23.09 Unbound killed failing to reclaim memory
-
I've been running 23.09 in production for 24+ hours after reducing the unbound Message Cache Size to 4mb (default) from 512mb, and the Incoming and Outgoing buffers to 10 (default) from 50. I have not seen the 'killed failing to reclaim memory" error since and the routers have had a very stable run so far.
This experience is consistent on both my A and B Netgate 1100 boxes. I ran the B box for about 18 hours without incident, then swapped in the A box and restored the configuration of the B box to the A box so they're the same except for the Hostname. Service_watchdog is installed but set up to watch no services.
So it appears the error in my case is probably related to advanced memory parameters of unbound. Even though my 1100s have sufficient memory, setting up unbound to use more seems to stimulate a latent defect that did not surface in 23.05.1.
Thanks again for your thoughtful comments and help.
-
@Mission-Ghost said in 23.09 Unbound killed failing to reclaim memory:
unbound Message Cache Size to 4mb (default) from 512mb,
Isn't that half the system memory > Memory: 1GB DDR4 ?
-
Yes that does seem large for a 1G device. Yet presumably it was running like that in 23.05.1 so some other change has caused that to now become too large.
Unfortunately there's no way we can test every combination of custom values like that. So whilst we ran many upgrade tests on the 1100 none of them would have included that.
Anyway I'm glad you found what looks like the cause here.
-
@stephenw10 In retrospect it does seem a bit high. But even so it didn't use up all the memory on the box. Memory usage was at about 80%, and, well, why waste it?

Memory usage had gone down some with 23.09 and the old parameters, but with these parameters reset to defaults, it's stable at around 60%.
The error message about being killed for not releasing memory is still interesting. The box wasn't short of memory when these happened. Are there process quotas for memory usage?
-
There are for some things, like individual php processes for example. I suspect you might have hit that somehow since I'm not aware of a limit for Unbound directly.
-
Version 2.7.0-RELEASE (amd64)
built on Wed Jun 28 03:53:34 UTC 2023
FreeBSD 14.0-CURRENTThe system is on the latest version.
Version information updated at Mon Nov 20 10:38:18 MST 2023
CPU Type Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz
Current: 1204 MHz, Max: 2700 MHz
4 CPUs: 1 package(s) x 2 core(s) x 2 hardware threads
AES-NI CPU Crypto: Yes (active)
QAT Crypto: No
Hardware crypto AES-CBC,AES-CCM,AES-GCM,AES-ICM,AES-XTS
Kernel PTI Enabled
MDS Mitigation VERW -
That's not the latest pfSense version. But yes there is a known issue with Suricata. There should be an update for that shortly.
-
Might not be related but there is a newer version of unbound up now for 23.09 (
1.18.0_1) which fixes a bug where unbound could get stuck, which may manifest itself in different ways.See https://redmine.pfsense.org/issues/14980 for details there.
On 23.09 you can pull in the new version with
pkg-static update; pkg-static upgrade -y unboundand then after that make sure you save/apply in the DNS Resolver settings (or reboot) to make sure the new daemon is running. -
@jimp thank you very much for following up. I'll go get this update and apply.
Seemed to go in ok:
Updating pfSense-core repository catalogue... Fetching meta.conf: pfSense-core repository is up to date. Updating pfSense repository catalogue... Fetching meta.conf: pfSense repository is up to date. All repositories are up to date. Updating pfSense-core repository catalogue... Fetching meta.conf: pfSense-core repository is up to date. Updating pfSense repository catalogue... Fetching meta.conf: pfSense repository is up to date. All repositories are up to date. The following 1 package(s) will be affected (of 0 checked): Installed packages to be UPGRADED: unbound: 1.18.0 -> 1.18.0_1 [pfSense] Number of packages to be upgraded: 1 1 MiB to be downloaded. [1/1] Fetching unbound-1.18.0_1.pkg: .......... done Checking integrity... done (0 conflicting) [1/1] Upgrading unbound from 1.18.0 to 1.18.0_1... ===> Creating groups. Using existing group 'unbound'. ===> Creating users Using existing user 'unbound'. [1/1] Extracting unbound-1.18.0_1: .......... done ------System/General log: Nov 20 18:43:08 check_reload_status 342 Syncing firewall Nov 20 18:43:07 php-fpm 51606 /services_unbound.php: Configuration Change: admin@192.168.10.110 (Local Database): DNS Resolver configured. Nov 20 18:41:46 pkg-static 51529 unbound upgraded: 1.18.0 -> 1.18.0_1 -
Let us know if that helps.
-
[Edit 1: Ooma box started flashing again for no apparent reason, but the 'not found' error discussed below isn't in the DHCP server logs this time. Confounding problem so far. I have tested the drop cable and cable run from the switch--both ok. I've cold-booted the Ooma box multiple times.]
[Edit 2: Could the ISC DHCP binary being different in 23.09 than in 23.05.1 be the issue, as in these discussions: https://www.reddit.com/r/PFSENSE/comments/17xi9ut/isc_dhcp_server_in_2309/ and https://redmine.pfsense.org/issues/15011 ? If so, the switch to Kea may resolve this. I'll report back.]
@stephenw10 unbound seems to continue to work ok with the patch, although it already was working ok after I lowered the advanced settings for buffers and memory.
Oddly, since the update my Ooma Telo2 box has periodically stopped responding to pings and the status light goes from steady blue (everything's fine) to flashing blue-red (not ok). During these episodes the telephone service still works but it's concerning that at some point it won't work. Prior to 23.09 it has worked fine for many months.
I can find no clear cause-effect of the pfSense update to this Ooma box problem beyond the coincidence. I've made no changes to the DHCP configurations nor firewall rules before, during or after the update.
I'm having a bit of a difficult time diagnosing this issue too. Ooma box has no logs, and the pfSense logs are all clear except DHCP server (still ISC DHCP) which while reissuing the address periodically seems to be saying it's "not found" occasionally at times that correspond with the loss of ping. The Ooma box is 192.168.30.103 (on VLAN 30):
Nov 21 10:33:08 dhcpd 89986 DHCPACK on 192.168.30.103 to 00:18:61:59:56:75 via mvneta0.30 Nov 21 10:33:08 dhcpd 89986 DHCPREQUEST for 192.168.30.103 from 00:18:61:59:56:75 via mvneta0.30 Nov 21 09:33:07 dhcpd 89986 DHCPACK on 192.168.30.103 to 00:18:61:59:56:75 via mvneta0.30 Nov 21 09:33:07 dhcpd 89986 DHCPREQUEST for 192.168.30.103 from 00:18:61:59:56:75 via mvneta0.30 Nov 21 09:33:07 dhcpd 89986 DHCPRELEASE of 192.168.30.103 from 00:18:61:59:56:75 via mvneta0.30 (not found) Nov 21 09:22:24 dhcpd 89986 DHCPACK on 192.168.30.103 to 00:18:61:59:56:75 via mvneta0.30 Nov 21 09:22:24 dhcpd 89986 DHCPREQUEST for 192.168.30.103 from 00:18:61:59:56:75 via mvneta0.30 Nov 21 09:20:31 dhcpd 89986 DHCPACK on 192.168.30.103 to 00:18:61:59:56:75 via mvneta0.30 Nov 21 09:20:31 dhcpd 89986 DHCPREQUEST for 192.168.30.103 from 00:18:61:59:56:75 via mvneta0.30I am not observing this "not found" error from a sampling of other devices on the .30 or other VLANs on the network. Just this one.
-
The timing on those updates is interesting. Exactly 1h between the last updates looks expected. Where it eventually shows 'not found' looks like failed lease renewals. It would be interesting to see what the interval was before that initial failure. Did it go past the lease time for some reason maybe.
-
@stephenw10 I switched to the Kea DHCP server at at 11:54:53, and I have not had the Ooma box fail to answer pings or function properly since:
Nov 21 15:43:53 kea-dhcp4 41486 INFO [kea-dhcp4.leases.0x7f70e8815f00] DHCP4_LEASE_ALLOC [hwtype=1 00:18:61:59:56:75], cid=[01:00:18:61:59:56:75], tid=0xa77b51c9: lease 192.168.30.103 has been allocated for 7200 seconds Nov 21 14:43:53 kea-dhcp4 41486 INFO [kea-dhcp4.leases.0x7f70e8818200] DHCP4_LEASE_ALLOC [hwtype=1 00:18:61:59:56:75], cid=[01:00:18:61:59:56:75], tid=0xa77b51c9: lease 192.168.30.103 has been allocated for 7200 seconds Nov 21 13:43:53 kea-dhcp4 41486 INFO [kea-dhcp4.leases.0x7f70e8817400] DHCP4_LEASE_ALLOC [hwtype=1 00:18:61:59:56:75], cid=[01:00:18:61:59:56:75], tid=0xa77b51c9: lease 192.168.30.103 has been allocated for 7200 seconds Nov 21 12:43:53 kea-dhcp4 41486 INFO [kea-dhcp4.leases.0x7f70e8816600] DHCP4_LEASE_ALLOC [hwtype=1 00:18:61:59:56:75], cid=[01:00:18:61:59:56:75], tid=0xa77b51c9: lease 192.168.30.103 has been allocated for 7200 seconds Nov 21 11:43:52 dhcpd 89986 DHCPACK on 192.168.30.103 to 00:18:61:59:56:75 via mvneta0.30 Nov 21 11:43:52 dhcpd 89986 DHCPREQUEST for 192.168.30.103 from 00:18:61:59:56:75 via mvneta0.30 Nov 21 11:43:52 dhcpd 89986 DHCPRELEASE of 192.168.30.103 from 00:18:61:59:56:75 via mvneta0.30 (not found) Nov 21 11:33:08 dhcpd 89986 DHCPACK on 192.168.30.103 to 00:18:61:59:56:75 via mvneta0.30 Nov 21 11:33:08 dhcpd 89986 DHCPREQUEST for 192.168.30.103 from 00:18:61:59:56:75 via mvneta0.30 Nov 21 11:31:15 dhcpd 89986 DHCPACK on 192.168.30.103 to 00:18:61:59:56:75 via mvneta0.30 Nov 21 11:31:15 dhcpd 89986 DHCPREQUEST for 192.168.30.103 from 00:18:61:59:56:75 via mvneta0.30 Nov 21 11:29:22 dhcpd 89986 DHCPACK on 192.168.30.103 to 00:18:61:59:56:75 via mvneta0.30 Nov 21 11:29:22 dhcpd 89986 DHCPREQUEST for 192.168.30.103 from 00:18:61:59:56:75 via mvneta0.30 Nov 21 11:25:38 dhcpd 89986 DHCPACK on 192.168.30.103 to 00:18:61:59:56:75 via mvneta0.30 Nov 21 11:25:38 dhcpd 89986 DHCPREQUEST for 192.168.30.103 from 00:18:61:59:56:75 via mvneta0.30This certainly supports the theory there is something wrong with the 23.09 ISC DHCP server. This is a weird regression. I wouldn't think the ISC binary would have been fiddled with during the 23.09 development given it's being retired. Someone in the previously quoted forum threads replaced their 23.09 ISC binary with a 23.05.1 binary and their problem stopped.
Did something go wrong in the version control system for this module in the 23.09 release?
Something I don't quite get looking at this log why only the Ooma box is logging a lease reallocation every hour. The .30 network alone has half a dozen devices on it, never mind the other five VLANs.
So far the Kea server has been working fine, so I imagine I'll stay with it unless something malfunctions.
-
@Mission-Ghost said in 23.09 Unbound killed failing to reclaim memory:
something wrong with the 23.09 ISC DHCP server
It's noted in the redmine but the file did change even though the version number didn't. Per the redmine reporters it seems the updated program responds on a random port. Some devices don't particularly care, apparently, and others ignore the response, I suppose until happens to use the correct port, or a port to which it pays attention.
Overall some devices retry quite a bit at each renewal, and per reports others try and try but eventually lose their lease.
Also annoyingly, I found some IoT type devices renew whenever they heck they want to (e.g. 10 minutes not 1 day) so the log spam can be high in some cases.
For me at home, I don't need the things Kea DHCP doesn't have so switched to Kea.
This is all in forum thread https://forum.netgate.com/topic/184104/dhcp-weirdness-after-23-09-upgrade/ :)
-
@SteveITS indeed, this seems key: "This seems to imply the intent of RFC2131 was that a fixed source port be used, at least for relays. The new behavior doesn't comply with this."
Seems like a code review didn't happen or wasn't as detail-oriented as it should have been before someone allowed this new code to be committed. And in a module that's deprecated anyway? Why bother, and then breaking it now, at the end of life?
-
J jrey referenced this topic on
-
@jimp said in 23.09 Unbound killed failing to reclaim memory:
Might not be related but there is a newer version of unbound up now for 23.09 (
1.18.0_1) which fixes a bug where unbound could get stuck, which may manifest itself in different ways.See https://redmine.pfsense.org/issues/14980 for details there.
On 23.09 you can pull in the new version with
pkg-static update; pkg-static upgrade -y unboundand then after that make sure you save/apply in the DNS Resolver settings (or reboot) to make sure the new daemon is running.Quick follow up question on this: I upgraded the Unbound package from
1.18.0to1.18.0_1, but the Unbound logs andunbound-control -hstill show the version as1.18.0, even after rebooting. Is that expected or should I be seeing1.18.0_1instead? Thanks in advance. -
@stephenw10 so now netstat has started being killed off for not reclaiming memory:
Nov 26 17:39:38 kernel pid 44612 (netstat), jid 0, uid 0, was killed: failed to reclaim memory Nov 25 11:29:01 kernel pid 92717 (netstat), jid 0, uid 0, was killed: failed to reclaim memory Nov 24 18:18:39 kernel pid 81047 (netstat), jid 0, uid 0, was killed: failed to reclaim memory Nov 22 12:48:27 kernel pid 11499 (netstat), jid 0, uid 0, was killed: failed to reclaim memoryI can’t tell where or how it’s run or what parameters affect it. Can you please point me in the right direction to troubleshoot?
Thanks!
-
@tman222 said in 23.09 Unbound killed failing to reclaim memory:
Quick follow up question on this: I upgraded the Unbound package from 1.18.0 to 1.18.0_1, but the Unbound logs and unbound-control -h still show the version as 1.18.0, even after rebooting. Is that expected or should I be seeing 1.18.0_1 instead? Thanks in advance.
The
_1bit is from the FreeBSD package, it's not part of the Unbound version string. The_1version of the package added a patch to address an Unbound bug but it did not increment the Unbound version. -
J jrey referenced this topic on
-
@jimp The Unbound crash happened again today. The Unbound crash has not happened in months, particularly since reducing memory size parameters. It's been so long, in fact, that I removed service watchdog a week or two ago, thinking the issue was resolved. So much for that.
Here's various symptoms:
- The only relevant error message I found in the System>General log is:
Nov 24 10:57:21 kernel pid 54097 (unbound), jid 0, uid 59, was killed: a thread waited too long to allocate a pageNote this error is different than those in the past where Unbound was killed failing to reclaim memory. End result is the same: dead Unbound and dead production on my network (without service_watchdog, which I have now restored to service).
-
I haven't found any relevant messages in the Unbound logs.
-
The Status>Monitoring>System>Memory shows a puzzling zeroing of all parameters at about the same time as the Unbound crash:
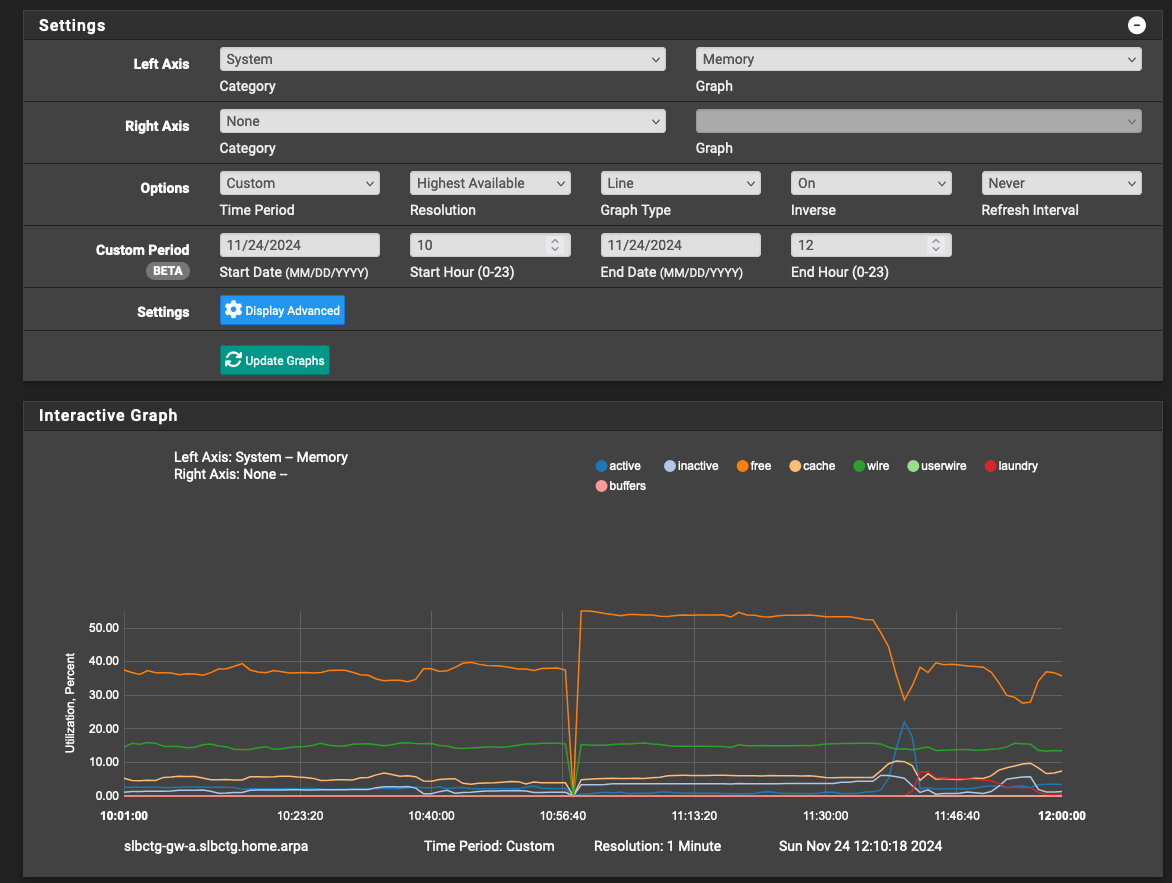
So, while I've been admonished in this forum to not use service_watchdog, I can't maintain production uptime without while these Unbound discrepancies live on.
If there's something more I can do to assist Netgate in figuring this out, please let me know. I'll be happy to do whatever I'm able.
Thanks!