Major DNS Bug 23.01 with Quad9 on SSL
-
@robbiett Updated to the latest release a few minutes ago. Not listening to the suggestions to disable IPv6 as I have been running IPv6 for a few years now without major issue until recently. DNS over TLS has been a major benefit as our ISP redirects port 53 DNS to their own servers and redirects mistyped domains or NXDOMAINS to their ad pages. This isn't cool in any way shape or form.
So here are the results that I am seeing:
First a domain that hasn't been queried since Unbound restarted:
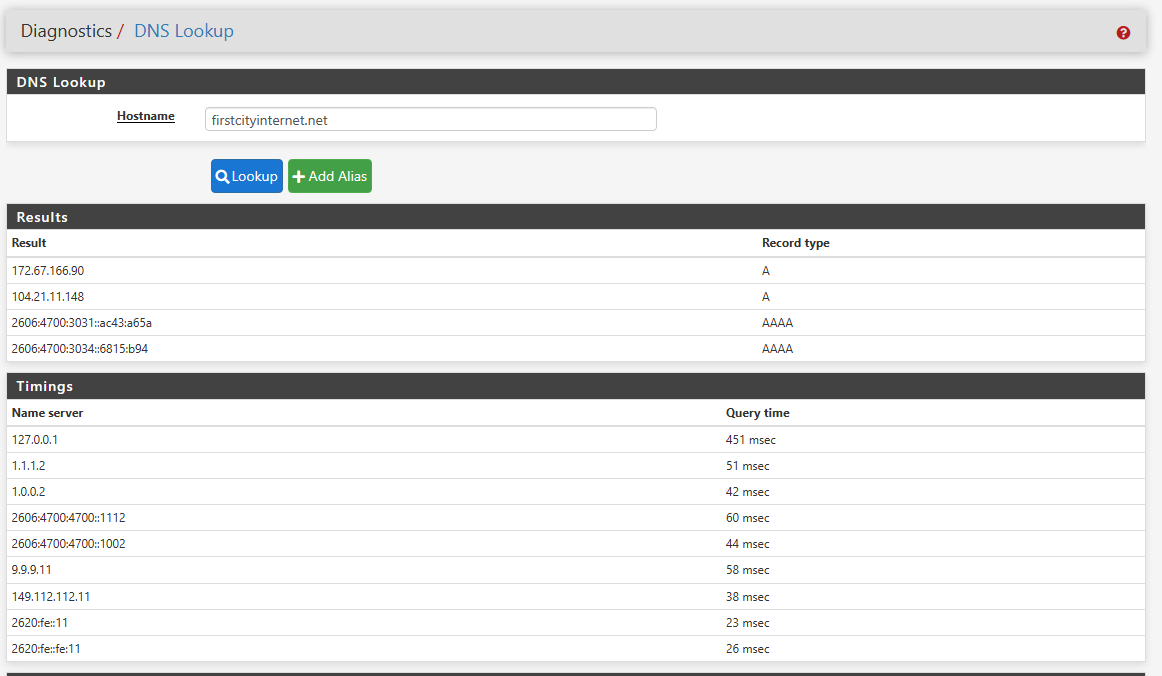
Notice the 127.0.0.1 takes 451 ms to complete a TLS handshake and do the upstream lookup. This is expected as DoT requires the creation of a verified TLS connection then the DNS lookup. If you add up ping time and essentially triple that, you should be at about the right time.
Here is the same query run a few seconds later:
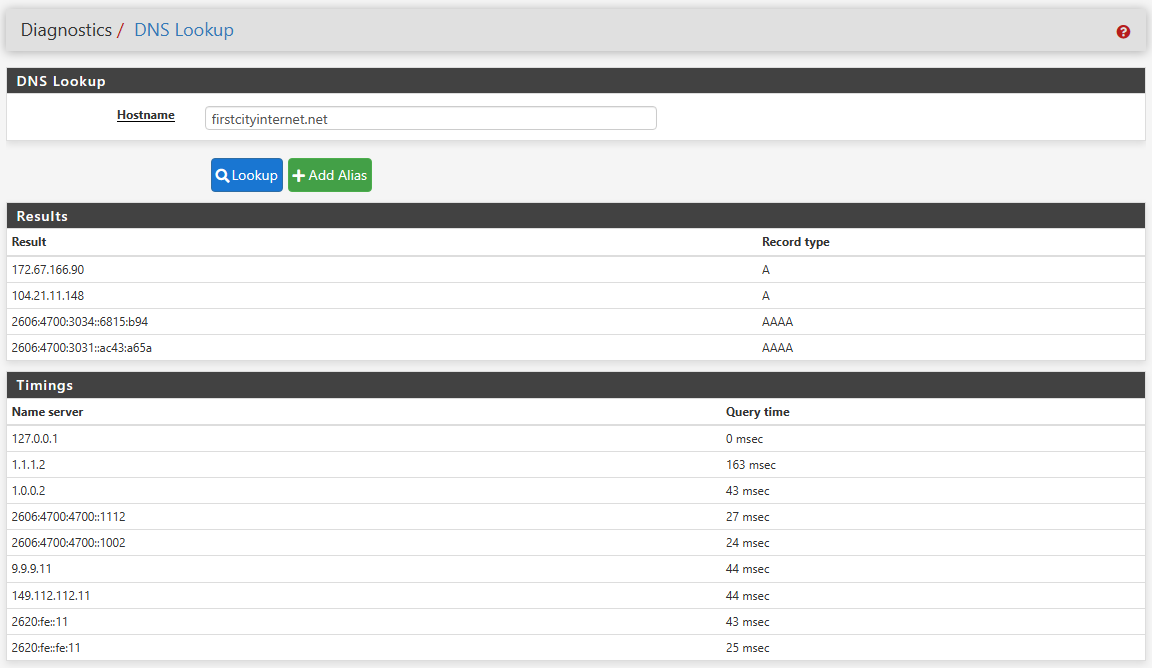
Unbound is answering from its cache as you can see by the 0 ms time on the 127.0.0.1 IP.
Unbound is configured to do preemptive lookups for the most queried data in its cache so once Unbound is up and running, it should answer the most active DNS queries in 0 ms. So far, DNSSEC is working as is pfBlocker.
I still get a few of these errors:
debug: outnettcp got tcp error -1
But so far, the issues I was experiencing earlier have stopped.
Thanks for all the hard work on this!
-
@cmcdonald
So no need to disable ASLR anymore? Is it disabled now by option when compiled? -
Run the elfctl with the 'elf' (full path) on the command line without any other parameters :
See example here : https://forum.netgate.com/topic/178413/major-dns-bug-23-01-with-quad9-on-ssl/139?_=1684213270230 -
 G Gertjan referenced this topic on
G Gertjan referenced this topic on
-
File '/usr/local/sbin/unbound' features: noaslr 'Disable ASLR' is set. noprotmax 'Disable implicit PROT_MAX' is unset. nostackgap 'Disable stack gap' is unset. wxneeded 'Requires W+X mappings' is unset. la48 'amd64: Limit user VA to 48bit' is unset.Yep.
Didn't think of it myself, thanks -
@n0m0fud said in Major DNS Bug 23.01 with Quad9 on SSL:
@robbiett
Updated to the latest release a few minutes ago.
Notice the 127.0.0.1 takes 451 ms to complete a TLS handshake and do the upstream lookup. This is expected as DoT requires the creation of a verified TLS connection then the DNS lookup. If you add up ping time and essentially triple that, you should be at about the right time.Thanks @N0m0fud, very helpful and always good to see real data.
I still find the timings odd though, which is also reflected in your examples. In your first screenshot we can see that your fastest return from Quad9 is:
2620:fe::11 = 23ms
If everything was working within the broad brush of a sys admin we would expect a DNS-over-TLS time delta akin to 3 times this value but we probably wouldn't raise a real-world eyebrow at something around a x4 increase:
2620:fe::11 @ 23ms x 4 = 92ms
The actual time to resolve the query in your example is:
127.0.0.1 = 451ms / 23ms
~20 times slower than a vanilla '53' query or
~5 times slower than expectedI'll dip my toe into what should be going on during the TCP/TLS handshakes only as far to state that the worst case deltas should only be experienced on the first query to the upstream DNS server (Quad9 in this case). TCP 'Fast Open' should ensure that the connections and sessions remain open for multiple queries in order to reduce this establishment overhead (see RFC7858). It is one of the factors going around in my head as I ponder why DoT is so slow on pfSense.
Another thing I ponder is how the pfSense resolver/forwarder is handling multiple upstream DNS name servers. On more lightweight DNS applications (eg dnsmasq) we are used to explicitly setting how multiple servers are used, how they are preferred, use of concurrency and (typically) preferring the fastest response rather than waiting on all the responses. Looking at the data in front of me it is not clear if the pfSense resolver (unbound) is faithfully utilising the fastest response.
I have only been running with the ASLR unset for a few days, so too early for meaningful data; but subjectively it seems much better then it come to the painful DNS-induced 'hangs' or parts of a webpage failing to load. I am less convinced that the timings & responsiveness of DoT is working as expected.
An interesting topic, at least to me!
 ️
️ -
-
@cmcdonald
@stephenw10
In an effort to explain why DoT is so slow on pfSense I have run multiple pcaps to try and understand how the resolver is handling forwarded queries to the servers set in 'General Setup'. The findings are illuminating and I now understand why slow queries are selected, compounded and compounded again by TLS to the point of failure, whilst ignoring faster name servers.On this simple successful test I am using 4 name servers from
dns.quad9.net.Two are ipv4 servers and 2 more are on ipv6:- 9.9.9.9
- 149.112.112.112
- 2620:fe::fe
- 2620:fe::9
From these servers a typical fast response is 7ms but can be as high as 12ms. Clearly if there is a problem with a name server the response can be much slower, up to 300ms or more.
In this single-lookup example I used kia.com (as something unlikely to be used and therefore cached). The sequence:
- pfSense sends a single query to just 1 ipv4 server - 149.112.112.112
- All other servers ignored
- Answered to unbound in 151ms
- pfSense sends a single query to just 1 ipv6 server - 2620:fe::9
- All other servers ignored
- Answered to unbound in 297ms
- DNS answered to client in 448ms
- This is the sum of the 2 queries, 151 + 297ms, as they are asked and answered sequentially
- The ipv6 query does not start until the ipv4 query is fully answered
The forwarded query does not go to all servers, one is simply picked at random. It does not matter how fast or slow a server is; as long as it is deemed valid and returning an answer in under 400ms it can be picked. If a server normally capable of returning an answer in 7ms is struggling, but still under 400ms, it will continue to be used. Multiples of this added latency will then pollute the back-and-forth of the DoT TCP and TLS handshakes, leading to a considerable delay or potentially a failure.
I have no answer as to why the attempt at using a ipv6 server only starts once the ipv4 DoT sequence is completed. Hopefully someone with more unbound insight can answer this element?
For those of us with upstream servers normally operating in the 7 to 12ms range the acceptance of up to 400ms seems ridiculous. The random choice of server used does little for the client but clearly eases the load at the upstream provider. Not having an option to ask all servers and utilise the fastest compounds matters further. Only starting an ipv6 query once ipv4 has completed is another unhealthy delay. Added all together along with the additional handshakes of TCP/TLS we are left with a slow and potentially unreliable DoT capability.
The example pcap snapshot, for those that like data:
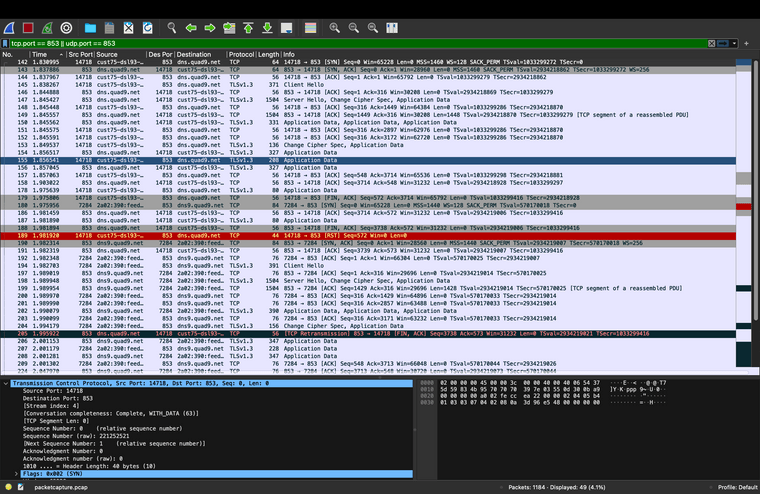
Ref:
https://nlnetlabs.nl/documentation/unbound/info-timeout/️[As an aside, for Quad9 users only, the ipv6 response fqdn is shown as dns9.quad9.net, rather than dns.quad9.net as shown on the Quad9 help pages.]
-
Hmm, well I guess that explains why using IPv6 servers makes it more likely to hit this.

-
@robbiett So if you remove the IPv6 (or v4) servers from the DNS (forwarding) list that cuts the time more or less in half?
-
@steveits said in Major DNS Bug 23.01 with Quad9 on SSL:
@robbiett So if you remove the IPv6 (or v4) servers from the DNS (forwarding) list that cuts the time more or less in half?
Yep, that seems to be the case.
I'd like someone else to check my work though. I think I have a bog-standard pfSense resolver setup (albeit now with the ASLR unset) but until it is peer-reviewed by someone nothing is proven.
️ -
@stephenw10 said in Major DNS Bug 23.01 with Quad9 on SSL:
Hmm, well I guess that explains why using IPv6 servers makes it more likely to hit this.
Indeed, especially if reply latency had been compounded already. Throw in multiple near simultaneous requests, say when rendering a typical 'noisy' webpage and you probably have to be thankful that it works at all.
The man pages for unbound does have some optional parameters that may help but not currently used in the pfSense version - such as:
-
Fast-server-permil: <number>
Specify how many times out of 1000 to pick from the set of fastest servers. 0 turns the feature off. A value of 900 would pick from the fastest servers 90 percent of the time, and would perform normal exploration of random servers for the remaining time. When prefetch is enabled (or serve-expired), such prefetches are not sped up, because there is no one waiting for it, and it presents a good moment to perform server exploration. The fast-server-num option can be used to specify the size of the fastest servers set. The default for fast-server-permil is 0. -
fast-server-num: <number>
Set the number of servers that should be used for fast server selection. Only use the fastest specified number of servers with the fast-server-permil option, that turns this on or off. The default is to use the fastest 3 servers.
I've no direct experience with these options though and I've not found anything that suggests an option to send ipv4 and ipv6 concurrently.
Still learning.
️ -
-
It would be best to split off any non-ASLR performance/tuning discussion to a new thread so this can stay relevant to the central underlying problem here.
Remember: Upvote with the 👍 button for any user/post you find to be helpful, informative, or deserving of recognition!
Need help fast? Netgate Global Support!
Do not Chat/PM for help!
-
@jimp said in Major DNS Bug 23.01 with Quad9 on SSL:
It would be best to split off any non-ASLR performance/tuning discussion to a new thread so this can stay relevant to the central underlying problem here.
It's your house so happy to do whatever but my only caution is that these issues are already intertwined. ASLR became a partial fix but perhaps not the whole story on the DNS issues observed by the OP and others.
️ -
It's hard to know for sure since there are multiple discussions happening in this one thread. The original failures seem to be solved by disabling ASLR. Any slowness/performance issues where it's not acting as fast as you expect are not failures. If disabling ASLR is degrading performance (which is unlikely) that is still a separate discussion because it's still working, not failing to resolve.
Remember: Upvote with the 👍 button for any user/post you find to be helpful, informative, or deserving of recognition!
Need help fast? Netgate Global Support!
Do not Chat/PM for help!
-
It's hard to know Jim, especially until we have some more verified proof.
My observations and issues were as the OP described, with things timing out, failing to load, becoming intermittent and then suddenly ok again, for no apparent reason.
Now that we are deeper in, I am positive that the ASLR change made a significant difference but not an outright fix, especially for those running ipv6. I think we are closer to working out why cases such as mine are still hovering at the 'timing-out', 'intermittent failure' cliff-edge. The raw DNS performance is there but not much needs to go wrong for the pfSense / Unbound combination to go wrong, certainly with the way things are working right now. DNS being slow can in itself cause a failure to resolve.
Latency amplification through TLS, using a slow server over a faster one and only running ipv6 look-ups when ipv4 has been completed don't appear to be ideal, even when ASLR-unset collectively moved us all a bit further back from that cliff-edge.
Again, I'm still learning as this has thrown a few surprises along the way.
️ -
It's hard to know that your situation is even the same or similar to OP's in this case. You can't properly isolate things by changing so many variables at the same time in multiple different environments and chasing all these different potential threads.
There are multiple confirmations that disabling ASLR has corrected the original reported problem behavior for people (between here and the other various reports), even on FreeBSD 13.2 directly where the only real relevant change was that ASLR was turned on by default.
Anything else you're observing is unlikely to be directly relevant to that change. There is likely room for performance improvement in your environment in various ways but it's unlikely to be the same root cause here.
Remember: Upvote with the 👍 button for any user/post you find to be helpful, informative, or deserving of recognition!
Need help fast? Netgate Global Support!
Do not Chat/PM for help!
-
@jimp Ok, I'm back in my box.
️ -
If you want to keep discussing various ways to optimize the resolver, feel free to do so, just in a new thread where others can join in who maybe were not even hitting this original issue but might have other relevant observations.
Remember: Upvote with the 👍 button for any user/post you find to be helpful, informative, or deserving of recognition!
Need help fast? Netgate Global Support!
Do not Chat/PM for help!
-
@jimp That's ok, I'll just drop the subject so no need for another thread.
️ -
@johnpoz
So. Even though I understand and agree with your opinion, how do you explain that many users , including me, are still sticking with a DoT configuration? Aren't you, then, preaching in the desert?
If you could convice me to drop this setting, it would be remarkable. Othewise, your opinion is like the saying: "everybody has an opinion, and it's like an ass****, everybody has one and it stinks". Please enlighten us further?