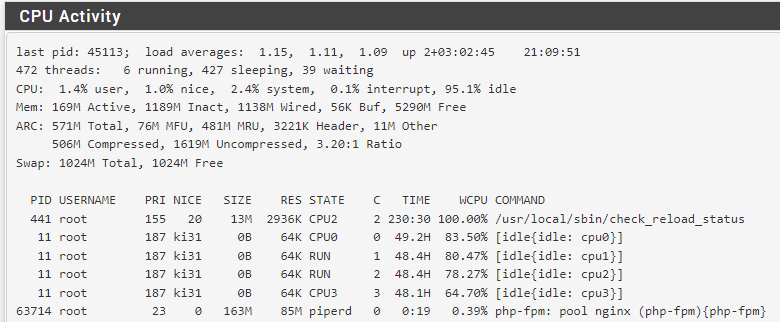
100% /usr/local/sbin/check_reload_status after gateway down
-
@stephenw10 5G modem took around 1 minute to bootup and getting an IP address.
-
And pfSense took a further 4 mins to pull a dhcp lease?
What was logged in that time? In the dhcp and/or system log?
-
@stephenw10 Unfortunately did not check that. I did now use a physical port for that connection and will see if the error still appears. Otherwise it's an issue with VLAN WAN interfaces as it seems.
-
I've yet to see this here on any system. If anyone has a way to replicate this please let us know so we can dig into it.
-
I have check_reload_status at 100% too. It must be related to OpenVPN for me when the interface is removed from my gateway routing group.
-
Only removing it from the group prevents it? The interface is still assigned?
-
I'm seeing "check_reload_status" persistently using 50-99% of CPU for over a month now.
Netgate 3100,
23.05-RELEASE (arm)
built on Mon May 22 15:04:22 UTC 2023
FreeBSD 14.0-CURRENTlast pid: 12641; load averages: 1.26, 1.25, 1.19 up 93+21:02:37 12:16:05 73 processes: 2 running, 63 sleeping, 8 zombie CPU: 2.5% user, 14.9% nice, 36.7% system, 0.2% interrupt, 45.7% idle Mem: 88M Active, 1413M Inact, 255M Laundry, 168M Wired, 58M Buf, 74M Free Displays to show (currently infinite): PID USERNAME THR PRI NICE SIZE RES STATE C TIME WCPU COMMAND 439 root 1 155 20 5100K 1960K CPU1 1 782.7H 98.29% check_reload_status 73655 root 2 20 0 12M 5736K select 0 489:13 4.22% openvpn 61330 squid 1 20 0 558M 525M kqread 0 599:50 0.40% squid 37787 root 1 20 0 6704K 2904K CPU0 0 0:02 0.14% top 12641 root 1 29 0 4340K 1668K nanslp 0 0:00 0.13% sleep 62192 root 1 29 0 4988K 1924K wait 1 0:40 0.06% sh 24342 root 1 20 0 5480K 2332K bpf 1 71:28 0.05% filterlog 64048 root 1 20 0 5264K 2128K select 0 56:54 0.03% syslogd 54611 nobody 1 20 0 8528K 3460K select 1 86:17 0.03% dnsmasq 29638 root 1 20 0 14M 4936K select 0 26:23 0.02% mpd5 6186 root 1 20 0 19M 12M bpf 0 8:18 0.02% bandwidthd 6452 root 1 20 0 12M 5664K bpf 0 8:34 0.02% bandwidthd 6236 root 1 20 0 21M 15M bpf 0 8:09 0.02% bandwidthd 3705 root 1 20 0 16M 10M bpf 0 7:56 0.02% bandwidthd 3659 root 1 20 0 19M 12M bpf 0 8:01 0.02% bandwidthd 3703 root 1 20 0 21M 15M bpf 1 7:51 0.02% bandwidthd 6281 root 1 20 0 16M 10M bpf 0 8:13 0.01% bandwidthd 60680 adamw 1 20 0 12M 7112K select 0 0:00 0.01% sshd 3837 root 1 20 0 12M 5664K bpf 0 8:15 0.01% bandwidthd 87030 root 1 20 0 14M 10M select 0 10:52 0.01% bsnmpd 24506 root 5 68 0 7700K 2200K uwait 1 2:52 0.01% dpinger 13204 squid 1 20 0 10M 5368K select 1 0:05 0.01% pinger 24832 root 5 68 0 5508K 2156K uwait 0 3:16 0.01% dpinger 61947 root 1 20 0 11M 3968K select 1 8:23 0.01% ntpd 398 root 1 20 0 92M 17M kqread 0 4:05 0.00% php-fpm 1904 root 1 20 0 10M 5304K kqread 0 1:00 0.00% lighttpd_ls 78947 root 1 20 0 5544K 2192K bpf 0 2:39 0.00% choparp 16566 root 2 20 0 12M 5332K select 1 51:55 0.00% openvpn 66894 root 1 68 20 5184K 1996K wait 1 12:57 0.00% sh 61385 squid 1 20 0 7128K 2580K piperd 1 3:46 0.00% unlinkd 3420 root 1 20 0 5032K 1848K nanslp 0 1:39 0.00% cron 79339 root 1 20 0 12M 4736K select 0 0:51 0.00% sshd 15682 root 1 68 0 128M 34M accept 1 0:45 0.00% php-fpm 23 root 1 20 0 127M 35M accept 1 0:4498124 senphp-fpm 67340 root 1 68 0 127M 35M accept 1 0:39 0.00% php-fpm 32610 root 1 36 0 129M 35M accept 1 0:29 0.00% php-fpm 17232 root 1 68 0 126M 33M accept 1 0:27 0.00% php-fpm 52591 root 3 20 0 9960K 2388K usem 1 0:18 0.00% filterdns 69767 root 1 20 0 21M 6548K kqread 1 0:11 0.00% nginx 64797 root 1 20 0 4480K 1528K nanslp 0 0:04 0.00% minicron 763 root 1 20 0 6296K 2368K select 1 0:04 0.00% devd 66615 root 1 31 0 4476K 1524K nanslp 1 0:03 0.00% minicron 70082 root 1 20 0 22M 6724K kqread 1 0:02 0.00% nginx 66007 root 1 20 0 4504K 1532K nanslp 0 0:00 0.00% minicron 60088 root 1 20 0 12M 6848K select 0 0:00 0.00% sshd 34483 adamw 1 20 0 10M 6388K select 0 0:00 0.00% sudo 60799 adamw 1 20 0 6704K 3320K pause 1 0:00 0.00% tcsh 72912 root 2 20 0 5448K 2160K piperd 0 0:00 0.00% sshg-blocker 37069 root 1 20 0 5792K 2792K wait 1 0:00 0.00% sh 72456 root 1 26 0 5196K 2084K wait 1 0:00 0.00% sh 61087 squid 1 20 0 41M 8444K wait 0 0:00 0.00% squid 66474 root 1 20 0 4480K 1528K nanslp 0 0:00 0.00% minicron 36993 root 1 21 0 5148K 2332K wait 0 0:00 0.00% su 72856 root 1 20 0 11M 4148K piperd 0 0:00 0.00% sshg-parser 23365 root 1 68 0 4536K 1564K ttyin 0 0:00 0.00% getty 72826 root 1 20 0 4504K 1772K piperd 1 0:00 0.00% cat 73384 root 1 34 0 5148K 2068K piperd 1 0:00 0.00% sh 8116 root 1 68 20 4340K 1668K nanslp 1 0:00 0.00% sleep 69622 root 1 31 0 20M 4952K pause 1 0:00 0.00% nginx 65086 root 1 68 0 4456K 1520K wait 0 0:00 0.00% minicron 64593 root 1 68 0 4456K 1520K wait 1 0:00 0.00% minicron 66112 root 1 68 0 4456K 1520K wait 1 0:00 0.00% minicron 441 root 1 68 20 5048K 1860K kqread 0 0:00 0.00% check_reload_status 65747 root 1 68 0 4456K 1520K wait 1 0:00 0.00% minicron 73096 root 1 26 0 5196K 2080K wait 0 0:00 0.00% shPlease advise if you would like to see anything else before I reboot the firewall tomorrow.
-
If you kill that process does it respawn?
Is there any reason you're not running 23.05.1?
-
I had to use "kill -9" to terminate it.
Waited for 5 mins and didn't see it respawning.
Being onsite I decided to do a full reboot anyway.Regarding pfSense versions.
I have 3 x Netgate 3100 appliances. 2 live and one spare. One of the live ones is located in a distant datacenter so upgrading it remotely is too risky.
Typically I upgrade all 3 firewalls only about once per year when I have other reasons to travel to the dc. I import config to the spare one and just physically swap them around followed by some testing. If anything goes wrong then I just swap them back. -
BTW: after a reboot I was able to ssh to the fw but couldn't elevate to root as my user any more: "xxx is not in the sudoers file".
I think I checked everything (sudo installed, member of admins, sudo config) and couldn't see why. Sudo worked fine just before the reboot with no changes made.
Luckily my web GUI access still worked so I added my user explicitly under /pkg_edit.php?xml=sudo.xml which allowed me to root in shell.
-
Hmm, that was after upgrading? Or has it worked since then and just stopped now?
I'm not aware of any issues with sudoers in 23.05(.1). -
What I did last time (about 3 months ago):
-
installed a vanilla 22.01 image from USB (offline),
-
went online,
-
upgraded to 23.05 (2 stages if I remember correctly),
-
restored config.xml (previously exported from 22.01).
Once the FW booted up everything was working (including sudo) and I haven't restarted it until today.
-
-
Hmm, odd. Your user was in the admins group and that group was enabled in sudo for the command you were trying to run?
-
I don't know for sure how sudoers looked like before (unable to read) but this is how it looks like after 2 users have been explicitly added from web GUI:
cat /usr/local/etc/sudoers
root ALL=(root) ALL
admin ALL=(root) ALL
%admins ALL=(root) ALL
myuser ALL=(root) ALL
someotheradminuser ALL=(root) ALLid myuser
uid=2000(myuser) gid=65534(nobody) groups=65534(nobody),1999(admins)
-
I experienced this when I briefly turned off the DSL modem connected to pfSense WAN. When the gateway came back up, /usr/local/sbin/check_reload_status was consuming 100%. I killed that pid but believe it respawns and remained at 100%. I resorted to rebooting.
I am on 2.7CE and don't recall seeing this happening before on the rare occassions I've powered off the modem. -
I have the same issue on CE 2.7.0-RELEASE. I installed WireGuard and FRR Packages a couple of days ago (running 2 wireguard VPNs with OSPF), after which it started. Possibly process check_reload_status is using 100% after interface flap, but am not 100% sure. Shutting and no shutting an interface did not reproduce the problem. Manually restarting services in the UI did not work, as well as restarting the WebConfigurator. After using kill -9 I managed to end the process without rebooting. I am aware WireGuard is still under development, but maybe a fix can be found.
-
So you were not using OpenVPN when this started? And after killing it it didn't return?
-
@stephenw10 No, I restarted ovpn service, and nothing changed. Next time this happens I will a stop the ovpn service for a couple of minutes to see if the behavior changes.
-
This just happened to me on CE 2.7.0 on the backup CARP node. Have OpenVPN and Wireguard both. OpenVPN was stopped (due to being the backup node). Stopped Wireguard, no change.
kill -9the process and it came back but at 0% usage. Rebooted anyway to make sure the node is not in a weird state in case I need it.Edit: looks like CARP was flapping between master and backup for a minute right before this happened. Will dig into that.
-
Mmm, check the logs when that happened for anything unusual. Flapping interfaces could cause it to queue a number of events. Perhaps hit some race condition....