Any known issues with HAproxy on 2.5.2?
-
40% of how much? With HAProxy running?
-
This one has only 4GB in it because it's very low traffic and on a 50Mbps connection. Maybe I never noticed it was at 40% but I think it would have gotten my attention.
-
You can check the process list in Diag > System Activity to see if any one thing is using it.
If not and it is not actually exhausted it's probably not an issue.
Steve
-
Nothing really obvious other than this;
2275 root 20 0 9988K 1368K select 1 0:00 0.00% /sbin/devd -q -f /etc/pfSense-devd.conf
-
Can we see the actual usage screen? 1.4MB is nothing, something must be using more than that.
-
Do you mean the dashboard or all of the processes?
-
The processes. So for example the output of
top -aSPo resafter a few cycles, like:last pid: 79792; load averages: 0.31, 0.35, 0.30 up 1+05:39:48 19:49:48 148 processes: 2 running, 145 sleeping, 1 waiting CPU 0: 0.0% user, 0.0% nice, 0.8% system, 0.0% interrupt, 99.2% idle CPU 1: 0.0% user, 0.0% nice, 0.4% system, 1.2% interrupt, 98.4% idle Mem: 97M Active, 717M Inact, 655M Wired, 1840M Free ARC: 431M Total, 120M MFU, 289M MRU, 32K Anon, 3266K Header, 19M Other 354M Compressed, 740M Uncompressed, 2.09:1 Ratio PID USERNAME THR PRI NICE SIZE RES STATE C TIME WCPU COMMAND 95987 root 2 20 0 417M 373M bpf 1 5:55 0.12% /usr/local/bin/snort -R _28847 -D -q --suppress-config-lo 48404 root 6 52 0 113M 86M kqread 0 0:00 0.00% /usr/local/sbin/radiusd 42053 root 1 52 0 140M 48M accept 0 1:16 0.00% php-fpm: pool nginx (php-fpm) 1262 root 1 52 0 140M 48M accept 1 1:03 0.00% php-fpm: pool nginx (php-fpm) 12485 root 1 52 0 141M 48M accept 1 1:14 0.00% php-fpm: pool nginx (php-fpm) 1261 root 1 52 0 140M 47M accept 0 1:43 0.00% php-fpm: pool nginx (php-fpm) 1466 root 1 20 0 141M 47M accept 1 1:06 0.00% php-fpm: pool nginx (php-fpm) 81073 squid 1 20 0 105M 37M kqread 1 4:17 0.03% (squid-1) --kid squid-1 -f /usr/local/etc/squid/squid.con 1260 root 1 20 0 100M 26M kqread 0 0:05 0.01% php-fpm: master process (/usr/local/lib/php-fpm.conf) (ph 39411 unbound 2 52 0 40M 20M kqread 1 0:00 0.00% /usr/local/sbin/unbound -c /var/unbound/unbound.conf 80523 squid 1 20 0 79M 19M wait 0 0:00 0.00% /usr/local/sbin/squid -f /usr/local/etc/squid/squid.conf 93560 root 17 52 0 50M 17M sigwai 1 0:12 0.00% /usr/local/libexec/ipsec/charon --use-syslog 44082 www 1 20 0 26M 14M kqread 1 0:01 0.00% /usr/local/sbin/haproxy -f /var/etc/haproxy/haproxy.cfg - 51992 root 10 20 0 65M 12M select 1 0:13 0.00% /usr/local/sbin/zebra -d 63253 dhcpd 1 20 0 22M 12M select 0 0:20 0.02% /usr/local/sbin/dhcpd -user dhcpd -group _dhcp -chroot /v 53603 root 4 20 0 33M 10M select 0 0:06 0.00% /usr/local/sbin/bgpd -d 32357 root 2 20 0 25M 9792K kqread 0 0:00 0.00% /usr/local/sbin/syslog-ng -p /var/run/syslog-ng.pid 23079 root 1 20 0 19M 9104K select 0 0:00 0.02% sshd: admin@pts/0 (sshd) 53811 root 1 20 0 28M 8480K kqread 1 0:05 0.00% nginx: worker process (nginx) 53681 root 1 20 0 28M 8312K kqread 0 0:02 0.00% nginx: worker process (nginx) 32255 root 1 52 0 18M 8220K wait 0 0:00 0.00% /usr/local/sbin/syslog-ng -p /var/run/syslog-ng.pid 25756 squid 1 20 0 17M 8084K select 1 0:11 0.02% (pinger) (pinger) 57293 squid 1 20 0 17M 8084K select 0 0:10 0.02% (pinger) (pinger) 97532 squid 1 20 0 17M 8084K select 1 0:11 0.02% (pinger) (pinger) -
That's what I thought but wasn't sure :).
Nothing too unusual.
I never noticed that before, 42M active, 118M Inact, 1471M Wired.
Is the system holding some memory in some sort of buffer or something?I've never seen that on Centos or other flavors I've worked with.
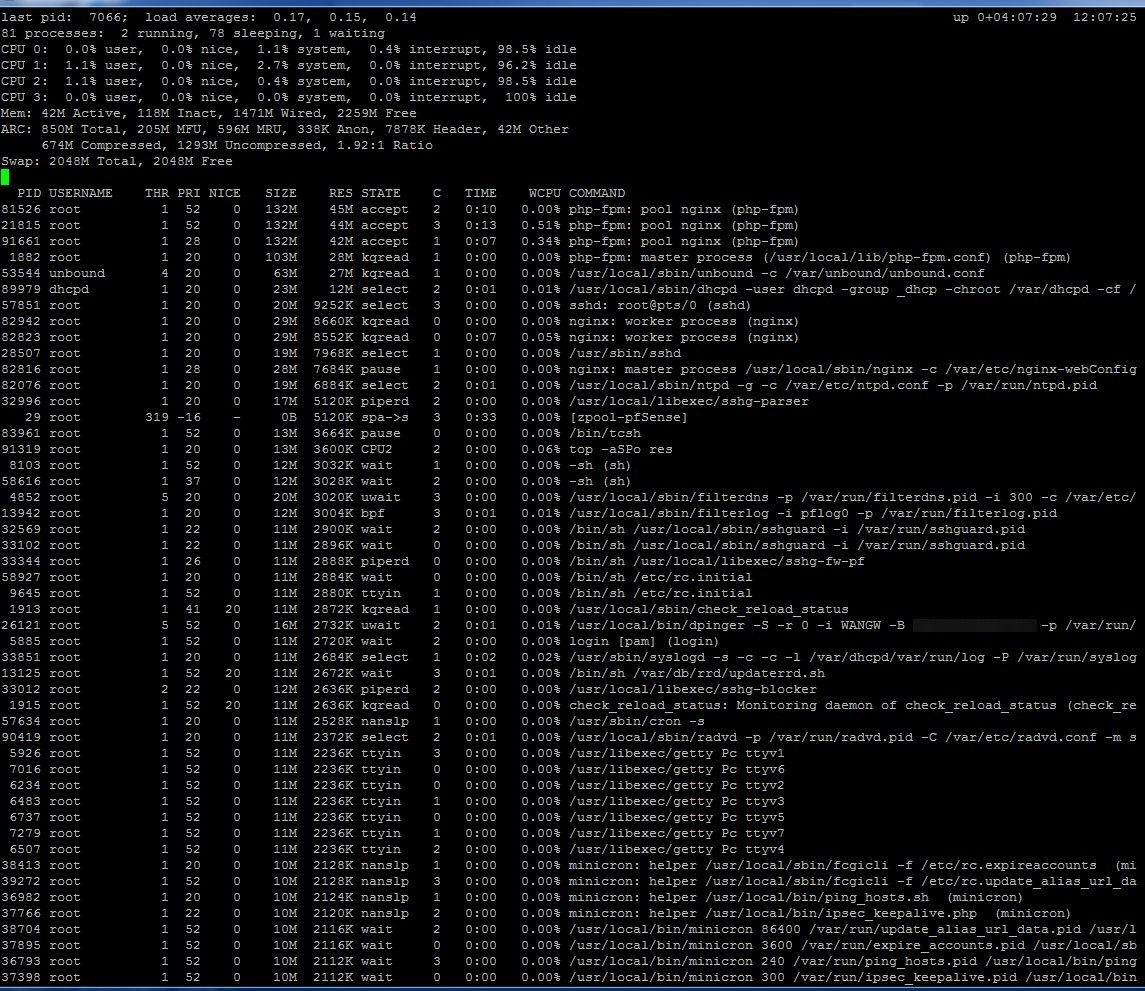
-
Mmm, so just wired memory from the kernel (probably).
It's not an issue as far as I know. If the actual free memory runs low the kernel will start releasing wired memory. It is different behaviour to 2.5.2 though.Steve
-
Sorry it took so long to get back to this but there is definitely something wrong with haproxy, at least on our device.
For the past while, we've been testing everything possible inside our network thinking something between the web connections, the application and the database must be wrong.
After an insane amount of hours troubleshooting, we could simply find nothing what so ever wrong with the application. The only clue was that clients were not communicating at the intervals they are set to.Eventually, we decided that maybe it's the Internet. Maybe because of the Ukraine war and lots of extra world wide hacking, maybe governments are filtering the net so much that it's caused some latency.
Yes, we started thinking it must be the Internet! :).
Then something dawned on me tonight after spending the entire day on this again. I remembered that I took haproxy out of the mix (as posted above) and things got way better there. Users are no longer getting gateway timeouts. I've been monitoring the logs since then.
This evening, I decided to take this other set of servers off haproxy, put just one online and give traffic direct access. Guess what? The timing is now almost dead on, no longer random and no more missing connections.
All data that is supposed to come in, is coming in, no missing data. It's haproxy causing the loss somehow.Here is a snip of us watching the logs and everything else a while ago. See the difference in timing? I'm only showing a snip but before haproxy was taken out, this client kept missing sending data, now it's dead on.
With load balancer # tail -f /var/log/httpd/access_log | grep "1.1.1.1" www.domain.com 1.1.1.1 - - [12/May/2022:20:22:10 -0700] "POST /app/test.php HTTP/1.1" 200 199351 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:20:22:40 -0700] "POST /app/test.php HTTP/1.1" 200 212418 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:20:23:50 -0700] "POST /app/test.php HTTP/1.1" 200 178076 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:20:24:21 -0700] "POST /app/test.php HTTP/1.1" 200 181307 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:20:24:32 -0700] "POST /app/test.php HTTP/1.1" 200 193764 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:20:24:36 -0700] "POST /app/test.php HTTP/1.1" 200 252216 1 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:20:24:41 -0700] "POST /app/test.php HTTP/1.1" 200 230704 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:20:25:10 -0700] "POST /app/test.php HTTP/1.1" 200 175718 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:20:25:21 -0700] "POST /app/test.php HTTP/1.1" 200 255809 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:20:25:31 -0700] "POST /app/test.php HTTP/1.1" 200 217827 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:20:26:19 -0700] "POST /app/test.php HTTP/1.1" 200 272213 1 "-" "curl/7.43.0" Without load balancer # tail -f /var/log/httpd/access_log | grep "1.1.1.1" www.domain.com 1.1.1.1 - - [12/May/2022:21:11:21 -0700] "POST /app/test.php HTTP/1.1" 200 580819 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:11:31 -0700] "POST /app/test.php HTTP/1.1" 200 430671 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:11:41 -0700] "POST /app/test.php HTTP/1.1" 200 550884 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:11:51 -0700] "POST /app/test.php HTTP/1.1" 200 564128 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:12:01 -0700] "POST /app/test.php HTTP/1.1" 200 418494 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:12:06 -0700] "POST /app/test.php HTTP/1.1" 200 303744 1 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:12:11 -0700] "POST /app/test.php HTTP/1.1" 200 364427 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:12:20 -0700] "POST /app/test.php HTTP/1.1" 200 285843 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:12:30 -0700] "POST /app/test.php HTTP/1.1" 200 234948 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:12:37 -0700] "POST /app/test.php HTTP/1.1" 200 310208 1 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:12:40 -0700] "POST /app/test.php HTTP/1.1" 200 182248 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:12:51 -0700] "POST /app/test.php HTTP/1.1" 200 381602 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:13:00 -0700] "POST /app/test.php HTTP/1.1" 200 246661 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:13:05 -0700] "POST /app/test.php HTTP/1.1" 200 258953 1 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:13:10 -0700] "POST /app/test.php HTTP/1.1" 200 225073 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:13:20 -0700] "POST /app/test.php HTTP/1.1" 200 185570 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:13:30 -0700] "POST /app/test.php HTTP/1.1" 200 296611 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:13:40 -0700] "POST /app/test.php HTTP/1.1" 200 259110 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:13:50 -0700] "POST /app/test.php HTTP/1.1" 200 210109 747 "-" "curl/7.43.0" www.domain.com 1.1.1.1 - - [12/May/2022:21:14:01 -0700] "POST /app/test.php HTTP/1.1" 200 392396 747 "-" "curl/7.43.0" -
BTW, just went to update.... got a seg fault.
0) Logout (SSH only) 9) pfTop 1) Assign Interfaces 10) Filter Logs 2) Set interface(s) IP address 11) Restart webConfigurator 3) Reset webConfigurator password 12) PHP shell + pfSense tools 4) Reset to factory defaults 13) Update from console 5) Reboot system 14) Disable Secure Shell (sshd) 6) Halt system 15) Restore recent configuration 7) Ping host 16) Restart PHP-FPM 8) Shell Enter an option: 13 >>> Updating repositories metadata... Updating pfSense-core repository catalogue... Fetching meta.conf: . done Fetching packagesite.pkg: . done Processing entries: . done pfSense-core repository update completed. 7 packages processed. Updating pfSense repository catalogue... Fetching meta.conf: . done Fetching packagesite.pkg: .......... done Processing entries: Processing entries............. done pfSense repository update completed. 515 packages processed. All repositories are up to date. Child process pid=55390 terminated abnormally: Segmentation fault **** WARNING **** Reboot will be required!! Proceed with upgrade? (y/N) y >>> Removing vital flag from php74... done. >>> Downloading upgrade packages... Updating pfSense-core repository catalogue... pfSense-core repository is up to date. Updating pfSense repository catalogue... pfSense repository is up to date. All repositories are up to date. Checking for upgrades (201 candidates): .... Child process pid=61867 terminated abnormally: Segmentation fault pfSense - Netgate Device ID: xxx From command line, with -d or not, I get to the same point of being told all is up to date but no option to upgrade. [2.5.2-RELEASE][root@]/root: pkg update Updating pfSense-core repository catalogue... pfSense-core repository is up to date. Updating pfSense repository catalogue... pfSense repository is up to date. All repositories are up to date. And (Not sure I want to say yes since I see seg fault) [2.5.2-RELEASE][root@c]/root: pfSense-upgrade >>> Setting vital flag on php74... done. >>> Updating repositories metadata... Updating pfSense-core repository catalogue... Fetching meta.conf: . done Fetching packagesite.pkg: . done Processing entries: . done pfSense-core repository update completed. 7 packages processed. Updating pfSense repository catalogue... Fetching meta.conf: . done Fetching packagesite.pkg: .......... done Processing entries: Processing entries............. done pfSense repository update completed. 515 packages processed. All repositories are up to date. Child process pid=48857 terminated abnormally: Segmentation fault **** WARNING **** Reboot will be required!! Proceed with upgrade? (y/N) -
Maybe the seg fault warnings are related to the haproxy problem.
I don't know and I'm not sure what to think now. Feels like the firewall might fail at some point which would be bad. -
If it's HAProxy not passing the traffic somehow then you should be able to prove that easily using a packet capture on the WAN side. You would still see the connections coming in from the client at regular intervals.
One thing to bare in mind is that HAproxy is an actual proxy so to changes the path of the connection compared to port forward. That might be relevant with the multiple WAN setup you have.
Is there anything logged from that segfault? That doesn't seems familiar at all in 2.5.2.
Steve
-
Well, what ever I do, it cannot be disruptive. Tihs problem plagued us to the point that members never came back, blaming our services.
I don't have any multiple WANs on this, traffic coming into this firewall is simply port forwarded to devices on its LAN and we were using haproxy.
The multiple WAN you mention are simply other firewalls that have their LAN side on the same 'cable' but simply co-exist with each other but in different networks.
I didn't get a chance to check for proof but I could set up another test to an isolated server on the LAN. It would just show the irregular traffic as I showed. I don't have physical access to inject something between the WAN and a device to monitor. Everything else seems to work as it should, just haproxy is showing this behavior.
As for segfaults, that was the first time I've seen those last night but it was also the first time I tried upgrading from the cli as you had suggested.
-
HAProxy is running on the same firewall as the traffic is passing though right?
And when you disable HAProxy as a test you are simply enabling a port forward there instead to just one backend server?
Doing that makes several changes. You are using just one backend, are you sure the load-balancing is not breaking the required connection between the server and client? Have you tried just enabling one backend server through HAProxy?
When you are running the proxy the TCP connection is terminated in HAProxy and a separate connection is created to the backend. That means the backend will reply to HAProxy directly in it's pwn subnet rather than try to reply to the client via it's default route. That may or may not make a difference but I could certainly imagine it might in your network setup. Though I would expect it to fail without HAProxy in that case.
Steve
-
Correct, on the same 2.5.2 firewall I'm having a hard time updating and seeing segfaults on.
Correct, I've not actually disabled the haproxy service, I simply bypassed it by creating a new forward rule that goes to just one of the back end servers.
Yes, we've done a crazy amount of testing and that also included husing haproxy to just one back end server. That's how it's been configured for a week as part of our testing. Only last night did I decide to bypass the single back end server from haproxy and direct using a nat rule.
That may or may not make a difference but I could certainly imagine it >might in your network setup. Though I would expect it to fail without >HAProxy in that case.
There really isn't anything that unusual about this network, it's just that it has multiple gateways on the same cable but clients and devices use their own gateways so there are no conflicts that I've noticed at least.
Plus, the traffic to the second pfsense firewall is minimal, it's just device management traffic. All production stuff goes through the firewall we're talking about.
It's the same as if you had one LAN switch, not using VLAN, nothing fancy, just one LAN switch. On that switch, you'd have some devices that are configured with 172.16.1.x. IPs talking to each other and other devices with say 10.0.0.x talking to other 10.0.0.x devices on the same network. The only thing is, they are sharing the same physical cable and switch.
-
Yes, multiple gateways on one network segment opens numerous possibilities to fail!
Using HAProxy you could use a backend that was not using the firewall as it's default route. That would fail if you then tried to use a port forward instead.
Since that's not what you're seeing here you are not hitting that particular failure mode but you need to be aware of it when using a network setup like that.Steve
-
I guess it means there's something I'm not understanding :).
I've always had devices on different subnets communicating together with and without firewalls.
Devices using 172.16.x.x talk with others on 172.16.x.x, 10.0.0.x talk with devices on 10.0.0.x and 192.168.0.x talk with others on the same.
Some use a gateway, some don't depending on what their tasks are.In this case, it's that there is only one physical cable to get a LAN from one point to another but on that cable, there are now two firewalls, 10.0.0.x and 10.1.1.x. Only one firewall has DHCP, the other doesn't.
Devices on the first firewall have that one as their gw and communicate with other devices on the same network subnet.
Devices on the second firewall have that one sa their gw and communicate with other devices on the same network subnet.This conversation keeps diluting the problem with haproxy but you think there is a possibility that haproxy is not working well because of the above network.
I've not seen any problems so based on your input, there must be something I am missing.
Devices communicate with their own gw. The only time it was weird was while ARP was cached all over and one left over rule was overlooked.
I've not seen any problems since other than this haproxy and not being able to update the firewall.
Using HAProxy you could use a backend that was not using the
firewall as it's default route.This firewall is only working with devices that have the same network which is 10.0.0.x/24.
The back end servers are all on the same 10.0.0.x/24 and have the above as their gw.That would fail if you then tried to use a port forward instead.
I think you are saying if I used 10.0.0.1 firewall with haproxy and sent traffic from that to 10.1.1.x/24 devices? Not doing that for sure :).
It would not work anyhow since the devices on 10.1.1.x have their gw as 10.1.1.1 so traffic would not get to them without funky a config using vips or something and their outgoing traffic would want to go out the 10.1.1.1 gw.
Since that's not what you're seeing here you are not hitting that particular >failure mode but you need to be aware of it when using a network setup >like that.
Ok, I think you're just warning me not to do stuff like that. I agree, I won't be doing that.
I believe you helped me when I was setting all this up and with some other problems and I've learned quite a lot, even if I don't yet remember it all just yet.
-
Yes, just be aware it would be very easy to introduce asymmetry and I've seen that bite people many, many times!
If you really are seeing an issue in HAProxy then a pcap should prove it.
I would expect to see something logged though.
Was this working in the old network setup?
Steve
-
We had the proxy going for the past couple of years approximately.
During that time, we've had lots of complaints about 500/504 but always blamed our own resources, never once thinking it could be the proxy.So to answer your question, there is really no way to know other than when I posted this, that was around the time we realized what was happening.
We had taken the proxy out of the mix to do some testing so it was off for maybe a week. Then when we re-enabled it, the timeout complaints started again which got me wondering what was going on. That's when I disabled it again and since then, the complaints stopped and we too were no longer getting them.
We know one problem was a back end one in that there was an issue with the database and it wasn't responding fast enough causing 504's but we were aware of those and could see them in the logs.