Another Netgate with storage failure, 6 in total so far
-
@dennypage
Thank you for the explanation!
Regards,
fireodo -
Something that might help is increase the default async txg timer, defaults to 5 seconds. I am about to go sleep, but on a couple of pfsense VMs I tested the impact of increasing it and it made a significant dents on writes logged by the hypervisor for the VM. This has no impact on sync writes.
Or maybe if a UPS is detected via one of the the UPS packages, it could reconfigure it or something.When I wake up if I remember I will post the exact tunable to change and the exact savings on writes I got.
-
@chrcoluk said in Another Netgate with storage failure, 6 in total so far:
Something that might help is increase the default async txg timer, defaults to 5 seconds.
See here: Tuning
-
@fireodo The txg timeout is the one.
I did also configure 'zfs set sync=disabled' to test and found that made absolutely no difference, all the writes or the vast majority must be async.
The txg timeout also doesnt need to go as high as 120, boosting it to 30 is enough.
So keep zfs set sync as default, and boost 'vfs.zfs.txg.timeout' to 30 is my recommendation to netgate developers.
-
@dennypage said in Another Netgate with storage failure, 6 in total so far:
FWIW, I carelessly burned through the eMMC on my own 6100. After installing a NVMe drive, I spent some time diving into disk writes to discover where the writes originated from. On my system, it turned out that over 90% of the writes resulted from package operations. Yes, over 90% and this is what killed my eMMC. Ultimately, I felt that I was responsible for my own decisions in this regard. You may feel differently.
Don't kick yourself. I have two 6100's that couldn't be more vanilla, zero packages from day one and they only push what I would consider to be light traffic for these units. Over 100% used up...

Probably the default logging rules and ZFS writes did mine in, but I'm not nearly qualified enough to stand by that statement. One is just over 3 years and the other is 2 years. The newer one has some general system logs that look suspect (missing file errors) but again I don't really know what I'm looking at. I will install SSD's in both and hopefully move on.
It would have been nice if there was a doc outlining optimal setup for a base model, or some sort of warning about the limitation of the eMMC. No doubt I would of have ponied up the extra 100 per unit to get the max version. It's a shame, these units just chug along, I would even dare to say bulletproof. That opinion took a little hit after this experience...
-
@Jare-0 said in Another Netgate with storage failure, 6 in total so far:
FWIW, I carelessly burned through the eMMC on my own 6100.
I'm all for people taking responsibility for their actions when they should probably know their actions will have adverse consequences and they've been warned or could reasonably figure out what they're about to do is damaging.
I'm happy with my Netgate products and pfSense. But it's not reasonable to expect people to know better or be responsible for their actions when an ordinary and customary use for a computing device (including documented packages) can run it to failure in barely enough time for the warranty to run out.
Louis Rossmann would love this.
-
@Jare-0 said in Another Netgate with storage failure, 6 in total so far:
I have two 6100's that couldn't be more vanilla, zero packages from day one and they only push what I would consider to be light traffic for these units. Over 100% used up...
Nearly all of our devices are the same - very basic and only have the Zabbix package for monitoring. We are seeing eMMC wearout between 2-3 years in service.
Probably the default logging rules and ZFS writes did mine in, but I'm not nearly qualified enough to stand by that statement. One is just over 3 years and the other is 2 years. The newer one has some general system logs that look suspect (missing file errors) but again I don't really know what I'm looking at.
Our data shows that devices using ZFS have an average write-rate that's 2.5 to 6.5 times more than devices using UFS, so that appears to be what is wearing out the eMMC. This is further supported by the fact that our old 3100 and 7100 devices using UFS that are 6 to 7 years old are still under 50% wear, while our newer 4100 and 6100 with ZFS are the ones that are at 100%+ in under 3 years.
It would have been nice if there was a doc outlining optimal setup for a base model, or some sort of warning about the limitation of the eMMC.
Word is that changes are in the works so we can look forward to that.
No doubt I would of have ponied up the extra 100 per unit to get the max version.
I think many others feel the same way since the cost of an SSD is a fraction of cost of failure. An SSD essentially required one way or the other, so there is no downside to getting the Max version.
I suggest that it makes more sense to consider the "Max" to be the regular version, and the Base is really more of a "Lite" since it cannot perform most pfSense functions without significant compromises.
-
@Mission-Ghost said in Another Netgate with storage failure, 6 in total so far:
@Jare-0 said in Another Netgate with storage failure, 6 in total so far:
FWIW, I carelessly burned through the eMMC on my own 6100.
I'm all for people taking responsibility for their actions when they should probably know their actions will have adverse consequences and they've been warned or could reasonably figure out what they're about to do is damaging.
I'm happy with my Netgate products and pfSense. But it's not reasonable to expect people to know better or be responsible for their actions when an ordinary and customary use for a computing device (including documented packages) can run it to failure in barely enough time for the warranty to run out.
I fully agree.
-
Apparently I migrated to USB thumb drive just in time. I rebooted my Netgate 1100 the other day and occasionally it does not recognize the USB thumb drive it is now installed to. Tried to boot from the eMMC and it no longer can.
-
Hello!
Is the 4200 BASE with only eMMC still for sale?
I only see the 4200 MAX (with nvme ssd) available.
Also, I just bought a 4200 MAX a week or so ago for $649. The MAX is now $599???John
-
@jared-silva Did you clean the eMMC as per these steps when you installed the USB drive. If not, then your 1100 might still have been booting from the eMMC which would explain why it doesn't recognize the USB drive.
-
@andrew_cb Thanks, I was aware of wiping the eMMC but I was not aware of this page. I avoided doing it should things go wrong in the migration. I ran the following commands to set the boot order for USB and then eMMC when migrating:
Marvell>> setenv bootcmd 'run usbboot; run emmcboot;' Marvell>> saveenv Saving Environment to SPI Flash... SF: Detected mx25u3235f with page size 256 Bytes, erase size 64 KiB, total 4 MiB Erasing SPI flash...Writing to SPI flash...done OK Marvell>> run usbbootThere are times when the USB is not detected (due to timing?) so it will then try to boot from the eMMC.
Current situation is:
zpool status pool: pfSense state: ONLINE status: Some supported and requested features are not enabled on the pool. The pool can still be used, but some features are unavailable. action: Enable all features using 'zpool upgrade'. Once this is done, the pool may no longer be accessible by software that does not support the features. See zpool-features(7) for details. config: NAME STATE READ WRITE CKSUM pfSense ONLINE 0 0 0 da0p3 ONLINE 0 0 0 geom -t Geom Class Provider flash/spi0 DISK flash/spi0 flash/spi0 DEV mmcsd0 DISK mmcsd0 mmcsd0 DEV mmcsd0 PART mmcsd0s1 mmcsd0s1 DEV mmcsd0s1 LABEL msdosfs/EFISYS msdosfs/EFISYS DEV mmcsd0 PART mmcsd0s2 mmcsd0s2 DEV mmcsd0s2 LABEL msdosfs/DTBFAT0 msdosfs/DTBFAT0 DEV mmcsd0 PART mmcsd0s3 mmcsd0s3 DEV mmcsd0s3 PART mmcsd0s3a mmcsd0s3a DEV mmcsd0boot0 DISK mmcsd0boot0 mmcsd0boot0 DEV mmcsd0boot1 DISK mmcsd0boot1 mmcsd0boot1 DEV da0 DISK da0 da0 DEV da0 PART da0p1 da0p1 DEV da0p1 LABEL gpt/efiboot1 gpt/efiboot1 DEV da0 PART da0p2 da0p2 DEV da0 PART da0p3 da0p3 DEV zfs::vdev ZFS::VDEVI am confused as to what commands to run from Wipe Metadata, as the examples don't seem to match the Using the Geom Tree section. gmirror status has no output.
I take it I should run:
zpool labelclear -f /dev/mmcsd0 (example has /dev/mmcsd0p4) gpart destroy -F mmcsd0 dd if=/dev/zero of=/dev/mmcsd0 bs=1M count=1 status=progress?
Thanks!
-
@jared-silva said in Another Netgate with storage failure, 6 in total so far:
zpool labelclear -f /dev/mmcsd0 (example has /dev/mmcsd0p4)
You don't have an
mmcsd0p4device.gpart listwould show you if you need to run that and on what. You may not have ZFS there. -
@jared-silva
The output of zpool status looks like you have 2 ZFS pools: pfSense (likely the original installation on the eMMC) and da0p3 (likely on the USB):
NAME STATE READ WRITE CKSUM pfSense ONLINE 0 0 0 (likely the original installation on the eMMC) da0p3 ONLINE 0 0 0 (likely on the USB):Disconnect your USB drive and try running these commands:
## Stop a legacy style GEOM mirror and clear its metadata from all disks gmirror destroy -f pfSense ## Clear the partition metadata gpart destroy -F mmcsd0 ## Wipe the first 1MB of the disk dd if=/dev/zero of=/dev/mmcsd0 bs=1M count=1 status=progressYou could try wiping the entire eMMC, but it might fail if your eMMC is too degraded:
## Wipe the entire disk dd if=/dev/zero of=/dev/mmcsd0 bs=1M status=progress -
Oops, missed the zpool status output. Yup I would try:
zpool labelclear -f /dev/mmcsd0s3 -
gpart list Geom name: mmcsd0 ... Geom name: da0 ... Geom name: mmcsd0s3 modified: false state: OK fwheads: 255 fwsectors: 63 last: 14732926 first: 0 entries: 8 scheme: BSD Providers: 1. Name: mmcsd0s3a Mediasize: 7543250432 (7.0G) Sectorsize: 512 Stripesize: 512 Stripeoffset: 0 Mode: r0w0e0 rawtype: 27 length: 7543250432 offset: 8192 type: freebsd-zfs index: 1 end: 14732926 start: 16 Consumers: 1. Name: mmcsd0s3 Mediasize: 7543258624 (7.0G) Sectorsize: 512 Stripesize: 512 Stripeoffset: 0 Mode: r0w0e0Did not bother with gmirror destroy because gmirror status was empty.
zpool labelclear -f /dev/mmcsd0s3 failed to clear label for /dev/mmcsd0s3 zpool labelclear -f /dev/mmcsd0s3a failed to clear label for /dev/mmcsd0s3azpool status -P pool: pfSense state: ONLINE status: Some supported and requested features are not enabled on the pool. The pool can still be used, but some features are unavailable. action: Enable all features using 'zpool upgrade'. Once this is done, the pool may no longer be accessible by software that does not support the features. See zpool-features(7) for details. config: NAME STATE READ WRITE CKSUM pfSense ONLINE 0 0 0 /dev/da0p3 ONLINE 0 0 0 errors: No known data errorszpool list -v NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT pfSense 119G 1.29G 118G - - 0% 1% 1.00x ONLINE - da0p3 119G 1.29G 118G - - 0% 1.08% - ONLINEgpart destroy -F mmcsd0 mmcsd0 destroyedgpart list now only shows Geom name: da0, nothing for the MMC.
dd if=/dev/zero of=/dev/mmcsd0 bs=1M count=1 status=progress 1+0 records in 1+0 records out 1048576 bytes transferred in 0.048666 secs (21546430 bytes/sec)For science...
dd if=/dev/zero of=/dev/mmcsd0 bs=1M status=progress dd: /dev/mmcsd0: short write on character deviceed 299.006s, 26 MB/s dd: /dev/mmcsd0: end of device 7458+0 records in 7457+1 records out 7820083200 bytes transferred in 299.528401 secs (26107986 bytes/sec)Thanks for the help!
-
Well that should certainly have wiped it. Does it boot from USB as expected?
-
@stephenw10 Have not rebooted yet. I'll be back if there's a problem ;)
-
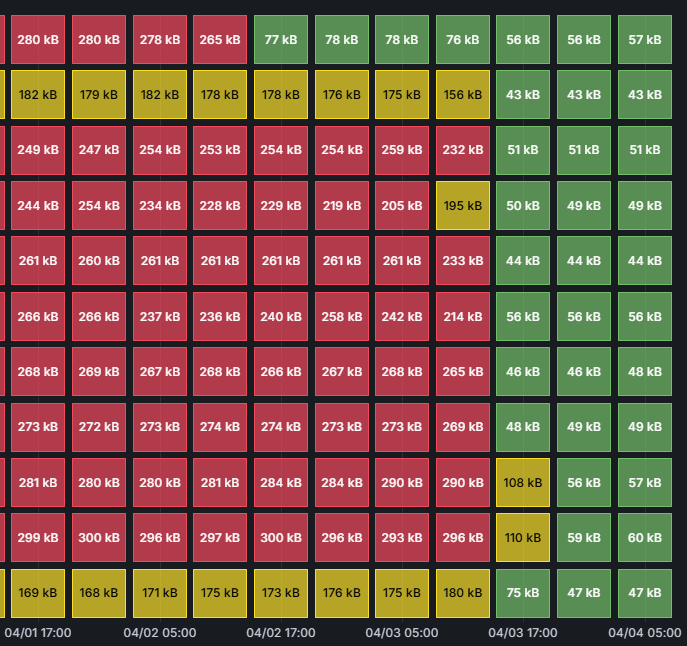
Background
Across a fleet of 45 devices, the ones using UFS have a steady 40-50KB/s write rate, while all devices using ZFS have a steady 250-280KB/s write rate.
I have been trying without success to find a package or GUI option that would reduce the data write rate.
I can definitively state that there is nothing in our configuration that is causing the high, continuous write rate.
The only difference between low and high write rates is UFS vs ZFS.Changing the ZFS Sync Interval
On ZFS firewalls with high wear, I ran the command
sysctl vfs.zfs.txg.timeout=60 (the default value is 5)I have not yet experiment with values other than 60 or any other ZFS settings.
Results of the ZFS Change
The result was an immediate 73-82% decrease in write rate across all devices.

-80.8% -77% -79.2% -78.7% -83.9% -76.2% -82.1% -82.4% -82.3% -80% -72.8Write rates dropped from 230-280KB/s to 44-60KB/s
Calculating the eMMC lifecycle
Kingston (and all others?) calculate eMMC TBW as follows:
The formula for determining Total Bytes Written, or TBW, is straightforward:
(Device Capacity * Endurance Factor) / WAF = TBWOften, WAF is between 4 and 8, but it depends on the host system write behavior. For example, large sequential writes produce a lower WAF, while random writes of small data blocks produce a higher WAF. This kind of behavior can often lead to early failure of storage devices.
For example, a 4GB eMMC with an endurance factor of 3000 and a WAF of 8 will equate to:
(4GB * 3000) / 8 = 1.5TB before EoLThe Total Bytes Written of the eMMC device is 1.5TB. Therefore, we can write 1.5TB of data over the lifecycle of the product before reaching its EoL state.
To calculate for a 16GB chip with a generously low WAF of 2 gives us:
(16GB * 3000) / 2 = 24 TB before EoLCalculating expected storage lifespans 16GB eMMC with a WAF of 2 and average write rates from 50 to 250KB/s gives us the following:
250KB/s = 596 days (1.6 years) 150KB/s= 994 days (2.7 years) 100KB/s = 1491 days (4.1 years) 50KB/s = 2982 days (8.2 years)To summarize:
- The default ZFS settings used by pfSense cause a significantly higher write rate compared to UFS, even for light loads with minimal logging.
- It is true that all flash wears, but the combination of 8/16GB eMMC and default ZFS settings in pfSense results in a high probability of dying in under 2 years, and practically guarantees failure within 3 years.
- In some cases, when eMMC fails, it will prevent the Netgate hardware from even powering on, rendering the device completely dead. Physically de-soldering the eMMC chip is the only solution when this happens.
- Changing vfs.zfs.txg.timeout to 60 reduces the average write rate back down to UFS levels, although with unknown risks.
- As of this posting, pfSense has no default monitoring of eMMC health or storage write rate, leading to sudden, unexpected failures of Netgate devices.
- Avoiding packages will not solve the problem, nor will overzealously disabling logging.
- As of this posting, there are no warnings in the product pages, documentation, or GUI regarding issues with small storage devices or eMMC storage.
- Changing the ZFS sync interval is sometimes recommended as a solution for reducing storage writes, but it is not documented and the there is no information on the risks of data loss or corruption that can result from changing the default setting.
- Many device failures are incorrectly attributed to "user error" when the real issue is a critical flaw in the default ZFS settings used by pfSense.
- The true scope of this issue is unknown since many failures occur after the 1-year warranty and so they are either not accepted as RMA claims by Netgate or are not reported at all. Due to this, Netgate's RMA stats for eMMC failure will be significantly lower than the true number.
Request for Additional Data
Please share if you have any data on your average disk write rate or the effects of changing the vfs.zfs.txg.timeout.
I am interested to see how my data compares with a larger sample size. -
@jared-silva I am glad that myself and @stephenw10 were able to help!