Unbound seems to be restarting frequently
-
@gertjan said in Unbound seems to be restarting frequently:
Btw @bmeeks, I'm using pfBlocker(latest) and its using unbound-control to 'inject' DNSBL changes. When pfBlocker found an updated DNSBL list, it parses out the changes, and communicates them to unbound.
For me, unbound restarts ones or twice a week, and even these restarts do not loose the DNS cache, as it is dump before the stop, and read back in when it restarts. That is, if pfBlocker was restarting it.Big, no, huge DNSBL lists were build, and unbound needed a lot more time to start. People started to detect DNS outages.
Yes, the "huge" DNSBL lists were what I was referring to. pfBlockerNG and the DNSBL feature can certainly be a useful tool, but many users manage to shoot themselves in the foot with it as evidenced by the many posts I see here on the Forums. And instead of being only a moderately painful "BB-gun" (an air-powered, small caliber weapon for those who might not be familiar with the common American name), the tool can be the equivalent of shooting your foot off with an American AC-130 gunship (a.k.a. "Angel of Death") when used with huge lists of domains to block. That chokes
unboundby generating long startup times as the lists are parsed. And untilunboundstarts, it can't do DNS lookups. -
Hello, I'm just getting up to speed on this issue. I've noticed the constant restarts of unbound... but it hasn't actually caused us any problems normally.
But now we are looking at using Cisco Umbrella DNS filtering, which seems to have some limits to the number of lookups that you can perform per day.
So the fact that unbound gets restarted and the cache gets cleared is now an issue due to the cache being cleared, resulting in way more upstream dns requests. I understand I can turn off registering dynamic dhcp leases, but that is a really nice feature.
Just to give a practical example, we are looking at signing up for 50 licenses, which are allowed 3000 lookups each a day, so 150K total for our 23 locations.
One of our busier branches had 150K queries to unbound in the last day, with about 12K cache misses. So with unbound doing it's constant restarting, we may have blown all our queries with one branch.
What is needed to move forward, there seems to be a roadmap at https://github.com/pfsense/FreeBSD-ports/pull/751
If that solution generally seems acceptable, then do the extra config bits just need to be added? Adding the view and the acl entries for interfaces that can use unbound?
It would probably be good to make sure the correct precedence of dns entries is respected with this solution, and things like that.
Hardware used: Alix 2D13 X 10, APU2D4 X 10, SG-2200 X 10, SG-2440 X 4
-
@stompro said in Unbound seems to be restarting frequently:
but that is a really nice feature.
On network(s) with many devices, or network(s) that have a faulty implementation of the DHCP client, or network(s) with devices that loose their connection very often (Wifi), the current implementation of how lease info, the hostname + IP, is updated in the resolver unbound, is completely flawed **.
A question that every admin has to ask for himself : what devices in a network need to be known by 'name' ?
Most of our portable devices, and most PC's TV's whatever : we don't care. Only server type devices like printers, NAS, scanners, cameras etc need to have their name assigned.
And if possible not the default name these devices propose but a name chosen by the admin.
For these devices : make a static mac DHCP lease entry. This type of devices are not added a lot to our networks, none of us is installing a new network printer and NAS every day.
Shut down "DHCP Registration".
And done.
Bonus : you have a build in list in pfSense with all your important network devices, part of pfSense config.
All the important devices (servers) or less important devices can use the default DHCP-client mode. The admin control from pfSense what their IP / DNS etc will be. No more f*ck *ps when people start to assign static addresses (and forget half the stuff needed).
With the upcoming IPv6 it will be even easier to administer all this stuff in one place : pfSense.I made entries a long time ago for all devices that I access by wire.
https://github.com/pfsense/FreeBSD-ports/pull/751 uses a potential good solution.
Another approach might be : as unbound can uses "call back functions" for nearly every important resolve step, and it has chooses python to be the call back script method, its easy to add another python script "made by pfSense" that loads the file content of the DHCP-leases file if it was changed. If not, it serves IP or reverse right out the in python memory array.
Exactly like pfBlockerNG-devel using the 'python' mode.** edit : that is : pfSense, with a dozen or so devices that behave correctly, like 24 hours leases, so 12 or so renewals take place every day, the situation is pretty non noticeable.
But when these devices start to emit big quantities of DNS traffic, users will start to notice something. -
@stompro said in Unbound seems to be restarting frequently:
which are allowed 3000 lookups each a day
That is a really low number.. Out of curiosity if they block something, what is the TTL they send on the blocked IP they send you back? What exactly do they send back for a query that is blocked? Do they send back an IP that points you to a block page? Do they just send back 0.0.0.0, do they send back NX, Refused? What is the ttl if they send you back an IP of any kind?
A client looking for something, be it blocked or not if the ttl is low, or even if its high could produce a insane amount of queries depending on what is sent back, and what is actually cached.
I agree unbound clearing its cache sure isn't going to be helpful in lowering the number of queries sent upstream..
Until they change how registration of dhcp is done so it doesn't restart and clear the cache of unbound.. Turning that off is one solution.
Another solution might be to use another local cache, that isn't restarted that unbound forwards to. Also you might want to look into increasing min TTL to lower number of queries.
Also when you find stuff that is being blocked by them, creating a local block for that - so its not forwarded upstream could be way to reduce your overall number of queries sent to them.
-
@gertjan said in Unbound seems to be restarting frequently:
Shut down "DHCP Registration".
And done.Except that this is a documented feature and should work properly. It doesn't. This is a workaround and in some cases undesirable.
-
@swixo said in Unbound seems to be restarting frequently:
This is a workaround and in some cases undesirable.
I don't think anyone would disagree with that. It has been a sore point for a long time.
Agree it not very desirable for unbound to restart and loose its cache on every dhcp, etc.
-
@swixo said in Unbound seems to be restarting frequently:
Except that this is a documented feature and should work properly. It doesn't.
Sure and it's serious. pfSense is perfect. The issue is fare to 'old'.
But I have this impression that not many people notice it / are bothered with it / always look at the dashboard page and never to the page that actually matters most : the log pages. Dono why. maybe the log pages are less pretty.@swixo said in Unbound seems to be restarting frequently:
This is a workaround and in some cases undesirable.
Workaround ?
I used two available options in the GUI. Telling pfSense not to use the names DHCP devices gave it (because most use really stupid non significant,t names) : I like to chose my own names.
I like to chose what IP is used by what device, like servers from 192.168.1.20 to 20 - cameras from 30 to 50 - NAS and printers from 60 to 70 - and all PC's start after 80.
And again : no need to 'login' into every LAN device to set up DHCP/network related stuff. No need to know and learn all these thee devices. I control their network behaviour from pfSense.That's not a work around : it a huge feature. I even presume that all 'big' or 'company' networks are set up like that.
Btw : I work f for a hotel and I decide who sleeps on which room, the clients don't chose.
No coding needed here. Just very ordinary classic network 'book keeping' and vey ancient network knowledge.
My opinion is based on a small (60 devices ?) company network of course, @home I care less, I only want to now where my NAS is ;)
@johnpoz said in Unbound seems to be restarting frequently:
I don't think anyone would disagree with that
I call it a bug (flaw, whatever).
Still, as sais, no workaround needed IMHO.
Even if the dhcpleases change = unbound restart issue wouldn't exist, I would myself allocate my network device devices.
Doing so so under pfSense even squashed a bug. -
@johnpoz said in Unbound seems to be restarting frequently:
That is a really low number.. Out of curiosity if they block something, what is the TTL they send on the blocked IP they send you back? What exactly do they send back for a query that is blocked? Do they send back an IP that points you to a block page? Do they just send back 0.0.0.0, do they send back NX, Refused? What is the ttl if they send you back an IP of any kind?
They redirect to a block page, requires installing their CA on devices you want to show the block page without browser warnings.
I'll gather the other info about the TTL once they re-enable my trial.
I am trying the Minimum RRSet TTL setting of unbound, to make the miniumum TTL 2 hours. That does seem to help quite a bit.
Thanks for the reply.
-
@stompro said in Unbound seems to be restarting frequently:
Minimum RRSet TTL setting of unbound, to make the miniumum TTL 2 hours. That does seem to help quite a bit.
I have ran a min ttl of 1 hour for many many years - I have not seen any sort of issues with doing so.. Its not that I trying to actually lower the number of queries - but sites that use excessively low ttls bug the shit out of me ;)
There is no sane reason to have a ttl of 60 seconds - unless your were in the actual process of changing the record to point elsewhere.. And 60 seconds, 5 minutes seem to be a growing common thing with dns hosted by dns services. I think they are on purpose trying to increase the number of queries sent to them.. Either just bumping their numbers up, or wanting to track users more on how long they are staying on sites, how often they go there, etc.
Sure if the record is for a dynamic host, ie ddns sure you wouldn't want that ttl to be like a day or something...
So I would be curious how low they set the ttl of something.xyz.com that are blocking, will it maybe be unblock 5 minutes from now ;)
-
This is getting off topic also, but I'm also exploring sending out a list of the top 100-500 domains in a domain override list to bypass cisco umbrella resolution for the most heavily requested domains... it seems like I can just use our ISPs or googles dns servers for those entries. And Unbound has some nice options for domain overrides that I didn't know about. I can set multiple servers for each domain, you can say to fall back to the system forwarders if the configured override forwarders are not accepting requests for fault tolerance. And I'm reading up on on dumping and restoring the cache to make unbound restarts retain the rrset cache. But this whole case of paying per lookup essentially is probably quite a niche situation.
And after reading more about how Cisco Umbrella calculates usage, it looks like it is a 30 day daily average, so you get some credit for slow weekends and the like.
-
@stompro said in Unbound seems to be restarting frequently:
This is getting off topic also
Yeah but quite often that is where the fun happens ;) A specific question can often lead to great discussions, be that always on point and specific the original question would be boring..
If threads were always question : answer and that is all - I doubt I would spend as much time here as I do..
I could see quite a few ways to reduce the number of queries sent to them ;) Overrides for stuff you know is on the bad list, but yeah I like your idea of known good domains being forwarded to somewhere else that doesn't charge you for the query.. I mean how likely is it for example for www.google.com to get put on their bad list ;) So why ever ask them for www.google.com.. And have that query count against your use.
The only problem I see with that is if they did for some reason put something on the block list that you were forwarding somewhere.. But there is prob a large list of specific fqdn or domains that are highly highly unlikely to be listed as bad by them.
-
@johnpoz said in Unbound seems to be restarting frequently:
I could see quite a few ways to reduce the number of queries sent to them ;) Overrides for stuff you know is on the bad list, but yeah I like your idea of known good domains being forwarded to somewhere else that doesn't charge you for the query.. I mean how likely is it for example for www.google.com to get put on their bad list ;) So why ever ask them for www.google.com.. And have that query count against your use.
I'm not too worried about caching the bad stuff, that should be a very small minority of requests, and once someone hits the block page, I doubt they will keep trying enough for it to be a problem.
www.google.com is actually one I wouldn't want to add, since Cisco Umbrella enforces safe search for google search results. Although it is possible to do that locally(setting a domain override for google.com to a certain ip), I'm not sure how they are doing it, so I would rather leave that on them. I think google uses sane ttls so they don't seem to be a problem.
I'm going to stick with bypassing for service related stuff, not content related. windowsupdate,msedge,connectioncheck.ubuntu.com,lencrpt.com.
-
@gertjan said in Unbound seems to be restarting frequently:
Consider the situation: unbound starts, and read all the files its need, like /var/etc/hosts, the DHCP leases file, etc.
Then we instruct it to load the cache file, /var/tmp/unbound_cache
It doesn't take long to discover that the internal working cache (with the new local info) in unbound is being replaced by what has been written in /var/tmp/unbound_cache.
F*ck.
Doing so makes it completely useless to restart unbound to begin with …... >:(
As said in the doc: dump_cache and load_cache exists for debugging purposes.Hello, I was trying to track down why the unbound dump_cache and load_cache where not fully implemented, and saw your comments from 2015. I'm wondering if maybe something has changed in the unbound code... because I cannot verify that local data is included in the unbound cache dump.
When I do a cache dump, I cannot find any of my locally setup domains in the data.... and if I understand your rant correctly, you are saying that old stale local data from the dump would overwrite new data, making the dump and restore unusable.
In my testing with unbound 1.12 in 21.05.2, I don't notice any incorrect data after a dump and restore. Could you tell me what to look for? Maybe NXDOMAIN entries?
The negative catch entries don't seem to cause any problems... I just tried the following steps.
- dig printer9.mylocaldomain.org, no results
- dumped the cache
- fgrep printer9 unboundcache.file
- msg entry exists "msg printer9.mylocaldomain.org. IN A 33155 1 169 3 0 1 0" (I'm ignorant about what that actually means though, is that a negative cache entry?)
- Added a host override for that host.
- reloaded the dumped cache
- dig printer9.mylocaldomain.org returns the correct results
Maybe the problem is with existing dns entries, that are now being overriden?
- dig testsite.mylocaldomain.org, returns current A record.
- dump unbound cache
- fgrep cache file "testsite.mylocaldomain.org. 864 IN A 18.22.82.21"
- Add domain override for testsite.mylocaldomain.org
- Restore the dump.
- dig testsite.mylocaldomain.org returns the correct info, it wasn't overwritten by the restore.
So maybe it would make sense to now revive that feature?
-
@johnpoz said in Unbound seems to be restarting frequently:
@swixo said in Unbound seems to be restarting frequently:
This is a workaround and in some cases undesirable.
I don't think anyone would disagree with that. It has been a sore point for a long time.
Agree it not very desirable for unbound to restart and loose its cache on every dhcp, etc.
Still hoping for a fix here. Another big time-waster network issue emerged that came down to this issue. Certain MAC clients getting stuck if they make a DNS request during the reload time.
Who do I have to pay to get this fixed properly?
-
@swixo said in Unbound seems to be restarting frequently:
Who do I have to pay to get this fixed properly?
That's a classic one.
Most ISP's, if not all, explain : first, power up our modem router. As soon as it started, power up your LAN devices. This is even more true when there is a modem before pfSense : first the modem, then pfSense, then the rest.
Some 'dumb' devices start way faster as our routers, and are ready to go, when pfSense or any router has an entire OS to boot.First : ditch the device that have a broken client DHCP. If the device's DHCP clients starts, it's ok there is no answer from the DHCP server (= pfSense). The protocol supports a 60+ delay just fine.
Solution : apply the known 'power' rule, or get yourself a fast (like very fast) router device.
A 32 Mhz low power ARM device doesn't boot with the same speed as a 3 Ghz I9 core ;)@swixo said in Unbound seems to be restarting frequently:
Agree it not very desirable for unbound to restart and loose its cache on every dhcp, etc.
While waiting :
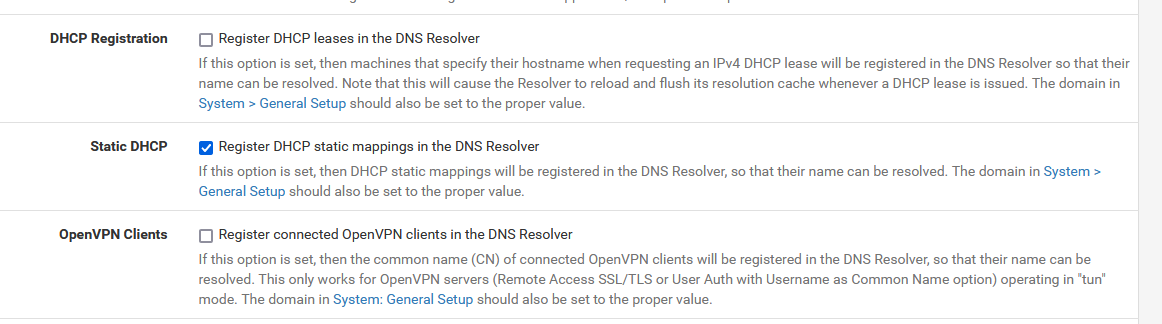
and add DHCP MAC leases for the few (or all) all your LAN devices.
Done. -
@swixo said in Unbound seems to be restarting frequently:
Still hoping for a fix here.
I know nothing about how it is implemented internally however if it was possible, rather than restarting unbound, it would be nice if a second instance of unbound was started and initialised. After which the old could be killed and the new connected to the interfaces.
Probably not practical however if it was it may reduce system down time. The equivalent of running up a live spare.
-
@swixo said in Unbound seems to be restarting frequently:
Who do I have to pay to get this fixed properly?
It seems like there is a fix, dhcpleases needs to be fixed to not restart unbound. There is code at https://github.com/pfsense/FreeBSD-ports/pull/751 but it needs more work. You may want to post a bounty there and see if anyone would be willing to work on polishing it up so it can be accepted.
-
@stompro what about it needs to be "polished"? Just the fact that there are merge conflicts?
-
Nothing to add right now, other than: count me in as someone who hopes this gets addressed. The closest we've come appears to still be this draft PR from 2+ years ago.
I personally don't use the "register DHCP leases" option but most customers expect stuff like "a device named
LAPTOP_3f7ea4connects to the network, then try to connect tosmb://LAPTOP_3f7ea4should work"...