dpinger not reliable - ping request/replies


-
@siegmarb said in dpinger not reliable - ping request/replies:
Apr 8 07:07:12 dpinger 89446 GW_KD_DH 1.1.1.1: Alarm latency 27627us stddev 14386us loss 21%
Apr 9 11:07:14 dpinger 89446 GW_KD_DH 1.1.1.1: Clear latency 22638us stddev 53358us loss 5%
Apr 15 01:00:42 dpinger 89446 GW_KD_DH 1.1.1.1: Alarm latency 21509us stddev 5210us loss 22%
Apr 15 01:06:52 dpinger 89446 GW_KD_DH 1.1.1.1: Alarm latency 1293341us stddev 881246us loss 95%
Apr 15 01:07:07 dpinger 89446 GW_KD_DH 1.1.1.1: Alarm latency 243671us stddev 600909us loss 70%
Apr 15 01:07:48 dpinger 89446 GW_KD_DH 1.1.1.1: Clear latency 93734us stddev 349188us loss 5%
Apr 15 06:30:21 dpinger 89446 GW_KD_DH 1.1.1.1: Alarm latency 28365us stddev 7087us loss 21%
Apr 15 06:34:35 dpinger 89446 GW_KD_DH 1.1.1.1: Clear latency 28547us stddev 86447us loss 5%
Apr 16 10:44:07 dpinger 89446 GW_KD_DH 1.1.1.1: Alarm latency 28632us stddev 35032us loss 22%dpinger not reliable - ping request/replies
You can remove the word 'not'.

Test for yourself : Go here : Diagnostics > Packet Capture
and select (Capture Options) your WAN interface,
Set "View Options" to High,
Set PROTOCOL to PING, and ETHERTYPE to IPv4.
Hit the green Start.From now on, you'll see that "ICMP echo requests" are send. It's the dpinger process that pings ^^
These "ICMP echo requests" are send to an upstream gateway (you'll see the IP in the capture also) and if all goes well, and answer "ICMP echo reply" comes back.
The duration between the moment a packet was send and the answer comes back is known as :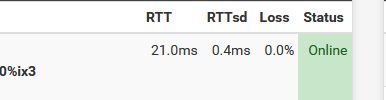
You'll se the avarage time it took, and te variation.
The simple fact that packets did come back is n enough to mark the interface as "Online".So, now you know dpinger is reliable ^^
Less reliable is probably your connection, as you've shown yourself : ICMP packets are (always) send, but not all come back. That said, a couple over several days ... that not that bad.
Or : maybe the gateway to where the packets where send to was very busy and missed a packet, so it didn't reply back.Be aware that the ICMP packets have less priority as other TCP or UDP packets, so if a ICMP gets discarded, then that's not the end of the world. It can happen.
If your connection is saturated, then its normal that you see that a ICMP packet didn't make it back. -
thank you for your answer. Further debugging shows, that dpinger does not correctly recover:
I restarted dpinger and replies are there again:
10:00:07.359483 IP 10.8.0.2 > 1.1.1.1: ICMP echo request, id 28786, seq 35848, length 9 10:00:07.836358 IP 10.8.0.2 > 1.1.1.1: ICMP echo request, id 8356, seq 0, length 9 10:00:07.886237 IP 1.1.1.1 > 10.8.0.2: ICMP echo reply, id 8356, seq 0, length 9After ~ 10 hours:
07:56:44.384429 IP 10.8.0.2 > 1.1.1.1: ICMP echo request, id 23931, seq 29764, length 9 07:56:44.404683 IP 1.1.1.1 > 10.8.0.2: ICMP echo reply, id 23931, seq 29764, length 9 07:56:44.894107 IP 10.8.0.2 > 1.1.1.1: ICMP echo request, id 23931, seq 29765, length 9 07:56:44.916906 IP 1.1.1.1 > 10.8.0.2: ICMP echo reply, id 23931, seq 29765, length 9 07:56:45.433620 IP 10.8.0.2 > 1.1.1.1: ICMP echo request, id 23931, seq 29766, length 9 07:56:45.942312 IP 10.8.0.2 > 1.1.1.1: ICMP echo request, id 23931, seq 29767, length 9 07:56:46.454289 IP 10.8.0.2 > 1.1.1.1: ICMP echo request, id 23931, seq 29768, length 9dpinger detects higher latency and loss, but does not recover:
Apr 24 07:56:59 dpinger 23931 GW_KD_DH 1.1.1.1: Alarm latency 23815us stddev 7223us loss 21%Pinging at the same time manually from the pfsense shows, that 1.1.1.1 is reachable:
/root: ping 1.1.1.1
PING 1.1.1.1 (1.1.1.1): 56 data bytes
64 bytes from 1.1.1.1: icmp_seq=0 ttl=56 time=21.769 ms
64 bytes from 1.1.1.1: icmp_seq=1 ttl=56 time=12.738 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=56 time=27.216 ms
64 bytes from 1.1.1.1: icmp_seq=3 ttl=56 time=12.617 ms
64 bytes from 1.1.1.1: icmp_seq=4 ttl=56 time=13.614 ms
64 bytes from 1.1.1.1: icmp_seq=5 ttl=56 time=22.943 msStill looks like a dpinger issue to me.
-
@siegmarb what pfSense version are you working with?
What I'm a bit surprised is that the source and destination ICMP ID is the same. Nothing wrong with it but not standard, have you set it on purpose?
10.0.8.2:23910 -> 1.1.1.1:23910 ... 10.0.8.2:37365 -> 1.1.1.1:37365For me the source ID/port is random:
WAN icmp <WAN IP>:12790 -> <monitoring IP>:8 0:0 211.625K / 211.625K 5.85 MiB / 5.85 MiB -
2.7.2-RELEASE (amd64)
built on Fri Dec 8 21:55:00 CET 2023
FreeBSD 14.0-CURRENTno, i did not set the id manually.
-
Right now, tens (hundreds) of thousands of pfSense installs use "2.7.2". Not saying that this is a proof it's 'perfect', but if for every pfSense the WAN is flaky at best, then at the end of this year, pfSense won't exist anymore.
The good news is : it's your setup ^^What about this : 2.8.0 is out, true, it's beta. It's out there for nearly a month now, and there are no big issues. So : go 2.8.0.
And again : you can disable the dpinger action, so it won't touch your WAN connection anymore. If the interface still goes down, it wasn't dpinger doing so. dpinger will still "ping", and this is just so stats get generated and "on-line" gets shown on the dashboard.
-
@siegmarb said in dpinger not reliable - ping request/replies:
no, i did not set the id manually
Ok, seeing the same on 2.7.2 (I'm on 25.03-BETA on prod), that's normal then.
-
@patient0 I think you are right. There is something not quite right or not quite understood about dpinger. I use dpinger as a check on my ISPs as is typical. Today, for example, my main head was marked as down. I simply changed the ping target and all came back. I changed from 1.1.1.1 to 4.2.2.1. There was no outage as far as I could tell. The problem is not just with 1.1.1.1 either. The ubiquitious 8.8.8.8 can have it happen as well. And I have seen some modems mark the continuous ping as a DOS threat, but that seems unlikely in this case.
This happens just occasionally and It can happen on any of my 9 servers. In this case It seems unlikely that 1.1.1.1 was down. I did not think to ping it manually.
I have noted in the past that dpinger seems to have problems recovering. For awhile I would restart it with service watchdog if it was down. That was a few versions back. With the newer versions, that has not been necessary.
Although very infrequent for me, it can be irritating as it happened in the middle of a Zoom meeting today. Miraculously no one complained.
I recognize that problems like these can be hard to find and fix.
Roy
-
dpinger is a small PHP (or bash ?) script that loops around.
For every :
it sends a ping, get the reply back, writes the time to a file,
and reloops.If pings replies stop coming back, these events are logged.
If the losses becomes to big (you can see and set these under System > Routing > Gateways > Edit ) dpinger even stops executing. This will trigger the 'action' :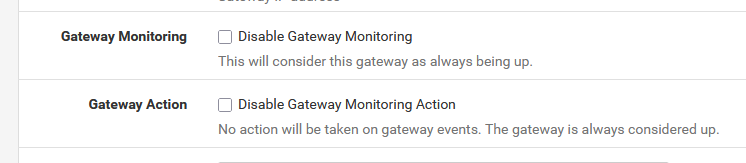
the action is : resetting the connection = taking it down, and rebuilds it.
For a WAN, this means : DHCP client gets re executed, or a pppoe is re created, etc.Using the service watchdog to 'handle' dpinger makes (to me) ... no sense, and at best will create a connection mess.
If, for some reason, pings get filtered out upstream, as ICMP is after all a low priority protocol, or the destination stops replying as it has other things to do, then dpinger will draw the conclusion that the line (uplink) is bad, which can be the case, but maybe it's just not true.
dpinger signalling the loss of ICMP replies just means ICMP didn't came back.
Is there a better method to test the uplink ? I which there was ...If you suspect that some one or some thing is playing with your ICMP packets, consider disabling the gateway action or even the monitoring. This can have also consequences of course.
Or change the settings, making it more 'patient' before it pulls the plug. -
+1 it does sound like issues with the internet connection. I'm using 2.8.0 and not seeing any issues on this or in previous release builds (I don't use Beta).
Did have dpinger restarts back on Aug 14th, but that was my VirginMedia connection down for 3 hours. Nothing in the logs since.
Maybe your internet provider is routing the ICMP to a not-nearest location causing ping issues ?
Try changing the Gateway Monitor IP to something local to you ?
-
@pwood999 Hi pwood999 and Gertjan
This happens with various service providers and I have changed ping targets. It also happens on various installs in different cities. I have installs in 5 different locations on 9 servers.
I also know about the tweaks and the other things you mentioned Gertjan and used them heavily with marginal DSL connections.
It happens very infrequently so it is difficult to know how to handle something that works 99% of the time.
By the way, 8 of my WAN connections are statics. This is something to think about. I was about to make the 9th static as well, but maybe I will wait. Statics are especially useful with HA. The current DHCP unit is the only one that is not HA.
I will be watching 2.8.1.
Thanks so much for your suggestions.
Roy