SG3100 keeps locking up after latest update
-
@stephenw10 I didn't try ctl+t at the console. I took a screenshot for proof of last output and then hard-power-cycled the box. I'll try that next time.
-
Do you have a dual WAN setup? My sg-3100 started locking up with no log messages yesterday, less than a day after setting up dual -wan. Two out of 3 times we had trouble on the primary WAN in the first 24 hrs of dual WAN, it slowly stopped routing traffic over a couple of minutes (some traffic would pass, the sg-3100 interface and ssh were unresponsive until it stopped altogether) and reboots.
-
@netplumbers No, i don't have dual WAN setup. I have 1 WAN and use 2 of the LAN ports (one just for management and the other for all vlan traffic). I also have ntopng and snort package installed. snort wasn't installed when the problem started so on 22 Aug I removed ntopng and continue monitoring to see if i continue to get the random lockup without any logs.
-
@stephenw10 It's locked up now. ctrl-t doesn't do anything. still no logs in console
-
Hmm, so reviewing: you're seeing this in every version since 23.01? And on multiple devices? But running the config? And nothing logged at any time?
-
@stephenw10 Yes, on 2 devices (SG3100 and power supplies) and it's only happening when employees are in the office. And logs prior to the event are all normal and no logs are output to the console during the failure.
To try and make isolating if another device is affecting this issue easier, we are going to change the network to something that might be more appropriate anyway. We are going to turn off DHCP and only allow devices on the network by pair (static IP and mac address). Right now we don't have a concept of "trusted" devices as it's a relaxed office. The problem is the traffic logs before the lockup don't seem useful because there are so many devices and I don't know what abnormal traffic is when everyone can bring personal devices and add them to the network. After forcing all devices to be registered, we can start monitoring traffic for specific users.
I don't have any other ideas for monitoring. We eliminated the ground-loop possibility, buying new hardware doesn't seem appropriate considering we already swapped hardware and I manage another SG3100 at a different location that doesn't have this issue.
-
Would it be a security problem if I uploaded pfSense logs for the 2min up to the lockup time?
-
You can upload them here if you don't want them to be public: https://nc.netgate.com/nextcloud/index.php/s/yELBD5g5qwjNban
-
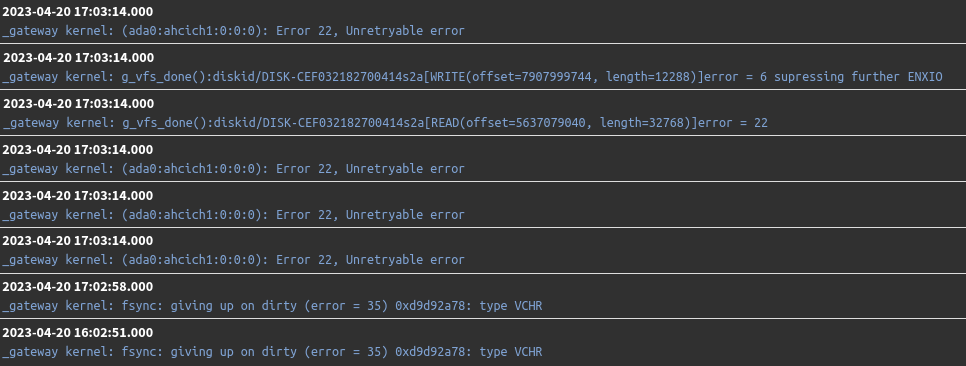
@stephenw10 I uploaded them there. It's unfiltered logs (1min 10sec) up to the system lock up: 2023-09-06 09:16:50.000 Until 2023-09-06 09:18:00.000
-
Those are all firewall logs except:
2023-09-06T09:17:00.000-04:00 pfSense.tstdomain pfSense.tstdomain /usr/sbin/cron[13050] (root) CMD (/usr/sbin/newsyslog) 2023-09-06T09:17:00.000-04:00 pfSense.tstdomain pfSense.tstdomain /usr/sbin/cron[12708] (root) CMD (/usr/local/pkg/servicewatchdog_cron.php)What do you have enabled in the Service Watchdog? That can cause problems, it should only be used for testing.
Are those the only things in the system log?
Steve
-
@stephenw10 That service was added by George Phillips when we paid for Snort integration. After he added Snort, snort kept crashing. He added the service watchdog (sometime between 16-20 June 2023) to make sure it restarted. Our lockups started back in April so I didn't think this was related. Also by the time we paid to have Snort added, there was only 1 other lockup so there was no trend yet. Otherwise i would have cancelled that project. We ran almost 1 month before our next lockup after that project was finished. Here are the only packages currently running on our box:
openvpn-client-export (added by me for our VPN users)
Status_Traffic_Totals (added by me for pfSense GUI traffic totals)
Service_Watchdog (added by George for snort)
snort (added by George for snort)
sudo (added by George for snort)Those are the only things the system sent to our syslog server. I can add a larger range if it would be more helpful. Or i can download logs direclty from pfSense but i'm not 100% exactly what to download or if that must be done via ssh.
-
I just downoaded logs from Diagnostics > Command Prompt > Download > /var/log/system.log
I can upload that. -
@stephenw10 i uploaded them to the last link
-
Mmm, so effectively nothing shown:
<38>1 2023-09-06T08:45:00.077941-04:00 pfSense.tstdomain sshguard 96081 - - Exiting on signal. <38>1 2023-09-06T08:45:00.115084-04:00 pfSense.tstdomain sshguard 67726 - - Now monitoring attacks. <43>1 2023-09-06T10:41:32.702804-04:00 pfSense.tstdomain syslogd - - - sendto: Network is unreachable <6>1 2023-09-06T10:41:32.703510-04:00 pfSense.tstdomain syslogd - - - kernel boot file is /boot/kernel/kernel <43>1 2023-09-06T10:41:32.703592-04:00 pfSense.tstdomain syslogd - - - sendto: Network is unreachable <2>1 2023-09-06T10:41:32.703873-04:00 pfSense.tstdomain kernel - - - ---<<BOOT>>---You manually power cycled it at 10:41?
Otherwise the only thing that really jumps out are some Snort warnings:
snort 28423 - - S5: Session exceeded configured max bytes to queue 1048576 using 1048890 bytes (client queue)Those could probably be prevented with some tuning but they don't look to actually be causing a problem.
Steve
-
@stephenw10 Yes, manual power cycle was at 10:41
The device connected to snort log 28423 is not necessarily a trusted device because i don't know what user it belongs to. Once we start registering static IP and mac for all devices I'll have a profile to connect to each device to make it easier for me to monitor things like that. -
@tuser11 said in SG3100 keeps locking up after latest update:
That service was added by George Phillips when we paid for Snort integration. After he added Snort, snort kept crashing. He added the service watchdog (sometime between 16-20 June 2023) to make sure it restarted.
Service Watchdog should NEVER be used with either Snort or Suricata. It does not understand how those two IDS/IPS packages work internally, and thus Service Watchdog will needlessly submit multiple service restart commands for the IDS/IPS even when the IDS/IPS is already in the middle of restarting.
The correct approach would be to figure out why Snort was failing and address that issue. Service Watchdog is not the correct approach.
-
@bmeeks i don't have enough knowledge to know when service watchdog should be deployed, I agree with "The correct approach would be to figure out why Snort was failing and address that issue".
My time is split between software design and development, software security, network security and many other things IT. I know how to deploy Snort (from docs and google) and i've done it in a home lab. Yet we paid for someone whos time is dedicated to network security (netgate team) in the hopes of having a more solid deployment. The more disciplines I cover, the easier it is for me to make mistakes. After I pointed out the problem to the assigned tech and he choose to deploy service watchdog instead of finding the root of the problem, it was too late for us. Bill was paid and I have to try again to find someone that prefers addressing the root problem.
The next move for us will be to remove the package (or do a fresh install and import config without it) if we confirm it is causing problems. Right now we're just trying to figure out what is causing the lockups. They started before snort was added.
-
I'm even entertaining the idea that the brand new SG-3100 box might have had a defective power supply in it. The first box that was in production for years had a bad internal disk. I replaced the disk, confirmed it was working and swapped that box with a new SG-3100 (that was purchased years ago as a cold spare) and then put both the old SG-3100 and old power supply in a box on the shelf. Later i might disconnect the new power supply and connect the old one but it seems extreme and possibly a waste of time. It's kinda frustrating because it takes about 1-3 weeks before another lockup.
-
Mmm, I would say it's at least statistically unlikely to be a PSU issue. We really don't see many issues with them.
-
@stephenw10 It froze again yesterday morning with relatively low traffic. Still nothing in console or any console ctrl, no errors in syslog. This time i had a script running to send additional system stats to remote syslog.
CPU Temperature: 76 | Load Average: 0.13, 0.20, 0.16 | Memory Usage: 20.00% | MBUF Usage: 1234/1296/2530/10035 | State Table Size: 1215Here is what we've done:
- Swapped SG-3100 unit and power supply after resolving the hard drive issue on the old SG-3100. Re-confirmed power supply was swapped by looking at asset id written on power supply matches asset id on SG-3100
- Eliminated possibility of ground loop by confirming this system doesn't have ground difference between connected building, and re-confirming the electrical architecture related to the network hasn't changed in the 7 years we've been using pfSense (2 years via ESXi, 5 years with SG-3100), our issues started in April 2023
- Doesn't appear to be firmware related considering i'm managing another SG-3100 at a different location with the same firmware and no problems
- I left console connected so I could see output during failure, no output, not even with ctrl+t
- Doesn't appear to be load or heat issue. Normal/Average temperature and loads reported 13 seconds before lockup: CPU Temperature: 76 | Load Average: 0.13, 0.20, 0.16 | Memory Usage: 20.00% | MBUF Usage: 1234/1296/2530/10035 | State Table Size: 1215. We've had much higher loads and temps as high as 83C without issues.
- Removed non-essential packages (only leaving snort)
- No errors in /var/log/system.log
- I "think" we've eliminated the likelihood of the cause being a surge coming from upstream 4 port ISP modem. 2 Netgate boxes are connected to it side by side (SG-3100 for main office with static WAN IP and a SG-1100 for separate facilities with dynamic WAN IP). The SG-1100 hasn't been affected and hasn't had a lockup since it was installed in April. I'm thinking it was a coincidence this was installed the day after the first unexplained SG-3100 lockup.
I'm not sure what else to try or what I might be missing. My assumptions are:
- If the cause is traffic (good, bad, malicious, etc) related from LAN or WAN, no matter how low level, an error would propagate to /var/log/system.log.
- If the cause is heat related, the temp would not rise from normal, past warning, into fatal in under 15 seconds in a room where all other temperatures remain normal. That's why my load checks only run every 15 seconds.
- If the cause is power related, it's not likely to follow a new power supply that was never used. Especially when it's plugged into an APC UPS.
- If the cause is a Ethernet cable gone bad, we would also likely have traffic problems before total failure.
Are my assumptions wrong? Do any ideas jump out as logical next steps?