Update to 2.5.0 broke DHCP relay
-
@gertjan But my production environment generates a startup command for the DHCP relay with
lo0included.
This is not there in 2.4.5_1, but following an upgrade to 2.5.0 this appears, and there is no functioning DHCP relay process started by default in that situation. What I'm trying to do is work out what is triggering the inclusion of thelo0within the startup process.
There is nolo0anywhere in my config, nor has disabling services (eg. squid, OpenVPN) on the production configuration gained me working DHCP forwarding. -
Redmine issue created:
https://redmine.pfsense.org/issues/11523 -
I tried the beta of 2.5, and discovered the same thing.
I posted my 2.5 findings in here:
[https://forum.netgate.com/topic/157022/not-sure-if-it-is-a-bug-or-not-dhcprelay-in-2-5?_=1614502774329](link url)Hope this helps.
I have upgraded to 2.5, and it seems to be working on my setup.Cheers
Elfranko
-
@viktor_g
I can confirm, that this issue relates to routing as already mentioned on redmine, and it doesn't exist in earlier Versions of pfSense.Having this configuration, where LAN is for Management only, and WAN is for Connection to Internet Router, DHCP-Server is on opt2, and Test-Computer trying to get IP via DHCP is on opt3:
<interfaces> <wan> <enable></enable> <if>hn2</if> <blockbogons></blockbogons> <descr><![CDATA[WAN]]></descr> <spoofmac></spoofmac> <ipaddr>172.30.0.99</ipaddr> <subnet>16</subnet> <gateway>WANGW</gateway> </wan> <lan> <enable></enable> <if>hn0</if> <ipaddr>10.100.0.99</ipaddr> <subnet>16</subnet> <gateway></gateway> <gatewayv6></gatewayv6> <descr><![CDATA[LAN]]></descr> </lan> <opt2> <descr><![CDATA[TestDC]]></descr> <if>hn3</if> <enable></enable> <spoofmac></spoofmac> <ipaddr>10.199.0.1</ipaddr> <subnet>24</subnet> </opt2> <opt3> <descr><![CDATA[Test1]]></descr> <if>hn1</if> <enable></enable> <spoofmac></spoofmac> <ipaddr>10.99.1.1</ipaddr> <subnet>24</subnet> </opt3> </interfaces> <staticroutes> <route> <network>10.0.0.0/8</network> <gateway>Null4</gateway> <descr><![CDATA[Default bei RFC 1918, Private Class A]]></descr> </route> <route> <network>172.16.0.0/12</network> <gateway>Null4</gateway> <descr><![CDATA[Default bei RFC 1918, Private Class B]]></descr> </route> <route> <network>192.168.0.0/16</network> <gateway>Null4</gateway> <descr><![CDATA[Default bei RFC 1918, Private Class C]]></descr> </route> </staticroutes> <dhcrelay> <enable></enable> <interface>opt3</interface> <agentoption></agentoption> <server>10.199.0.11</server> </dhcrelay>The NULL-Routes are to avoid Packets with local Addresses going to Internet (implicit Routes of direct attached Subnets have higher Priority).
With this configuration you cannot start DHCP-Relay Service (dhcrelay).
If you modify the NULL-Route "10.0.0.0/8" to something where the Subnet to the DHCP-Server is not part of (in my configuration e.g. "10.0.0.0/9"), then everything works fine.
Remark: After modifying Routes you have to reboot pfSense, because already existing routes were not replaced, but the modified route is added (no automatic flush of routing cache).
-
Try to apply Patch ID 7990de53bfc8267d1dd96636a175929a35cbe664 to fix DHCP Relay issue
see https://redmine.pfsense.org/issues/11475
@roland_v said in Update to 2.5.0 broke DHCP relay:
Remark: After modifying Routes you have to reboot pfSense, because already existing routes were not replaced, but the modified route is added (no automatic flush of routing cache).
Could you create a new redmine issue for this?
-
@viktor_g
Because I'm not able to build pfSense from source, I tried last development snapshot built on Tue Mar 02 01:18:30 EST 2021.With this version the DHCP-Relay works as expected.
For "Error on updating routing table after modifying static routes" I will open a new redmin issue as requested.
-
@viktor_g said in Update to 2.5.0 broke DHCP relay:
Try to apply Patch ID 7990de53bfc8267d1dd96636a175929a35cbe664 to fix DHCP Relay issue
Thanks, this patch fixed my identical problem.
For future reference, because some people might not know about it: See https://docs.netgate.com/pfsense/en/latest/development/system-patches.html for how to apply such patches to an existing installation.
--
Christian -
Hi,
just stepped on the same issue with PfSense 2.6.0
The Patch didnt pass the check, so i can´t apply it.My setup contains several LAN adapters leading to several (/24) Subnets.
The DHCP server is reachable on a remote system via Open VPN.Can You help me out?
/usr/bin/patch --directory='/' -t --strip '2' -i '/var/patches/6241d97843a1b.patch' --check --forward --ignore-whitespace Hmm... Looks like a unified diff to me... The text leading up to this was: -------------------------- |From 7990de53bfc8267d1dd96636a175929a35cbe664 Mon Sep 17 00:00:00 2001 |From: Viktor G <viktor@netgate.com> |Date: Thu, 25 Feb 2021 16:42:35 +0300 |Subject: [PATCH] route_get() optimization. Fixes #11475 | |--- | src/etc/inc/interfaces.inc | 2 +- | src/etc/inc/util.inc | 50 +++++++++++++++++++++++++++++--------- | 2 files changed, 39 insertions(+), 13 deletions(-) | |diff --git a/src/etc/inc/interfaces.inc b/src/etc/inc/interfaces.inc |index 35206915d92..307e76edcef 100644 |--- a/src/etc/inc/interfaces.inc |+++ b/src/etc/inc/interfaces.inc -------------------------- Patching file etc/inc/interfaces.inc using Plan A... Ignoring previously applied (or reversed) patch. Hunk #1 ignored at 6041. 1 out of 1 hunks ignored while patching etc/inc/interfaces.inc Hmm... The next patch looks like a unified diff to me... The text leading up to this was: -------------------------- |diff --git a/src/etc/inc/util.inc b/src/etc/inc/util.inc |index 6f94b0da41e..bc5178dee61 100644 |--- a/src/etc/inc/util.inc |+++ b/src/etc/inc/util.inc -------------------------- Patching file etc/inc/util.inc using Plan A... Ignoring previously applied (or reversed) patch. Hunk #1 ignored at 2692. Hunk #2 ignored at 2707. Hunk #3 ignored at 2755. 3 out of 3 hunks ignored while patching etc/inc/util.inc done /usr/bin/patch --directory='/' -f --strip '2' -i '/var/patches/6241d97843a1b.patch' --check --reverse --ignore-whitespace Hmm... Looks like a unified diff to me... The text leading up to this was: -------------------------- |From 7990de53bfc8267d1dd96636a175929a35cbe664 Mon Sep 17 00:00:00 2001 |From: Viktor G <viktor@netgate.com> |Date: Thu, 25 Feb 2021 16:42:35 +0300 |Subject: [PATCH] route_get() optimization. Fixes #11475 | |--- | src/etc/inc/interfaces.inc | 2 +- | src/etc/inc/util.inc | 50 +++++++++++++++++++++++++++++--------- | 2 files changed, 39 insertions(+), 13 deletions(-) | |diff --git a/src/etc/inc/interfaces.inc b/src/etc/inc/interfaces.inc |index 35206915d92..307e76edcef 100644 |--- a/src/etc/inc/interfaces.inc |+++ b/src/etc/inc/interfaces.inc -------------------------- Patching file etc/inc/interfaces.inc using Plan A... Hunk #1 succeeded at 6041 (offset -118 lines). Hmm... The next patch looks like a unified diff to me... The text leading up to this was: -------------------------- |diff --git a/src/etc/inc/util.inc b/src/etc/inc/util.inc |index 6f94b0da41e..bc5178dee61 100644 |--- a/src/etc/inc/util.inc |+++ b/src/etc/inc/util.inc -------------------------- Patching file etc/inc/util.inc using Plan A... Hunk #1 succeeded at 2692 (offset 43 lines). Hunk #2 failed at 2705. Hunk #3 succeeded at 2690 (offset 4 lines). 1 out of 3 hunks failed while patching etc/inc/util.inc done -
@wurst You can simply upgrade to the latest pfSense version
-
-
@wurst. I am not quite sure i do understand your problem right:
Your DHCP-Server is outside of the nets of pfsense, upstream on the openVPN-Interface, right ?Does the dhcplog reveal anything ?
cat /var/log/dhcpd.log
If you login into the box and do a
#ps aux | grep "dhcrelay"
show that dhcrelay is running ?I am not quite sure if you can workaround using
/usr/local/sbin/dhcrelay [-id <for all interfaces which require DHCP>] -iu <your openvpn-interface> -a -m replace IP_dhcp-server1 IP_dhcpsever2
That might be a fast fix for the problem.
-
@fwcheck
Hi, sorry for my late reply.
The system went productive, so I used the Switch for DHCP relaying.Now I am back with another System, next try.
Heres my test with the line You recommended:
/usr/local/sbin/dhcrelay -id em2 -iu ovpns2 -a -m replace 10.1.1.12 Requesting: em2 as upstream: N downstream: Y Requesting: ovpns2 as upstream: Y downstream: N Internet Systems Consortium DHCP Relay Agent 4.4.2-P1 Copyright 2004-2021 Internet Systems Consortium. All rights reserved. For info, please visit https://www.isc.org/software/dhcp/ Unsupported device type 23 for "ovpns2"--> Unsupported Device Type 23
OK. The openvpn adapter is not supported.
If I start it without specifying "-iu", the machine starts:/usr/local/sbin/dhcrelay -d -id em2 -a -m replace 10.1.1.12 Requesting: em2 as upstream: N downstream: Y Internet Systems Consortium DHCP Relay Agent 4.4.2-P1 Copyright 2004-2021 Internet Systems Consortium. All rights reserved. For info, please visit https://www.isc.org/software/dhcp/ Listening on BPF/em2/00:0c:29:a0:6f:7c Sending on BPF/em2/00:0c:29:a0:6f:7c Sending on Socket/fallback Adding 8-byte relay agent option Forwarded BOOTREQUEST for 00:0c:29:38:09:f2 to 10.1.1.12 Adding 8-byte relay agent option Forwarded BOOTREQUEST for 00:0c:29:38:09:f2 to 10.1.1.12 Adding 8-byte relay agent option Forwarded BOOTREQUEST for 00:0c:29:38:09:f2 to 10.1.1.12The DHCP request ist recieved by DHCP Server 10.1.1.12, it replying with DHCP offer:
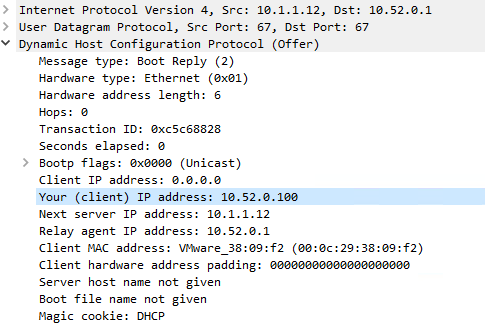
The Packet recieves at the Pfsense but nothing happens...
-
I'm seeing the same issue as @wurst but on a new (currently testing) installation which has not previously seen DHCP relay operational and has not been put into production yet.
At our main site I have PFSense router #1 (2.6.0) running an OpenVPN server, on the LAN network of this router are Microsoft DHCP servers. (PFSense #1 LAN address, 10.0.1.254/16, DHCP server 10.0.0.200)
At the remote site PFSense (2.6.0) box #2 running an OpenVPN client in peer to peer mode with layer 3 tunnelling. (LAN address 10.20.1.254/16)
Routing is all set up and working well, and I have been doing all my initial testing simply using the local DHCP server on PFSense route #2. For various reasons (including DNS registration, and potential PXE boot to a WDS server) I would prefer to use DHCP relay back to the Microsoft DHCP servers rather than a local DHCP server.
So I disabled DHCP, enabled DHCP relay and it..... doesn't work. Here is a screenshot of the configuration:
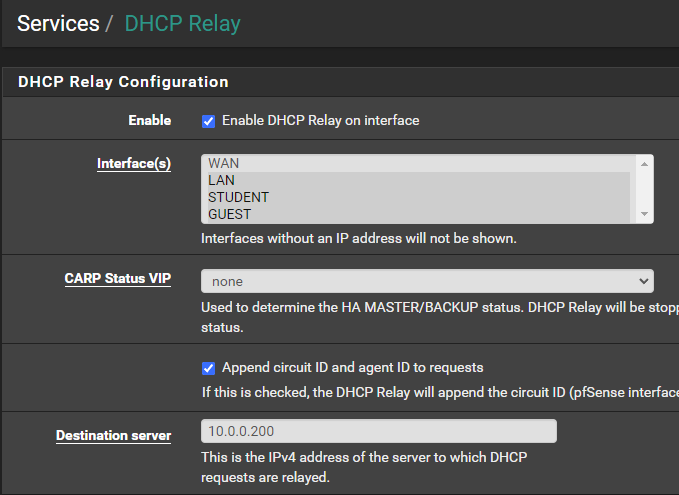
Two VLAN's are configured (STUDENT and GUEST) but at the moment I am
only testing with the untagged VLAN, LAN.Tcpdump on PFSense #2 confirms DHCP discovers are being received from a test client on LAN, but nothing is being forwarded over the OpenVPN link. It wasn't until I was looking directly at /var/log/syslog that I noticed this error which lead me to this (and other) threads:
Nov 12 15:46:48 pfSense2 php-fpm[70836]: /services_dhcp_relay.php: No suitable upstream interfaces found for running dhcrelay!It appears that the dhcp relay daemon is not even being started at all. The "upstream interface" to the DHCP server would be the OpenVPN tunnel - which is already up and running at the time that I'm trying to start the DHCP relay.
Also, I do have interfaces "assigned" to the OpenVPN tunnel, as I know you can run an OpenVPN tunnel without doing this but this can have some limitations.
DHCP relay not working is unfortunate and is a bit of a showstopper for me to roll out this OpenVPN tunnel after doing 90% of the work setting it up and testing it. I also don't have a layer 3 switch at the remote site to do DHCP relay, as the site is very small with only 3 computers and 2 wireless base stations so doesn't warrant an expensive switch..
At the moment we have other equipment providing this VPN site-site link which has significant limitations and needs replacing - PFSense would do a much better job of it - if the DHCP relay would work for me...

I'm happy to provide logs and do testing on this issue, and while I'm somewhat of a FreeBSD noob I do have a lot of Linux experience so I can find my way around the command line fairly well.
At the moment the link is not in production, in fact PFSense router #2 which will be at the remote office is actually in my house at the moment, so I can test anything without disrupting anyone, so I have an ideal test environment.
-
I've been playing around with running dhcrelay manually and noticed a couple of things.
One is that the OpenVPN tunnel is not allowed as an upstream interface:
/usr/local/sbin/dhcrelay -a -iu ovpnc1 -i em1 10.0.0.200 Requesting: ovpnc1 as upstream: Y downstream: N Requesting: em1 as upstream: Y downstream: Y Internet Systems Consortium DHCP Relay Agent 4.4.2-P1 Copyright 2004-2021 Internet Systems Consortium. All rights reserved. For info, please visit https://www.isc.org/software/dhcp/ Listening on BPF/em1/00:1e:67:23:e4:d1 Sending on BPF/em1/00:1e:67:23:e4:d1 Unsupported device type 23 for "ovpnc1" If you think you have received this message due to a bug rather than a configuration issue please read the section on submitting bugs on either our web page at www.isc.org or in the README file before submitting a bug. These pages explain the proper process and the information we find helpful for debugging. exiting.However it seems that the -iu option is actually optional. So trying to run without this option is a lot more successful:
/usr/local/sbin/dhcrelay -a -i em1 10.0.0.200 Requesting: em1 as upstream: Y downstream: Y Internet Systems Consortium DHCP Relay Agent 4.4.2-P1 Copyright 2004-2021 Internet Systems Consortium. All rights reserved. For info, please visit https://www.isc.org/software/dhcp/ Listening on BPF/em1/00:1e:67:23:e4:d1 Sending on BPF/em1/00:1e:67:23:e4:d1 Sending on Socket/fallbackMonitoring with tcpdump I am much closer now:
tcpdump -n -i ovpnc1 port 67 or 68 -v tcpdump: listening on ovpnc1, link-type NULL (BSD loopback), capture size 262144 bytes 21:20:27.963577 IP (tos 0x0, ttl 64, id 60806, offset 0, flags [none], proto UDP (17), length 328) 172.23.0.2.67 > 10.0.0.200.67: BOOTP/DHCP, Request from e8:03:9a:e8:2f:b2, length 300, hops 1, xid 0x88500a27, secs 3328, Flags [Broadcast] Gateway-IP 10.20.1.254 Client-Ethernet-Address e8:03:9a:e8:2f:b2 Vendor-rfc1048 Extensions Magic Cookie 0x63825363 DHCP-Message Option 53, length 1: Discover Client-ID Option 61, length 7: ether e8:03:9a:e8:2f:b2 Hostname Option 12, length 9: "IT-LAPTOP" Vendor-Class Option 60, length 8: "MSFT 5.0" Parameter-Request Option 55, length 14: Subnet-Mask, Default-Gateway, Domain-Name-Server, Domain-Name Router-Discovery, Static-Route, Vendor-Option, Netbios-Name-Server Netbios-Node, Netbios-Scope, Option 119, Classless-Static-Route Classless-Static-Route-Microsoft, Option 252 Agent-Information Option 82, length 5: Circuit-ID SubOption 1, length 3: em1 21:20:27.982545 IP (tos 0x0, ttl 126, id 17644, offset 0, flags [none], proto UDP (17), length 353) 10.0.0.200.67 > 10.20.1.254.67: BOOTP/DHCP, Reply, length 325, xid 0x88500a27, Flags [Broadcast] Your-IP 10.20.130.1 Server-IP 10.0.0.200 Gateway-IP 10.20.1.254 Client-Ethernet-Address e8:03:9a:e8:2f:b2 Vendor-rfc1048 Extensions Magic Cookie 0x63825363 DHCP-Message Option 53, length 1: Offer Subnet-Mask Option 1, length 4: 255.255.0.0 RN Option 58, length 4: 86400 RB Option 59, length 4: 151200 Lease-Time Option 51, length 4: 172800 Server-ID Option 54, length 4: 10.0.0.200 Default-Gateway Option 3, length 4: 10.20.1.254 Domain-Name-Server Option 6, length 8: 10.0.0.253,10.0.0.249 Domain-Name Option 15, length 17: "dummy-domain.local^@" Netbios-Name-Server Option 44, length 4: 10.0.0.253 Netbios-Node Option 46, length 1: h-node Agent-Information Option 82, length 5: Circuit-ID SubOption 1, length 3: em1The request is being forwarded to the DHCP server at the other end of the openvpn link and the reply is coming back.
The request is being sent using the link local address of the OpenVPN link - 172.23.0.2, with Gateway-IP of 10.20.1.254 emended in the request - which is the router's IP address on the subnet which the DHCP query is being made from.
Unfortunately the Microsoft DHCP server is addressing its reply to 10.20.1.254, which is the Gateway-IP within the initial request, not the actually address that the request came from.
As a result dhcrelay seems to be ignoring the response. Close but still so far...
The -U option looks like it should help, however unfortunately it also won't accept the openvpn link as a valid interface.
Even when explicitly trying to bind dhcrelay to the LAN interface for upstream requests, it still uses the openvpn link local address as the source address.
I feel like some kind of firewall rewrite rule could help here as a workaround but I don't know enough about pf on bsd to know where to start.
-
Ok, for anyone else coming across this thread in future, I've got it working thanks to this post.
In short, TUN devices don't have MAC addresses (which dhcrelay needs to bind to) but TAP devices do. So I followed the advice to switch both ends of the site-to-site link from TUN (layer 3) to TAP (layer 2) devices, and added the extra route options that are not set automatically for a TAP device to restore routing.
In my case at the server end I added
route-gateway 172.23.0.2and at the client endroute-gateway 172.23.0.1, so that both ends have routes pointing at each other. I didn't need to change any of my other static routes or firewall rules.After that I was able to enable DHCP relay through the GUI and it works. I even managed to do a successful PXE boot across the tunnel simply by adding the Windows Deployment server as an additional (3rd) DHCP server in DHCP relay settings.

The only issue I have now is that I really need to be able to forward one VLAN's DHCP requests to a different pair of DHCP servers on a different Windows domain than the other VLAN's, however only one forwarder can be enabled through the GUI.
Since it binds explicitly to certain interfaces it looks like I may be able to manually run a second copy of dhcrelay from something like the shellcmd package. Will give that a try tomorrow.
The only other option would be to add another DHCP relay upstream which is capable of redirecting requests to different DHCP servers based on a ruleset, but I'd like to avoid that if possible as it is just adding further complication.
-
Yes!
--> Set both OenVPN tunnel ends to TAP.
--> Create Gateways manually in GUI on both sides.
--> Start DHCP Relay from GUII did the whole setup with redundant OpenVPN tunnels, each connected via different physical WAN links on both sides.
Routing is done by OSPF2.
This way I could set it all remotely, without beeing locked out.
Everything perfect,Switching to else VPN types will be problematic in future, of course one day Wireguard will be without alternatives performance wise.
For the moment everything works fine, special thanks to DBMandrake for completing the project!
-
@wurst Great that my post helped you finish setting this up!
Even when I figure something out myself or through other research I like to come back and finish a thread so there is a working solution for others to find if they come looking with the same problem.
Just to clarify for others (I can't edit my post now) the route-gateway commands are added to Advanced configuration, custom options in the OpenVPN server and client configuration for the link.
Regarding my two domain configuration - I did some testing with dhcrelay at the command line and unfortunately it is not possible to run two instances with the same upstream link - the daemon binds to the upstream interface (ovpnc1) with a BPF (packet filter) binding, however the second instance refuses to start saying the ports are already in use. This seems to be a coding limitation of dhcrelay because you can actually have more than one application listening to the same UDP ports on the same interface if you use raw sockets. (I guess it doesn't use raw sockets, which is surprising for DHCP)
So the only way to run two instances would be to use two different VPN tunnels to the two different domains, and at least one of the instances would need to be run from the command line or a startup script... messy and not very maintainable in the future.
However for my purposes one instance is actually enough. I realised that you can add many DHCP servers in the dhcrelay config, in the GUI as well, so I simply added all 5 of them - two are primary DHCP servers for the two domains, two are failover DHCP servers for the two domains (usually inactive) and one is the PXE boot server.
This causes every client DHCP broadcast request to be sent to all 5 servers as unicast. Not very efficient, but it works, as only the server which owns the scope for that particular VLAN (and is not in failover standby) will reply, the others just ignore the requests. And in the case of PXE boot the PXE boot server is the one that replies.
This can be seen here, captured on the ovpnc1 interface, when a client on VLAN 1 sends a DHCP request where only the primary DHCP server for Domain 1 responds:
16:17:41.702734 IP 172.23.0.2.67 > 10.0.0.250.67: BOOTP/DHCP, Request from b8:03:05:c7:0e:6b, length 334 16:17:41.702758 IP 172.23.0.2.67 > 10.0.0.248.67: BOOTP/DHCP, Request from b8:03:05:c7:0e:6b, length 334 16:17:41.702774 IP 172.23.0.2.67 > 10.0.0.249.67: BOOTP/DHCP, Request from b8:03:05:c7:0e:6b, length 334 16:17:41.702787 IP 172.23.0.2.67 > 10.0.0.253.67: BOOTP/DHCP, Request from b8:03:05:c7:0e:6b, length 334 16:17:41.702801 IP 172.23.0.2.67 > 10.0.1.6.67: BOOTP/DHCP, Request from b8:03:05:c7:0e:6b, length 334 16:17:41.719679 IP 10.0.0.253.67 > 10.20.1.254.67: BOOTP/DHCP, Reply, length 330And here, when a client on VLAN 2 sends a DHCP request where only the primary DHCP server for Domain 2 responds:
16:18:59.910858 IP 172.23.0.2.67 > 10.0.0.250.67: BOOTP/DHCP, Request from b8:03:05:c7:0e:6b, length 336 16:18:59.910880 IP 172.23.0.2.67 > 10.0.0.248.67: BOOTP/DHCP, Request from b8:03:05:c7:0e:6b, length 336 16:18:59.910894 IP 172.23.0.2.67 > 10.0.0.249.67: BOOTP/DHCP, Request from b8:03:05:c7:0e:6b, length 336 16:18:59.910908 IP 172.23.0.2.67 > 10.0.0.253.67: BOOTP/DHCP, Request from b8:03:05:c7:0e:6b, length 336 16:18:59.910921 IP 172.23.0.2.67 > 10.0.1.6.67: BOOTP/DHCP, Request from b8:03:05:c7:0e:6b, length 336 16:18:59.925943 IP 10.0.0.248.67 > 10.22.1.254.67: BOOTP/DHCP, Reply, length 333As we only have a small number of devices at this remote site I'm not worried about the overheads of doing this. Even if I was able to separate the forwarding requests for the two domains I would still have 3 requests per domain anyway, primary and failover DHCP and (shared) PXE boot server.
People should keep in mind that this configuration of relaying to all DHCP servers can potentially cause information leakage - eg the DHCP servers in one domain see queries from devices in the other domain even if they aren't responding to them. So you would only want to do this when the two domains are "friendly" and owned by the same organisation.
If not separate dhcrelay clients on other devices or separate tunnels would be warranted to avoid DHCP servers seeing queries from outside their organisation.