25.07 unbound - pfblocker - python - syslog
-
@jrey
Yesterday we upgraded three recently installed Netgate 8300-Max firewalls from 24.11 to 25.07. One of the problems we noticed was that our syslogd would die shortly after starting. Last messages in /var/log/system.log were always "syslogd: sendto: Connection refused"A fourth firewall, which was upgraded to 25.07 prior to deployment did not exhibit this problem.
After reading your experiences I went to the syslog config page and found that an old Graylog server was still referred to in the three problem installs. I removed those entries, and syslogd has been running just fine ever since.
So I can confirm that an unreachable target seems to be enough to kill the syslogd process. This is a bug.
-nic -
Hmm, just to be clear is the remote syslog server here in a subnet local to pfSense?
I'm failing to replicate it so far with a missing server. I just get 'host is down' log spam.
-
@stephenw10
No, in this case the remote syslog receiver was remote, on a different subnet. And for completeness, the destination subnet is not a connected network from the firewall perspective.
-nic -
Interesting - by syslog config page you mean system logs settings ?
So I have two syslog servers so there are two IP addresses listed there.
Netgate -> syslog1
Netgate -> syslog2Here is a different observation -
syslog1 shuts itself down and does some automated system maintenance twice a week ( the downtime usually lasts just a few minutes) and it comes back up. (other systems in the network have no issue logging to it before it goes down and/or after it auto restarts.as syslog2 is running throughout -- it never misses a record (including from the netgate)
front the netgate everything that would normally go to both syslogs continues to write to the local files and syslog2 while syslog1 is offline. when it syslog1 is back online the netgate does not resume sending to syslog1.
In my case restarting syslogd alone does not resolve the problem, restarting unbound alone does not resolve the problem
But if I restart syslogd and unbound in that order (from the services page) - it resumesI think that when syslog1 goes down, syslogd and unbound are not playing well together, one of them or in combination are not restarting the connection when it fails and resumes.
because syslog1 maintenance happens in the wee hours of the morning
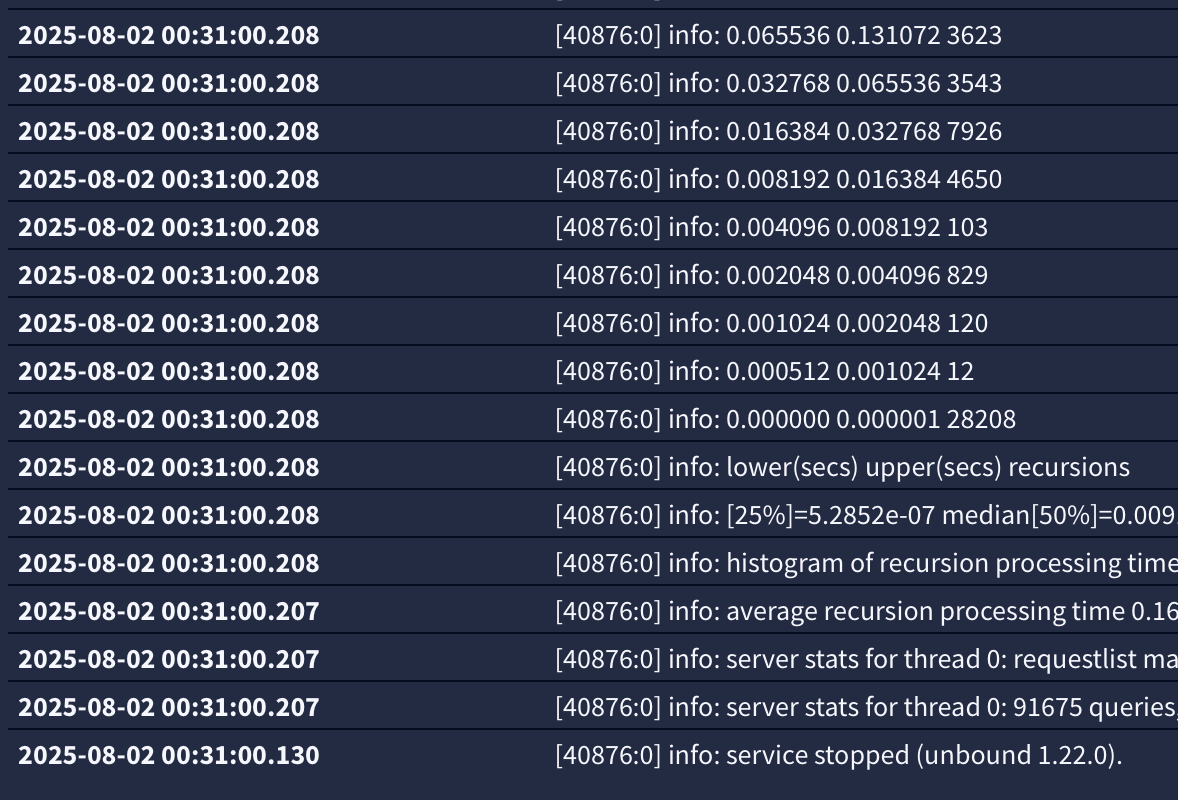
I wrote a little script to monitor the syslog1 going down and then taking the appropriate action when it comes back up (because the syslogd and unbound don't actually stop they are both still running throughout) service watchdog for example won't see a problem.some output from a test run of the script. (192.168.0.35 is my syslog1 server)
++ date + echo 'Mon 11 Aug 2025 08:43:30 EDT: 192.168.0.35 is offline.' Mon 11 Aug 2025 08:43:30 EDT: 192.168.0.35 is offline. + ip_status=1 + sleep 300 + true + ping -c 1 192.168.0.35 + '[' 1 -eq 1 ']' ++ date + echo 'Mon 11 Aug 2025 08:48:30 EDT: 192.168.0.35 is back online. Restarting syslogd and unbound...' Mon 11 Aug 2025 08:48:30 EDT: 192.168.0.35 is back online. Restarting syslogd and unbound...The network and various system are very stable -- 260+ days on 24.11 never failed. 0 issues. Data tells the story. (the change is colour is based on unbound pid) only ever changed as a result of pfblocker restarting unbound when needed (usually every couple of days)
above the graph I have drawn some lines, from left to right
the first 2 I was upgrading the syslog system the small gap represents the reboots of that system (the colour in the graph didn't change so the pid didn't change).
the third small gap, (aug 4) - again no change in pid
the 4 line just after the Aug 6 marker is where I upgraded from 24.11 to 25.07
the horizontal line is where the whole doubling of data thing was happening. Lots of bouncing around trying various things. Within that horizontal the large empty block starting at the "8" in "Aug 8" 1:30am mark is where the first automated syslog1 maintenance happened. No data from 1:30am until I kicked the services in the morning.Corrected the doubling up issue last vertical at the end of the horizontal, which is also just not right fix if you don't want "everything". (but for now the "Everything" setting stops that and the data level returns to "normal" and I've been playing

-
for clarity in my case both of the syslog servers I referenced in my response to @postilion are both in the same subnet
-
Hmm, maybe I misread this then. What circumstances cause syslogd to stop in pfSense?
-
@stephenw10
In our case syslogd would stop shortly after boot. Restarting syslogd, it would stop again a short time later. I don't have exact timings, as I was dealing with other update-related issues at the time, and this was a lower priority.After reading @jrey 's message, however, I went back into the syslog settings panel, removed the graylog server, since it's currently down, and saved. This caused syslogd to start again, and it's now been running smoothly for the past two hours.
Note: This is on three (3) separate 8300-Max units, all installed within the past month, and all updated from 24.11 to 25.07 yesterday (8/10/25).
-nic -
Ah, OK I think I replicated it. Digging....
-
@stephenw10
Generally taking one or the other of the two syslog servers offline, but I don't know the cause yet.appears it is not continuing / reestablishing the connection to the one that went down and came back up
I've also tried having just one syslog server - it is broken in that case too.
I've had the syslogd service actually stop (shows service down) twice since the update, but always in relationship to when one of the syslog servers goes off line
I'm really not sure why at this point (at least for me) just restarting syslogd isn't enough to make it go..
restarting syslogd only doesn't help -- I "Always" have to restart both syslogd and unbound.My script will temporarily work around the not sending, by just restarting them in order (even if they are running, because mostly they are they just stop communicating with the one server even though it is back online). Other systems in the network resume just fine.
Interestingly enough, we know that from time to time, pfblocker will restart unbound, when that happens - there has never been an issue and still isn't. in that case unbound can come and go as it pleases and there is no issue.
But some combination of the syslog server going away temporarily and returning causes syslogd and unbound to stop (but continue to local files and the other syslog server). so both of the process are generally running just in limp mode.
-
Cool, that you can replicate..
Just for a little more clarity
One of my servers is a Graylog, the other is not (Synology repository, that's all it does is collect the same data). the two are not linked in anyway. they are completely different systems.it doesn't matter which one I take of line however the result is the same, when it comes back comms do not resume to that one, but still continue to the other
So don't think we can assume it is specifically related to Graylog
I can run for days, as long as I don't take one of the syslog servers offline (which in the case of 1 server happens twice a week (Monday and Thursday)
Again based on unbound pid -
had been running fine until yesterday morning, then a little bit of colour while I was writing a script and doing some thing things until about noon, then from noonish yesterday until the gap this morning, the orange(ish) on the right is after the script figured out it needed to take action and the green is when pfblocker thought unbound needed a restart because of some change that had been download --- all pretty normal except now having to have the script intervention to restart the syslog/unbound combo
It will likely run clean now until Thrusday, or unless I see something else I want to "try" sometime between now and then unbound will normally be restarted at least 1 based on a pfblocker download/change -- just like this morning I don't expect it will cause any issues. other than a noted change in pid for unbound.
-
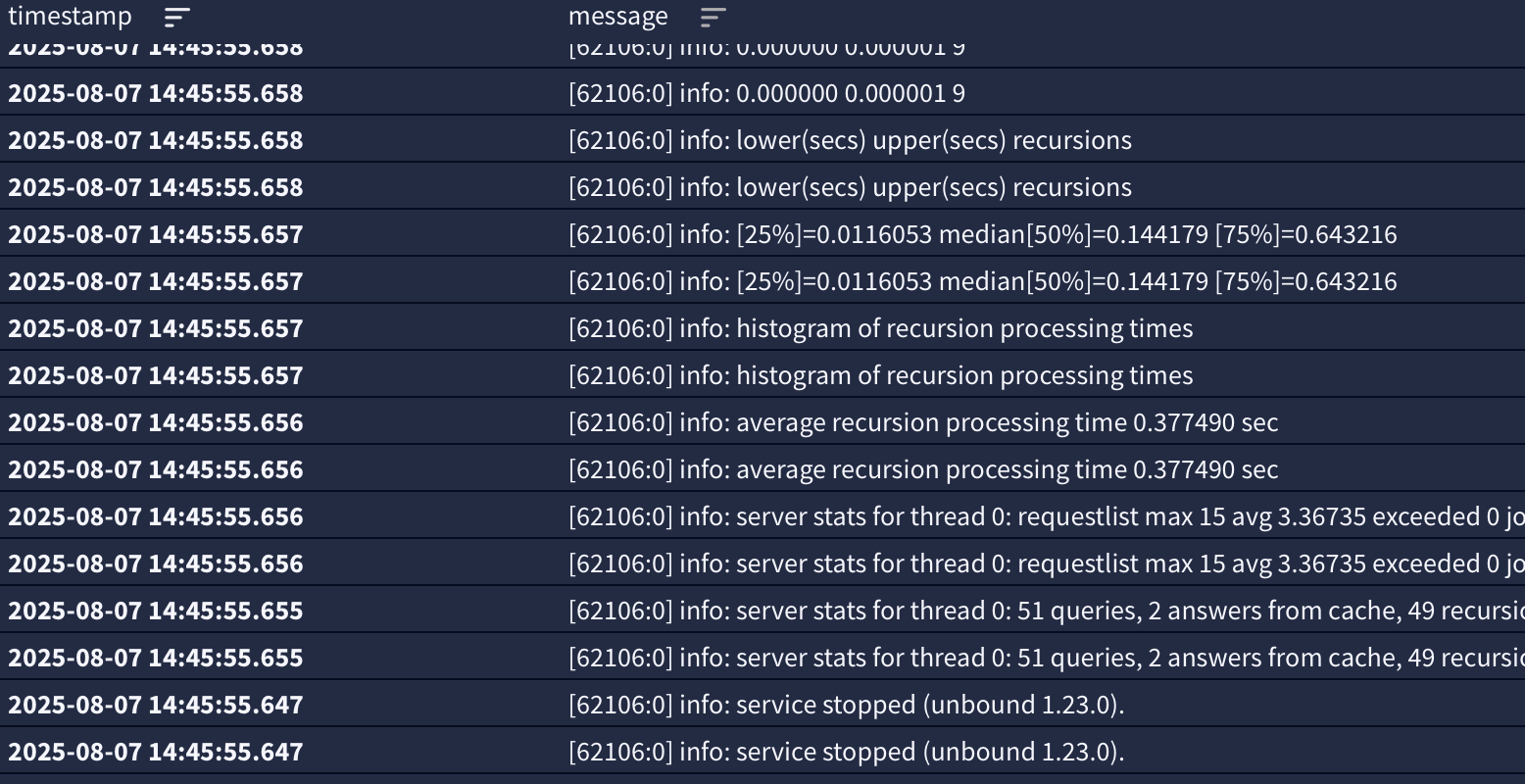
Yeah it look like this only happens when the remote host actually responds with 'refused'. So local hosts that don't respond to arp or just don't respond at all to the syslog packets will not trigger it.
-
thanks for digging in
Interesting - that honestly seems different than the previous version.
The behaviour of the server goes down/ comes up hasn't really changed.
once it gets a "refused". does it ever retry ? (say when the next message is sent)
a "default" syslog system supports retries interval and max retries options for "refused connections" are those options available to us ?
Seems it was working (without any options before) because after any logging server went down under 24.11 logging just resumed when the server came back, as you would expect a syslog sender to do without intervention. and is the case with every other system on the network sending logs to the server..
I'm guess the answer to supporting that options is no ?
hint: I tried adding them to a new conf file I created in /var/etc/syslog.d directory assuming it would process any/all conf files in the directory. sadly the service would not start so removed that config file and restarted it. I'm guessing either pfSense syslog doesn't support those options or it didn't like the second conf file in the directory ? I also just tried adding the options to existing conf file (ya the one that says do not edit It started, but when I checked the conf the options had been removed from the config. so it didn't like me adding them there.
It started, but when I checked the conf the options had been removed from the config. so it didn't like me adding them there. 

I'll just use my script in the interim it works -- in monitors and after the server goes down, then when it comes up, wait a couple of minutes and restarts. syslog and unbound -- everything works perfectly from then on.
-
Whether or not it reties it definitely shouldn't kill syslogd! https://redmine.pfsense.org/issues/16362
I would expect it to keep trying though.
-
but that's not exactly the case -- it only stops logging and does not resume to the server that went down and came back up --
I would not say it killed syslogd completely because it is still logging to a second server if configured even though it may have received a "refused connection" from either one of the two configured it is only the one going down does not resume. The other just carries on happily receiving logs.
Now perhaps if both remote servers go offline it might stop the syslog service completely (or maybe if there is only one) - I haven't tried shutting them both down at the same time and I haven't tried only having one remote configured - I guess I could try that when things are a little less busy some evening.
I guess you are saying that the retry options are not available in the pfsense version. from the documentation of a standard syslog setup, these options are specifically referenced in the context of a "refused connection" and how many times it should retry at what interval, which is exactly what the case is. Oddly enough not of the other system I have that are sending logs to the same servers are having a problem and have no specific options set.
either way thanks for the investigation. I appreciate it.
-
Well in my test setup I can reliably reproduce it killing syslogd. It's fixed in internal dev versions though so something needs back porting.
Now it could be that it keeps functioning as long as at least one remote server is available...

-
@stephenw10
In our experience syslogd dies if any target is unreachable, as noted above.
-nic -
This is just information -
I started up my 2.8 test boxPointed to a single syslog server on a different subnet - the subnet is reachable (one that I can log to if I select the correct IP) but has NO syslog server at the IP I selected. this ended in a Connection Refused (9.25:44)
The service was still running, but I hit restart anyway (from the services page) also Connection Refused (9:30:25)
Yup in both cases the IP has no server (offline)Service still running. Changed the IP to a destination on the local subnet (no exception that there is a working server on this IP either).
Notice there is no "Connection Refused" in this case, but rather ends in "Host is down"
The service itself hasn't "died" at least not yet (time of posting this) but radio silence from syslogd (nothing else in the logs)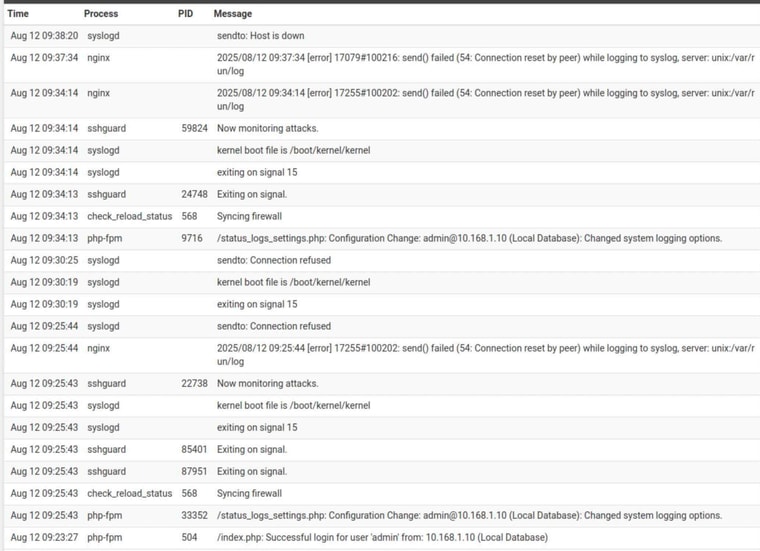
-
Something must be wanting to write syslog (maybe) it has just started aggressively logging this and many times per second (wonder if it is heading for a crash)
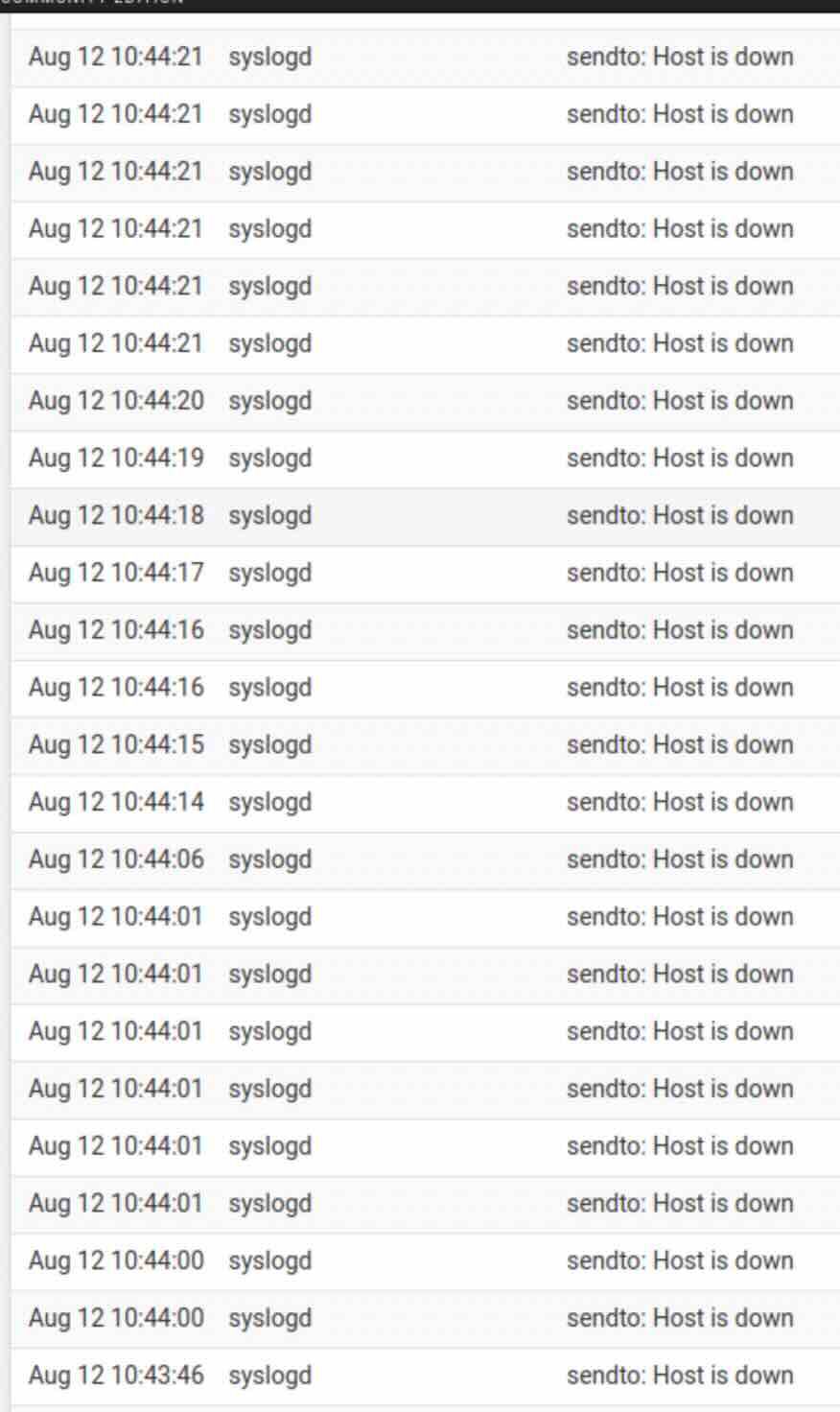
This really aggressive syslog host is down lasted until 10:54 (so about 10 minutes) then the stopped logging, the service is still running.
I'm guessing these messages are generated with something is trying to write to syslog - and it feels the constant urge to log that the host is down.(funny I don't see this on the production box when the syslog server is down) that might be a result of the production box having two destinations setup)
Should be able to verify this on the test box.
start case1 - with syslog1 (.35). to a host that goes down, syslog2 (.2) to a valid service. (this would simulate production)
then flip them case 2 - syslog2 (.2) always up, syslog1 (.35) goes down for maintenance (offline)since I don't see "host is down" messages on production (or "connection Refused" for that matter) I'd almost guess the order in which they are listed makes a difference to the message. If the valid service is second on the config it is "overwriting (masking)" failure messages from first server that is offline)
Overall then the system "thinks" the message to both was "sent", even though the first one never got it.
-
Yup that's what I see with a target that doesn't respond to arp. I'd guess it gets into a loop logging the host is down and then trying to send that to the syslog server. Repeat!
I was only able to replicate the service failing when using a target that actually responds to the traffic with refused.
-
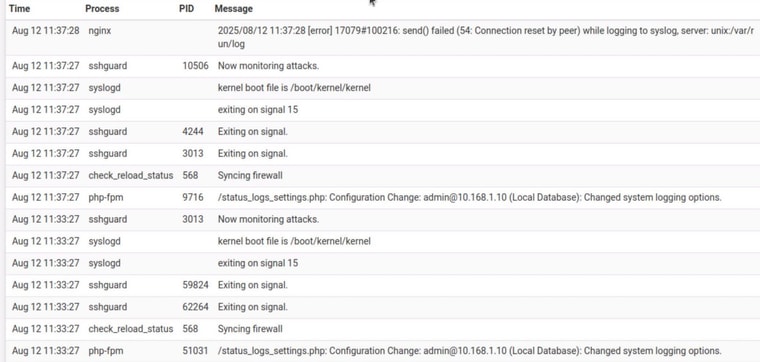
There you go, order matters (but also n both cases there is no indication of a Host is Down or connection refused.
bottom up in the log changed to add a working server in the second spot
(.35) (.2) .35 is offline
switch them
(.2) (.35) . 35 is offlinenotice nginx logged it but syslog itself says nothing in either case ...
That explains why I don't see host down or connection refused in production. it is being masked by having two servers, (in both cases)
I'm going to flip the order in production to see if it changes the overall "it resumes logging" when it goes off line and comes back up.