can increase it in Sys > Adv > Firewall > 'Firewall Maximum Fragment Entries'.
5000 is normally more than sufficient though.Why are you sending huge packets like that?
Steve
-
@stephenw10 said in Pfsense not responding to large packet pings:
Why are you sending huge packets like that?
Exactly

-
@stephenw10
Morning
I'm trying to do some testing for my day job. I support a bunch of products for hospitals, one of which is very old (like 25 years old foundation software). It's known to have problems when large packets don't make it through the switches.
I also found it weird, so I started to do some checks on my own network at home.
To my surprise I found that I also had problems with fragmented packets not being reassembled.Now, if I can figure out how to fix it on my own network at home, I'll be better positioned to help our customer out. Not only that but I will have learned something new.
Thanks
-
@gemeenaapje said in Pfsense not responding to large packet pings:
It's known to have problems when large packets don't make it through the switches.
That is, if a switch support 'RFC' Jumbo frames, then you'll find it in their product description. I can imagine some just don't.
-
@gertjan 25 year old software wouldn't be doing jumbo ;)
@GemeenAapje I don't think the switch would be the problem, it wouldn't be fragmenting or reassembling - so its not the switches that would be an issue.. It would be the routers. Or the end device.
The device putting the data on the wire would break it up according to its mtu. If it put larger sized than the switch supports ie a jumbo then yeah that would be problematic. But you testing large pings to pfsense, wanting an answer - isn't the switch having an issue.
As you see on the sniff I did on pfsense - he got the fragments at 1514. A better test might be to send the packets to something through the router with such a large size..
An intelligent man is sometimes forced to be drunk to spend time with his fools
If you get confused: Listen to the Music Play
Please don't Chat/PM me for help, unless mod related
SG-4860 25.07.1 | Lab VMs 2.8.1, 25.07.1 -
@gemeenaapje said in Pfsense not responding to large packet pings:
It's known to have problems when large packets don't make it through the switches.
Why is it sending large packets? Is it using jumbo frames? What is the MTU? Other than on token ring, back when I was at IBM, I've never seen MTUs set beyond 1500, except for my own testing. If it is using jumbo frames, then you have to make sure the switch can handle them. IIRC, when jumbo frames are used, the usual MTU is 9000. Even then, you have to make sure everything on the local network can handle that MTU.
-
@johnpoz said in Pfsense not responding to large packet pings:
25 year old software wouldn't be doing jumbo ;)
25 year old software isn't jumbo aware. Software from 2021 : same thing.
The ISO network stack is far older then that. I recall, somewhere in the eighties, @school, that they started to tell me about this new 7 layer model (some say 8 layers) thing.
So, the program would hand over 'the file' to be transmitted to the OS.
And deep down somewhere, the data stream is cut down in chunks of XX bytes, as that is the way how info is send over.
The program doesn't need to know about headers, sessions, MAC addresses or even IP addresses. It doesn't care that 'TCP' or IPv4 or IPv6 is used.I guess @GemeenAapje is talking about Jumbo frames because he want to push to the limit his local traffic from/to a file server or a NAS.
With these jumbo frame settings, locally, on PC's using Macrium (backup disk clone tool) I can backup a disk to my Syno NAS with true 100 % 1 Gigabit / sec. With classic 1500 byte frames there is little bit more overhead. Jumbo frame cram out that extra zero dot x % speed gain.No "help me" PM's please. Use the forum, the community will thank you.
Edit : and where are the logs ?? -
@gertjan good point actually.. Really need to just sniff on the device sending the traffic and see what its putting on the wire.
Are they jumbo frame or just fragmented down to 1500 mtu.. If the sender is putting jumbo on the wire - then yeah your going to need jumbo support on the switches. And the router as well..
And you can have all kinds of issues when you have one network doing jumbo, and then another network your trying to route to for the receiver device that isn't using jumbo, etc.
@GemeenAapje we really need to more info - but causing a problem by sending large pings to pfsense is prob not related to the problem..
-
@johnpoz said in Pfsense not responding to large packet pings:
but causing a problem by sending large pings to pfsense is prob not related to the problem..
...though I would expect it to work with arbitrarily sized packets. I have never tried 64K though. Until now.
[2.5.2-RELEASE][admin@t70.stevew.lan]/root: ping -s 65500 172.21.16.246 PING 172.21.16.246 (172.21.16.246): 65500 data bytes 65508 bytes from 172.21.16.246: icmp_seq=0 ttl=64 time=1.942 ms 65508 bytes from 172.21.16.246: icmp_seq=1 ttl=64 time=1.825 ms 65508 bytes from 172.21.16.246: icmp_seq=2 ttl=64 time=1.878 ms 65508 bytes from 172.21.16.246: icmp_seq=3 ttl=64 time=1.764 ms ^C --- 172.21.16.246 ping statistics --- 4 packets transmitted, 4 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 1.764/1.852/1.942/0.066 msA similar test to another device in my network fails:
[2.5.2-RELEASE][admin@t70.stevew.lan]/root: ping -s 2000 172.21.16.185 PING 172.21.16.185 (172.21.16.185): 2000 data bytes ^C --- 172.21.16.185 ping statistics --- 2 packets transmitted, 0 packets received, 100.0% packet lossThe difference there is that 172.21.16.185 is behind a PoS TP-Link switch which doesn't pass packet fragments. Because.... no clue!
But bad switches aside it should work.
Steve
-
@stephenw10 said in Pfsense not responding to large packet pings:
PoS TP-Link switch which doesn't pass packet fragments.
What kind of shit switch? Yeah that belongs in the trash!
So what I have been able to duplicate.. Is if I try it "through" pfsense it fails.. But if on the same L2 network then works
$ ping -l 65500 ntp Pinging ntp.local.lan [192.168.3.32] with 65500 bytes of data: Request timed out. Request timed out.root@pi-hole:/# ping -s 65500 ntp PING ntp.local.lan (192.168.3.32) 65500(65528) bytes of data. 65508 bytes from ntp.local.lan (192.168.3.32): icmp_seq=1 ttl=64 time=12.1 ms 65508 bytes from ntp.local.lan (192.168.3.32): icmp_seq=2 ttl=64 time=12.1 ms 65508 bytes from ntp.local.lan (192.168.3.32): icmp_seq=3 ttl=64 time=12.1 msAn intelligent man is sometimes forced to be drunk to spend time with his fools
If you get confused: Listen to the Music Play
Please don't Chat/PM me for help, unless mod related
SG-4860 25.07.1 | Lab VMs 2.8.1, 25.07.1 -
Same one that loves VLAN 1.

Yeah, needs recycling!
Just for reference here's two 3100s on different subnets routed through a 2.5.2 box:
[21.05.1-RELEASE][admin@fw1.stevew.lan]/root: ping -s 65500 -c 3 3100-2.fire.box PING 3100-2.fire.box (192.168.10.103): 65500 data bytes 65508 bytes from 192.168.10.103: icmp_seq=0 ttl=63 time=3.832 ms 65508 bytes from 192.168.10.103: icmp_seq=1 ttl=63 time=3.512 ms 65508 bytes from 192.168.10.103: icmp_seq=2 ttl=63 time=3.583 ms --- 3100-2.fire.box ping statistics --- 3 packets transmitted, 3 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 3.512/3.642/3.832/0.137 msThat's also through some VLANs over a LAGG just for fun.
Steve
-
Odd so through pfsense seems largest I can get is 34276
$ ping -l 34276 ntp Pinging ntp.local.lan [192.168.3.32] with 34276 bytes of data: Reply from 192.168.3.32: bytes=34276 time=7ms TTL=63 Reply from 192.168.3.32: bytes=34276 time=7ms TTL=63$ ping -l 34277 ntp Pinging ntp.local.lan [192.168.3.32] with 34277 bytes of data: Request timed out. Request timed out.problem is I think if you loose like 1 packet - you run into problem where they all have to be transmitted again..
$ ping -l 34276 ntp -t Pinging ntp.local.lan [192.168.3.32] with 34276 bytes of data: Request timed out. Request timed out. Reply from 192.168.3.32: bytes=34276 time=7ms TTL=63 Reply from 192.168.3.32: bytes=34276 time=7ms TTL=63 Reply from 192.168.3.32: bytes=34276 time=8ms TTL=63 Reply from 192.168.3.32: bytes=34276 time=7ms TTL=63 Reply from 192.168.3.32: bytes=34276 time=7ms TTL=63 Reply from 192.168.3.32: bytes=34276 time=7ms TTL=63 Request timed out. Reply from 192.168.3.32: bytes=34276 time=7ms TTL=63 Reply from 192.168.3.32: bytes=34276 time=7ms TTL=63An intelligent man is sometimes forced to be drunk to spend time with his fools
If you get confused: Listen to the Music Play
Please don't Chat/PM me for help, unless mod related
SG-4860 25.07.1 | Lab VMs 2.8.1, 25.07.1 -
That's between local subnets? The ping time is very high compared with what I'm seeing at double the packet size. So presumably twice the number of fragments.
Unable to replicate here.