Another Netgate with storage failure, 6 in total so far
-
Has this been be added as a redmine so it can be merged ? This fix should be used to mitigate the high risk of failure.
-
 B bmeeks referenced this topic on
B bmeeks referenced this topic on
-
@fireodo Awesome, thanks for sharing!
Your GBW/Day at the default timeout of 5 is similar to what I am seeing. Most devices are doing about 23GBW/Day (nearly 1GB per hour).
-
Introduction
While further researching ZFS settings, I found this enlightening 2016 FreeBSD article Tuning ZFS. The introduction states:
The most important tuning you can perform for a database is the dataset block size—through the recordsize property. The ZFS recordsize for any file that might be overwritten needs to match the block size used by the application.
Tuning the block size also avoids write amplification. Write amplification happens when changing a small amount of data requires writing a large amount of data. Suppose you must change 8 KB in the middle of a 128 KB block. ZFS must read the 128 KB, modify 8 KB somewhere in it, calculate a new checksum, and write the new 128 KB block. ZFS is a copy-on-write filesystem, so it would wind up writing a whole new 128 KB block just to change that 8 KB. You don’t want that.
Now multiply this by the number of writes your database makes. Write amplification eviscerates performance.
It can also affect the life of SSDs and other flash-based storage that can handle a limited volume of writes over their lifetimes
...
ZFS metadata can also affect databases. When a database is rapidly changing, writing out two or three copies of the metadata for each change can take up a significant number of the available IOPS of the backing storage. Normally, the quantity of metadata is relatively small compared to the default 128 KB record size. Databases work better with small record sizes, though. Keeping three copies of the metadata can cause as much disk activity, or more, than writing actual data to the pool.
Newer versions of OpenZFS also contain a redundant_metadata property, which defaults to all.(emphasis added)
Interpretation
My understanding of this is that even if only a few entries are added to a log file, ZFS will write an entire 128 KB block to disk. At the default interval of 5 seconds, there are likely dozens of 128 KB blocks that need to be written, even though each block might only contain a few KB of new data. For example, if a log file is written every 1 second, then in the span of 5 seconds there could be 640 KB (5 x 128 KB blocks) of data to write, just for that single log file.
When the interval is increased, the pending writes can be more efficiently coalesced into fewer, fuller 128 KB blocks, which results in less data needing to be written overall.
Block Size
The block size can be checked with the command :
zfs get recordsizeWhich produces an output similar to the following:
NAME PROPERTY VALUE SOURCE pfSense recordsize 128K default pfSense/ROOT recordsize 128K default pfSense/ROOT/auto-default-20221229181755 recordsize 128K default pfSense/ROOT/auto-default-20221229181755/cf recordsize 128K default pfSense/ROOT/auto-default-20221229181755/var_cache_pkg recordsize 128K default pfSense/ROOT/auto-default-20221229181755/var_db_pkg recordsize 128K default pfSense/ROOT/auto-default-20230729144653 recordsize 128K default pfSense/ROOT/auto-default-20230729144653/cf recordsize 128K default pfSense/ROOT/auto-default-20230729144653/var_cache_pkg recordsize 128K default pfSense/ROOT/auto-default-20230729144653/var_db_pkg recordsize 128K default pfSense/ROOT/auto-default-20230729145845 recordsize 128K default pfSense/ROOT/auto-default-20230729145845/cf recordsize 128K default pfSense/ROOT/auto-default-20230729145845/var_cache_pkg recordsize 128K default pfSense/ROOT/auto-default-20230729145845/var_db_pkg recordsize 128K default pfSense/ROOT/auto-default-20240531032905 recordsize 128K default pfSense/ROOT/auto-default-20240531032905/cf recordsize 128K default pfSense/ROOT/auto-default-20240531032905/var_cache_pkg recordsize 128K default pfSense/ROOT/auto-default-20240531032905/var_db_pkg recordsize 128K default pfSense/ROOT/default recordsize 128K default pfSense/ROOT/default@2022-12-29-18:17:55-0 recordsize - - pfSense/ROOT/default@2023-07-29-14:46:53-0 recordsize - - pfSense/ROOT/default@2023-07-29-14:58:45-0 recordsize - - pfSense/ROOT/default@2024-05-31-03:29:05-0 recordsize - - pfSense/ROOT/default@2024-05-31-03:36:02-0 recordsize - - pfSense/ROOT/default/cf recordsize 128K default pfSense/ROOT/default/cf@2022-12-29-18:17:55-0 recordsize - - pfSense/ROOT/default/cf@2023-07-29-14:46:53-0 recordsize - - pfSense/ROOT/default/cf@2023-07-29-14:58:45-0 recordsize - - pfSense/ROOT/default/cf@2024-05-31-03:29:05-0 recordsize - - pfSense/ROOT/default/cf@2024-05-31-03:36:02-0 recordsize - - pfSense/ROOT/default/var_cache_pkg recordsize 128K default pfSense/ROOT/default/var_cache_pkg@2022-12-29-18:17:55-0 recordsize - - pfSense/ROOT/default/var_cache_pkg@2023-07-29-14:46:53-0 recordsize - - pfSense/ROOT/default/var_cache_pkg@2023-07-29-14:58:45-0 recordsize - - pfSense/ROOT/default/var_cache_pkg@2024-05-31-03:29:05-0 recordsize - - pfSense/ROOT/default/var_cache_pkg@2024-05-31-03:36:02-0 recordsize - - pfSense/ROOT/default/var_db_pkg recordsize 128K default pfSense/ROOT/default/var_db_pkg@2022-12-29-18:17:55-0 recordsize - - pfSense/ROOT/default/var_db_pkg@2023-07-29-14:46:53-0 recordsize - - pfSense/ROOT/default/var_db_pkg@2023-07-29-14:58:45-0 recordsize - - pfSense/ROOT/default/var_db_pkg@2024-05-31-03:29:05-0 recordsize - - pfSense/ROOT/default/var_db_pkg@2024-05-31-03:36:02-0 recordsize - - pfSense/ROOT/default_20240531033558 recordsize 128K default pfSense/ROOT/default_20240531033558/cf recordsize 128K default pfSense/ROOT/default_20240531033558/var_cache_pkg recordsize 128K default pfSense/ROOT/default_20240531033558/var_db_pkg recordsize 128K default pfSense/cf recordsize 128K default pfSense/home recordsize 128K default pfSense/reservation recordsize 128K default pfSense/tmp recordsize 128K default pfSense/var recordsize 128K default pfSense/var/cache recordsize 128K default pfSense/var/db recordsize 128K default pfSense/var/log recordsize 128K default pfSense/var/tmp recordsize 128K defaultAs you can see, the recordsize of all mount points is 128 KB.
Redundant Metadata
The redundant_metadata setting can be checked with
zfs get redundant_metadataNAME PROPERTY VALUE SOURCE pfSense redundant_metadata all default pfSense/ROOT redundant_metadata all default pfSense/ROOT/auto-default-20221229181755 redundant_metadata all default pfSense/ROOT/auto-default-20221229181755/cf redundant_metadata all default pfSense/ROOT/auto-default-20221229181755/var_cache_pkg redundant_metadata all default pfSense/ROOT/auto-default-20221229181755/var_db_pkg redundant_metadata all default pfSense/ROOT/auto-default-20230729144653 redundant_metadata all default pfSense/ROOT/auto-default-20230729144653/cf redundant_metadata all default pfSense/ROOT/auto-default-20230729144653/var_cache_pkg redundant_metadata all default pfSense/ROOT/auto-default-20230729144653/var_db_pkg redundant_metadata all default pfSense/ROOT/auto-default-20230729145845 redundant_metadata all default pfSense/ROOT/auto-default-20230729145845/cf redundant_metadata all default pfSense/ROOT/auto-default-20230729145845/var_cache_pkg redundant_metadata all default pfSense/ROOT/auto-default-20230729145845/var_db_pkg redundant_metadata all default pfSense/ROOT/auto-default-20240531032905 redundant_metadata all default pfSense/ROOT/auto-default-20240531032905/cf redundant_metadata all default pfSense/ROOT/auto-default-20240531032905/var_cache_pkg redundant_metadata all default pfSense/ROOT/auto-default-20240531032905/var_db_pkg redundant_metadata all default pfSense/ROOT/default redundant_metadata all default pfSense/ROOT/default@2022-12-29-18:17:55-0 redundant_metadata - - pfSense/ROOT/default@2023-07-29-14:46:53-0 redundant_metadata - - pfSense/ROOT/default@2023-07-29-14:58:45-0 redundant_metadata - - pfSense/ROOT/default@2024-05-31-03:29:05-0 redundant_metadata - - pfSense/ROOT/default@2024-05-31-03:36:02-0 redundant_metadata - - pfSense/ROOT/default/cf redundant_metadata all default pfSense/ROOT/default/cf@2022-12-29-18:17:55-0 redundant_metadata - - pfSense/ROOT/default/cf@2023-07-29-14:46:53-0 redundant_metadata - - pfSense/ROOT/default/cf@2023-07-29-14:58:45-0 redundant_metadata - - pfSense/ROOT/default/cf@2024-05-31-03:29:05-0 redundant_metadata - - pfSense/ROOT/default/cf@2024-05-31-03:36:02-0 redundant_metadata - - pfSense/ROOT/default/var_cache_pkg redundant_metadata all default pfSense/ROOT/default/var_cache_pkg@2022-12-29-18:17:55-0 redundant_metadata - - pfSense/ROOT/default/var_cache_pkg@2023-07-29-14:46:53-0 redundant_metadata - - pfSense/ROOT/default/var_cache_pkg@2023-07-29-14:58:45-0 redundant_metadata - - pfSense/ROOT/default/var_cache_pkg@2024-05-31-03:29:05-0 redundant_metadata - - pfSense/ROOT/default/var_cache_pkg@2024-05-31-03:36:02-0 redundant_metadata - - pfSense/ROOT/default/var_db_pkg redundant_metadata all default pfSense/ROOT/default/var_db_pkg@2022-12-29-18:17:55-0 redundant_metadata - - pfSense/ROOT/default/var_db_pkg@2023-07-29-14:46:53-0 redundant_metadata - - pfSense/ROOT/default/var_db_pkg@2023-07-29-14:58:45-0 redundant_metadata - - pfSense/ROOT/default/var_db_pkg@2024-05-31-03:29:05-0 redundant_metadata - - pfSense/ROOT/default/var_db_pkg@2024-05-31-03:36:02-0 redundant_metadata - - pfSense/ROOT/default_20240531033558 redundant_metadata all default pfSense/ROOT/default_20240531033558/cf redundant_metadata all default pfSense/ROOT/default_20240531033558/var_cache_pkg redundant_metadata all default pfSense/ROOT/default_20240531033558/var_db_pkg redundant_metadata all default pfSense/cf redundant_metadata all default pfSense/home redundant_metadata all default pfSense/reservation redundant_metadata all default pfSense/tmp redundant_metadata all default pfSense/var redundant_metadata all default pfSense/var/cache redundant_metadata all default pfSense/var/db redundant_metadata all default pfSense/var/log redundant_metadata all default pfSense/var/tmp redundant_metadata all defaultConclusion
It did not make sense to me why ZFS would have so much data to flush every 5 seconds when the actual amount of changed data is low.
The 128 KB block size and redundant_metadata setting are the missing links as to why the write activity is so much higher with ZFS.
Further Testing
The effects of changing the recordsize to values smaller than 128 KB and changing redundant_metadata to "most" instead of "all" needs to be tested.
-
It looks like the ZFS block size can be changed with the command
sudo zfs set recordsize=[size] [dataset name]However, this will not change the block size of existing files.
In theory, this should help with log files since a new file is created at rotation. -
@andrew_cb said in Another Netgate with storage failure, 6 in total so far:
For example, if a log file is written every 1 second, then in the span of 5 seconds there could be 640 KB (5 x 128 KB blocks) of data to write, just for that single log file.
Maybe, but it could also be one block if all updates fit into the one block. (there is also compression)
(Edit: 5 updates to one log file, or to 5 log files)Note the amount of metadata changes with recordsize (there are more blocks per file), as do things like write speed.
It stands to reason though most of the writing on pfSense is log files, or periodic file updates like pfBlocker feeds.
-
 K keyser referenced this topic on
K keyser referenced this topic on
-
I was able to do some testing of different zfs_txg_timeout values. I am using Zabbix to call a PHP script every 60 seconds and store the value in an item. Attached to the item is a problem trigger that fires whenever the value changes. The data is visualized using Grafana, with an annotation query that overlays the "problems" (each time the value changes) as vertical red lines. There is a slight delay before Zabbix detects the change, so the red lines do not always align exactly with changes on the graph.
The testing was performed on 3 active firewalls performing basic functions, so they are representative of real-world performance in our environment and likely many others. Notice how the graphs for all 3 firewalls are nearly identical, reinforcing that the underlying OS drives this behavior.
Changing from 5s to 120s results in a 90% reduction in write activity. The change numbers shown on the graph are a bit low because some data from the previous 10s value is included from before changing to 5s at the start of the test period. Interestingly, values of 45 and 90 seem to produce more variation in the write rate compared to other values.

Looking at just the change from 5s to 10s, the average write rate has been reduced by 35%.
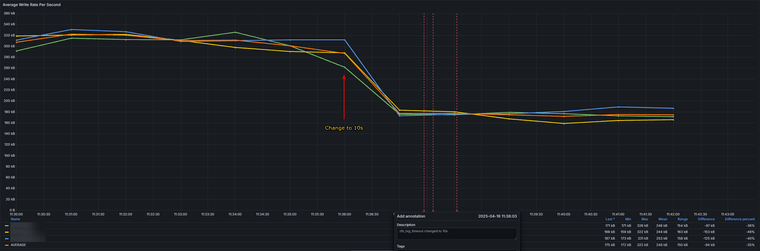
Changing from 10s to 15s gives a further 30% average reduction in write rate.

There are diminishing returns from values above 30.
The gain from 15s to 120s is 32%, specifically, 15s to 30s is 16%, and from 30s to 120s is an additional 16%.Calculating for a 16GB storage device with a TBW of 48 gives us the following:
timeout (s) kb/s change lifespan (days) lifespan (years) 5 309 656 1.8 10 175 -43% 1159 3.2 15 129 -58% 1572 4.3 20 104 -66% 1950 5.3 30 81 -74% 2503 6.9 45 66 -79% 3072 8.4 60 59 -81% 3437 9.4 90 39 -87% 5199 14.2 120 31 -90% 6541 17.9Based on this data, changing the default value of zfs_txg_timeout to 10 or 15 will double the lifespan of devices with eMMC storage without causing too much data loss in the event of an unclean shutdown.
This change, combined with improved eMMC monitoring, would nearly eliminate unexpected eMMC failures due to wearout.
-
Leaving this here for reference: https://openzfs.github.io/openzfs-docs/Performance%20and%20Tuning/Module%20Parameters.html#zfs-txg-timeout
-
@andrew_cb said in Another Netgate with storage failure, 6 in total so far:
Based on this data, changing the default value of zfs_txg_timeout to 10 or 15 will double the lifespan of devices with eMMC storage without causing too much data loss in the event of an unclean shutdown.
This is a great write-up. Thanks
-
P Patch referenced this topic on
-
@fireodo said in Another Netgate with storage failure, 6 in total so far:
Edit 23.04.2025: Today I had a Power failure that exhausted the UPS Battery. The timeout was set at 2400. The pfsense has shudown as set in the apcupsd and after Power has come back the pfsense came up without any issues.
Such a high timout (40 minutes) doesn't make you start to worry about filesystem resiliance/consistency?
I found some interesting remarks on the
vfs.zfs.txg.timeoutparameter in Calomel's FreeBSD Tuning and Optimization guide (CTRL+f'ing for it). -
@tinfoilmatt said in Another Netgate with storage failure, 6 in total so far:
high timout (40 minutes) doesn't make you start to worry about filesystem resiliance/consistency?
I'm experimenting ... I dont know what happends if the Power will suddenly dissapear without clean shutdown ...
-
Is this considered a maintenance/revision item with respects to software development or a regression? I can't understand the amount of debugging by way of brute force that must have taken place with this. YOU ARE AMAZING !!! Thank you for sharing how you fixed this.
-
We had a 6100 die on Sunday. It was installed in May 2023, which means it lasted 1.9 years, so my calculation of 1.8 years was pretty close! I had recently set zfs.txg.timeout to 60 seconds, but it was clearly too little, to late. I have now set all high-wear devices to 3600s and am hoping they will survive a bit longer until we can upgrade or replace them.
Getting B+M key NVMe drives has been a major challenge - the KingSpec NE 2242 is pretty much the only option and it's hard to get in Canada. Combined with the fact that many devices are at remote sites, upgrading all devices to SSDs is taking much longer than desired.
When I look at storage wear by model, nearly all of the 110% devices are 2-3 year old 4100 and 6100. The 6-7 year old 3100 and 7100 are mostly at 50% or less. I suspect that the 3100 being limited to UFS only and the 7100 having 32GB of eMMC and being on ZFS for less than 3 years explain why they are outlasting the 4100 and 6100.
For some good news, we were able to revive a non-booting 4100 by desoldering the eMMC chip using a heatgun. The eMMC had failed and I had got it running from a USB flash drive, but after a few reboots it stopped showing anything on the console and the orange light was pulsing instead of solid. Once the eMMC chip was removed, it boots to the NVMe drive and works great.
@marcosm is working on a patch to reduce write rates while ensuring configuration changes are immediately committed to disk.
-
@andrew_cb
There are some dumb adapters from 2242 to 2230. Looks like 2230 nvme is a common thing, you can buy it almost everywhere.
Of course, there's no certainty that it will work, but if I had enough devices and no better options available, I would give this approach a try. -
I've had no issues with the old Western Digital SN520 NVMe drives in my 4100's. The key to finding the older key B+M key in an NON sata interface (which seems more common) is that SN520 line. Here's my verbatim search which does pretty well at locating them without limiting it to the length or capacity:
"sn520" "nvme" "m.2" "x2"I usually just go for the full length 80mm ones by adding "2280" to the search so I don't have to use any of those adapters which always seem so flimsy.
-
@andrew_cb recordsize is an upper limit, ashift is the lower limit (should be 4k on modern storage devices, which is a value of 12, set on pool creation time and is viewable on the pool variables).
The record will be from one ashift allocation up to record size in multiples of ashift. The bigger the difference between ashift and recordsize, the higher potential for compression gains, as compression can only work on multiples of ashift inside the recordsize.
So if e.g. a write is 7KB, then it will be a 8KB write not 128KB.
The one change should just be boost zfs txg timeout to something like 60-120 seconds as a default.
-
@w0w said in Another Netgate with storage failure, 6 in total so far:
@andrew_cb
There are some dumb adapters from 2242 to 2230. Looks like 2230 nvme is a common thing, you can buy it almost everywhere.
Of course, there's no certainty that it will work, but if I had enough devices and no better options available, I would give this approach a try.I have seen those adapters, but I was hoping to avoid adding yet another component and point of failure to the "fix." However, we may have to, as it would make it much easier to source compatible drives.
-
@arri From what I can tell, the WD SN520 was released in 2018 and is no longer in production. I cannot find any that will ship to Canada. It seems like NVMe drives in B+M key format never really caught on so there are few options available.
We just received 10 of the KingSpec drives so that will allow us to begin replacements on all our 110% wear devices.
-
@chrcoluk I am seeing conflicting information on the relationship of
recordsizeand the amount of data written when only part of the record is modified. From the Tuning ZFS article:Tuning the block size also avoids write amplification. Write amplification happens when changing a small amount of data requires writing a large amount of data. Suppose you must change 8KB in the middle of a 128 KB block. ZFS must read the 128 KB, modify 8 KB somewhere in it, calculate a new checksum, and write the new 128 KB block. ZFS is a copy-on-write filesystem, so it would wind up writing a whole new 128 KB block just to change that 8 KB.
What you are saying makes sense, but if it was working the way you describe, then would you expect to see less of a decrease in write rate from changing zfs.txg.timeout?
-
@andrew_cb I think you need to link to the article, the first line e.g. is incorrect terminology. Record size isnt the block size.
-
I was trying to figure out why the available disk space on a virtualized pfSense instance was significantly smaller than the provisioned size of the virtual disk. I discovered that it had several boot environments that had been automatically created by pfSense upgrades. Each boot environment was 1-2GB. Once I deleted the boot environments, the reported disk size in pfSense matched the provisioned disk size.
This got me thinking, "If the the filesystem is copy-on-write, and the snapshots are from pfSense upgrades which replace many or all of the files, and each boot environment is consuming 1-2GB of space, then there is several GB of storage space that is allocated and not empty."
4GB of boot environments on a 16GB eMMC means that 25% of the blocks are not available for wear leveling, thus all the write activity is occurring in at most 75% of the blocks and will accelerate the eMMC wear. Simply installing packages will also exacerbate the situation by consuming several hundred MB or even a few GB of blocks that are now unavailable for wear leveling.
One of the eMMC chips found on Netgate devices is a
Kingston EMMC16G_TB29. Its datasheet states:The integrated eMMC controller directly manages NAND flash media which relieves the host processor of these tasks, including flash media error control, wear leveling, NAND flash management and performance
optimization.Kingston EMMC16G_TB29 Datasheet
A Kioxia article Understanding Wear Leveling in NAND Flash Memory notes 2 types of wear leveling:
- static: includes usable data blocks whether or not they contain user data
- dynamic: only includes unused (free) data blocks
It also contains an interesting comment:
In a use case when wear leveling is not enabled - when 10% of the flash device’s total capacity is used - only 10% of the total flash blocks in the device would be programmed and the remaining 90% of the total flash blocks would never be programmed. As an example, if after one year the flash blocks that were programmed reach their W/E cycle limit and become unreliable, the flash device would be considered EoL despite the fact that 90% of the flash blocks were never used!
Kioxia - Understanding Wear Leveling in NAND Flash Memory
The Kingston datasheet does not specify whether static or dynamic wear leveling is used. From what I can tell, dynamic wear leveling is more sophisticated and is less commonly used, so my best guess is that the Kingston eMMC is using static wear leveling (only the unused/free blocks).
Combined with my points mentioned above, it seems plausible that there can be "hot spots" of blocks on the eMMC (or any flash storage) that take significantly more P/E cycles and wear out first and cause the eMMC to fail, even when there may be many blocks with low P/E cycles. For example, if most of the sustained 300KB/s write activity is concentrated on 4GB, 8GB, or 12GB of the eMMC instead of the full 16GB, then it makes sense why it dies in such a short period of time - even less than 12 months in some cases.