Simplifying this question, as I think it must be simple.
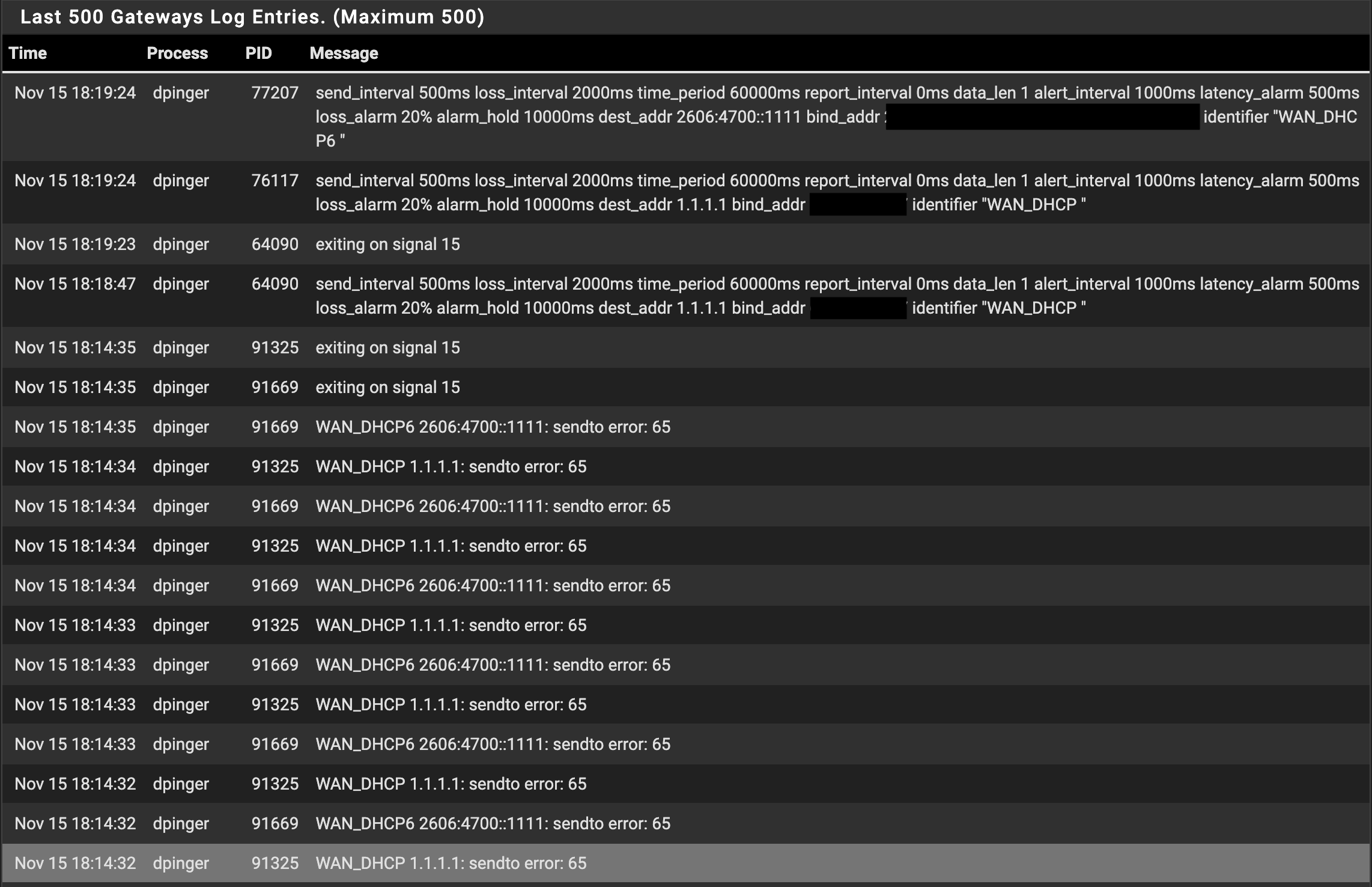
Netgate 6100. Connected to Juniper router on WAN2. Juniper router port is a trunk port for VLAN.
VLAN port is assigned 10.1.71.4. Physical port is WAN2.
Attempting to tracert from a LAN address to the VLAN address works:
Tracing route to 10.1.71.4 over a maximum of 30 hops
1 <1 ms <1 ms <1 ms 10.1.71.4
Trace complete.
But trying to get to another address in that subnet, through the VLAN port, does not:
Tracing route to 10.1.71.1 over a maximum of 30 hops
1 <1 ms <1 ms <1 ms LLL-GATEWAY.lll.lll.lll.org [10.0.0.196]
2 * * * Request timed out.
The VLAN port itself can ping 10.1.71.1, so it is not a matter of firewalls at the far end.
I have a rule on the VLAN port to allow any traffic from anywhere and of any type.
So, do these routes look correct? I will include them all, just in case there is another issue.
10.0.0.196 link#10 UHS 10 16384 lo0
10.1.71.0/29 link#14 U 1 1500 ix2.71
10.1.71.4 link#10 UHS 6 16384 lo0
123.456.789.160/27 link#8 U 7 1500 ix3
123.456.789.162 link#10 UHS 8 16384 lo0
123.456.789.163 link#10 UHS 8 16384 lo0
123.456.789.172 link#10 UHS 8 16384 lo0
123.456.789.179 link#10 UHS 8 16384 lo0
123.456.789.185 link#10 UHS 8 16384 lo0
127.0.0.1 link#10 UH 5 16384 lo0
172.16.0.0/24 link#3 U 13 1500 igc2
172.16.0.1 link#10 UHS 14 16384 lo0
172.16.222.0 link#10 UHS 18 16384 lo0
172.16.222.0/31 link#13 U 17 1420 tun_wg0
172.19.71.0/24 link#4 U 15 1500 igc3
172.19.71.1 link#10 UHS 16 16384 lo0
192.168.2.0/24 172.16.0.2 UGS 3 1500 igc2
192.168.44.0/24 10.1.71.1 UGS 4 1500 ix2.71
192.168.68.0/22 link#2 U 11 1500 igc1
192.168.68.10 link#10 UHS 12 16384 lo0
192.168.125.0/24 172.16.222.1 UGS 19 1420 tun_wg0
Thanks!