Traffic Shaping broke my LAN - topic has deviated
-
I would like to do more testing, but whit one machine, I can't afford the wife to get angry. I'm leaving it a lone for now.
I try not to care what HFSC does to individual packets, I only really care what it does on average. If I set a burst from 30% to 50% for 5ms, to me that just means for 5ms, the ratio of bandwidth between queues will be different. bursts are just ways to temporarily modify bandwidth with little change to the overall average.
Yeah… I use my internet gateway for testing purposes too. :(
You may be right about using bursts as speedboosts (increased average bitrate for all packets transmitted during a 5ms time-span, for example), but since the HFSC paper never explicitly uses it like that (m1/d is only used to modify delay, while m2 is the average), I think we need to do some testing to prove/disprove your theory.
It would be great if HFSC's m1/d could be used to modify the initial average bitrate of a connection/session, but I am obviously skeptical.
A quick thought experiment... your theory seems impossible for UDP since all individual UDP packets are their own individual transmission sessions (connectionless). If you employed m1/d like in your speedboost thoery, all UDP packets could send at 50Mbit for the first 5ms but must stay below a 30Mbit average. Since each individual UDP packet is a new session, and each new session gets an initial 50Mbit "speedboost" for 5ms, your average UDP bitrate could reach 50Mbit, because all UDP packets are transmitted during the "speedboost". The average bitrate could forever be above the m2 configured average bitrate of 30Mbit. Your "speedboost" theory breaks HFSC by causing m2 to be non-functioning.
The only way m1 and d function without breaking UDP sessions with HFSC is if m1 and d only modify individual packet transmission delay, and not the initial average session bitrate like in your "speedboost" theory.
I am pretty sure this applies to TCP as well, but I am not sure. The HFSC paper focuses on generic packet delay, never mentioning "TCP" and only mentions "UDP" once during a simulation of link-share's bandwidth sharing capabilities.It seems like HFSC's m1/d params only control the transmission delay of generic packets/frames, and nothing else.
Any criticisms are welcome. These conversations help me understand HFSC.
-
UDP " stateless" as in the state must be handled by the application, not the protocol, but even PFSense has a notion of a UDP "State". UDP doesn't "burst". The most common usage of UDP is a flow of packets that are sent at standard intervals or event based. Most UDP flows do not "burst" in the sense of TCP trying to send data, UDP just blindly sends data with no concern for congestion.
When UDP "bursts", it does so only in the sense that many packets so happened to arrived at the "same time", in some sense of the term "same time'.
And HFSC doesn't burst based on new sessions, it bursts based on the current usage of the queue. If a queue has 30Mb allocated, but only 15Mb is being used, but suddenly a bunch of traffic arrives "at the same time", HFSC will temporarily allow a higher amount of bandwidth through that is above the 30Mb. I think the burst is inverse related to the current usage of the queue, such that if the queue is at 100% usage, the burst will be 0% of the burst amount, but if you're at 50% usage, the amount of burst will be 50% of the assigned amount. Without knowing the exactness of how the burst works, I cannot know how it will function at the micro time scale.
The best way to think about HFSC is not in bandwidth, but in ratios. Actual packet scheduling is based on the current ratios and packet ordering is not part of the algorithm. HFSC decouples bandwidth and latency such that if all queues are at 100% utilization, regardless of the amount of bandwidth assigned, they will all experience the same latency. While latency for all queues are equal, the ordering of the packets are not guaranteed, unless you use the priority option, but from the sounds of it, it makes little difference.
-
Connectionless != Stateless.
-
I read a little about burst and it seems that it's more "bucket" like in that "credit" for the burst accumulates with some relation of the lack of usage of the entire allocated bandwidth. So 50% usage would not mean you can only use 50% of the burst, but the rate at which credit for the burst accumulate may be reduced by 50%. This rate may or may not be linear and in direction relation to the volume of the burst.
So I don't know if this example would be correct: If you have a 10Mb burst for 10ms, once you've used the burst, you need to not use 10Mb for another 10ms in order to get the full burst again.
It does sound more like you save current bandwidth now in order to burst bandwidth later, and not use a burst now but get penalized in the future. My guess is it's volume based and over a smooth curve, as HFSC tends to have a smoothing effect. So my current guess is if you have a 10Mb burst for 10ms, but you "saved" 5Mb of credit since the last burst, you will get that 5Mb spread smoothly over that same 10ms burst.
Of the information that I have seen, "burst" just changes the allocated bandwidth, but does not affect when a packet leaves. It sounds the same as temporarily changing the m2 to the m1 for a duration.
-
UDP " stateless" as in the state must be handled by the application, not the protocol, but even PFSense has a notion of a UDP "State". UDP doesn't "burst". The most common usage of UDP is a flow of packets that are sent at standard intervals or event based. Most UDP flows do not "burst" in the sense of TCP trying to send data, UDP just blindly sends data with no concern for congestion.
When UDP "bursts", it does so only in the sense that many packets so happened to arrived at the "same time", in some sense of the term "same time'.
And HFSC doesn't burst based on new sessions, it bursts based on the current usage of the queue. If a queue has 30Mb allocated, but only 15Mb is being used, but suddenly a bunch of traffic arrives "at the same time", HFSC will temporarily allow a higher amount of bandwidth through that is above the 30Mb. I think the burst is inverse related to the current usage of the queue, such that if the queue is at 100% usage, the burst will be 0% of the burst amount, but if you're at 50% usage, the amount of burst will be 50% of the assigned amount. Without knowing the exactness of how the burst works, I cannot know how it will function at the micro time scale.
The best way to think about HFSC is not in bandwidth, but in ratios. Actual packet scheduling is based on the current ratios and packet ordering is not part of the algorithm. HFSC decouples bandwidth and latency such that if all queues are at 100% utilization, regardless of the amount of bandwidth assigned, they will all experience the same latency. While latency for all queues are equal, the ordering of the packets are not guaranteed, unless you use the priority option, but from the sounds of it, it makes little difference.
I think it is important to know that the HFSC authors never referred to m1/d as a "burst". They only called it one thing, a way of creating a 2-part service curve to decouple bandwidth and delay allocation. I am not sure where the confusing "burst" explanation came from.
Here is a quote about priority from the first sentence of the paper:
In this paper, we study hierarchical resource management models and algorithms that support both link-sharing and guaranteed realtime services with priority (decoupled delay and bandwidth allocation).
They say that because m1/d control delay (not "speedboost"), which decides the ordering of the packets. The service curve with earliest deadline (lowest delay, without getting overly technical) will be sent first, as mentioned below.
HFSC does have an algorithm for packet ordering, it is based on SCED (Service Curve Earliest Deadline first). See the following paper for it's origins: http://www-afs.secure-endpoints.com/afs/ece/u/anoopr/OldFiles/742/Scheduling%20for%20quality%20of%20service%20guarantees%20via%20service%20curves.pdf
I think HFSC modifed it to support both real and virtual times, but I am not completely sure… still trying to absorb a couple dozen academic papers. :-\Only link-share works with ratios, because it uses Virtual Time. Real-time, obviously, works with Real Time and that is why it can guarantee delay and bandwidth when link-share does not.
-
I read a little about burst and it seems that it's more "bucket" like in that "credit" for the burst accumulates with some relation of the lack of usage of the entire allocated bandwidth. So 50% usage would not mean you can only use 50% of the burst, but the rate at which credit for the burst accumulate may be reduced by 50%. This rate may or may not be linear and in direction relation to the volume of the burst.
So I don't know if this example would be correct: If you have a 10Mb burst for 10ms, once you've used the burst, you need to not use 10Mb for another 10ms in order to get the full burst again.
It does sound more like you save current bandwidth now in order to burst bandwidth later, and not use a burst now but get penalized in the future. My guess is it's volume based and over a smooth curve, as HFSC tends to have a smoothing effect. So my current guess is if you have a 10Mb burst for 10ms, but you "saved" 5Mb of credit since the last burst, you will get that 5Mb spread smoothly over that same 10ms burst.
Of the information that I have seen, "burst" just changes the allocated bandwidth, but does not affect when a packet leaves. It sounds the same as temporarily changing the m2 to the m1 for a duration.
"Burst" is a misnomer. m1/d only control a packet's delay. A token bucket is something different which can actually achieve a "burst" as you perceive it.
Expanding on your HFSC example, if
m1=10Mb
d=10ms
m2=5MbThen we could translate this to u-max/d-max
u-max=12500 Bytes [ m1×(d÷1000)÷8 = u-max ]
d-max=10ms
r=5Mb (aka m2)This means a packet/frame with the maximum size of 12000Bytes (wayyy oversized) is guaranteed to be transmitted within 10ms, but the average bitrate cannot go over 5Mb. Once the packet is "burst", no other packets can be sent until the long-term average has fallen low-enough that another u-max sized packet can be transmitted at "burst" speeds without raising the long-term average above the m1 bitrate. (I am unsure how long "long-term" is)
That is how the HFSC paper explains it.
We should probably stop calling m1/d a "burst" because it is, at best, an over-simplification, and more likely plain wrong because m1 can be set to 0. If m1=0, there is no "burst", only added delay.
-
I've read similar examples about burst. So it sounds like "bursting" allows you to acquire a certain amount of "bandwidth debt", up to the amount set in the burst. It is kind of an extra examples to use a 1500byte packets on a 400kb link, but this hypothetical situation gets used many times. So in this case, the 1500byte packet cannot be dequeued until enough "bandwidth credits" have been accumulated, but a burst value gets set which allows the queue to acquire some "bandwidth debt", allowing it to dequeue much sooner.
This situation is a bit unnatural, except in the case of people with slow links, because the MTU is extremely large relative to the bandwidth, plus they're using a 1500byte packet and claiming it to be VoIP. 1500bytes on a 400Kb link is 30ms and that's ignoring how much bandwidth the example queue is given. In a more real world example, you have a 1Gb link and 200 byte VoIP packets, which gives you 0.0016ms. Even if you set aside 10Mb for the VoIP queue, you're still talking about an average 0.16ms queue time at saturation.
My argument is that while thinking about individual large packets on slow links is important for showing how the algorithm works, in the real world, you're more likely to have to think about statistical averages when configuring burst values. If I had a 10Gb link and I needed to set aside 2Gb for VoIP, I won't be trying to figure by burst value for a 0.0008ms duration for a 200 byte packet, I'll be more concerned about what is going on at a more macro level, relative to an 80ns packet delay, in the 1ms+ range. What is the threshold for VoIP delay before it becomes perceptible? 5ms? 10ms? 20ms? Those are the bursts I would be focusing on or some fraction of them. Maybe the optimal burst length is 50% of your target delay. If I want VoIP to get dequeued before a 10ms delay, maybe I want a 5ms burst target.
In the end, it all comes down to bandwidth management. Assuming HFSC does a good job interleaving packets in a fine-grained fashion, all you really need to do is focus on "do I have enough bandwidth to handle this traffic". The general rule is below 80% saturation, delay is not an issue. If I want to be able to handle 8Mb/s of VoIP, I really need to just have a bare minimum 10Mb or more bandwidth set aside. Given enough traffic flows, you don't get bursts of data, utilization becomes smooth and predicable. When you don't have enough bandwidth, and bursty traffic comprises a substantial portion of your bandwidth, you'll need to know the "shape" of the traffic you're try work with.
Individual flows or groups of flows have shapes when there is no congestion. Those are the shapes you want HFSC to mimic when controlling delay. The other elephant in the room is controlling your delay via bursts will always come at the expense of other queues. If VoIP is so important, why not just give that queue enough bandwidth in the first place? If you can't give it enough bandwidth, then no matter what you do, you will get delays because you can't shove 10Mb data down a 5Mb pipe without something giving.
Bursts seem more useful in the sense of someone has a highly specialized situation with a very specific traffic pattern or working with incredibly slow bandwidth rates where the packet size is large relative to the bandwidth.
-
…
If VoIP is so important, why not just give that queue enough bandwidth in the first place? If you can't give it enough bandwidth, then no matter what you do, you will get delays because you can't shove 10Mb data down a 5Mb pipe without something giving.
Bursts seem more useful in the sense of someone has a highly specialized situation with a very specific traffic pattern or working with incredibly slow bandwidth rates where the packet size is large relative to the bandwidth.
HFSC does not "burst" in the way you think it does. Browse through the HFSC paper. It is only 16 pages, iirc.
VOIP is one of the major reasons why HFSC is useful. Using the example from the HFSC paper, you can guarantee a 64Kb audio session (160Byte packet sent every 20ms) a delay of 5ms (160Bytes @ 256Kb) instead of 20ms (160Bytes @ 64Kb). I showed the u-max/d-max and m1/d/m2 notation of this exact setup in one of my previous posts.
You give the VOIP session the delay of a 256Kb (5ms) connection while only allocating an average bitrate of 64Kb, leaving more bandwidth available for applications that are not delay sensitive. VOIP is common today, I would not call it a "highly specialized situation".
Anyway, I doubt an HFSC misconfiguration could cause your problem, but removing all m1/d entries and using only m2 might be worth trying.
Hell if I know… :)
-
Every traffic shaping thread turns into an HFSC theory thread lately. Can't we just have an HFSC theory thread?
-
Every traffic shaping thread turns into an HFSC theory thread lately. Can't we just have an HFSC theory thread?
Still seems on topic to me… well, kinda. Traffic-shaper misconfigurations have killed my LAN before.
I think I have only barged in on 2 or 3 threads with my HFSC evangelism. I am just tired of the spread of HFSC misinformation. I will try to lessen my HFSC posts.
Edit: If you want to continue the HFSC-centric conversation, head over to https://forum.pfsense.org/index.php?topic=89367.0
-
VOIP is common today, I would not call it a "highly specialized situation".
If you have a 10Mb+ link that is under 80% utilization, I can guarantee any single 200byte VoIP packet will not be delayed more than ~1ms. I don't need HFSC for delay guarantees if I have enough bandwidth.
The 256Kb example was an extreme example to show a point. Few people who can afford a professional to come in and analyze their network traffic to the point of understanding how to properly configure HFSC bursts to make best use of their bandwidth for their exact current traffic usage, is not going to be stuck on a 256Kb link.
Given enough flows, bandwidth usage is predictable, there are no bursts. I've seen statics on 400Gb links that showed them near 95% utilization, yet max queue latency on the link was 0.0ms for an entire week. I'm sure rounded down. For everyone else without 400Gb trunk links and many fewer flows, the 80/20 rule will need to apply.
Statistically, this is how most network utilization goes. The exact numbers in queue may not apply, but the curve and general idea does.
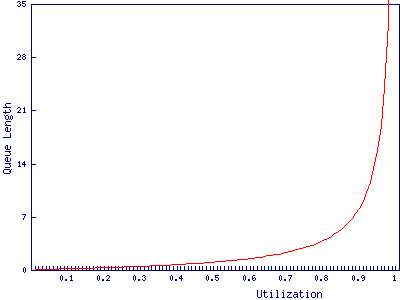
Using bursts to exactly control delay will be limited to specialized situations, like low link speeds or non-normal traffic patterns. It's much simpler to think of burst as modifying bandwidth and not caring about how it exactly affects delay with the primary concern of just managing the bandwidth. Even then, burst only really matters once you've consumed all of your normal bandwidth. The good news is that latency sensitive flows tend to also be very low bandwidth.
HFSC is a powerful tool that can let you get every last drop of bandwidth from your connection while keeping delay low for critical traffic, but I'm perfectly happy with my simplistic view and primarily using it just as a traffic shaper while maintaining 0.1ms pings. All I know is before I had HFSC, my pings were around 20-30ms during link saturation, and after HFSC, about 0.1ms with no special settings. All I did was create a separate 500Kb queue for ICMP and like magic, the ping was kept low. I don't feel I need to understand HFSC any better, at least for what I am capable of testing. My limits of knowledge on the topic may keep me from fulling utilizing it, but with no way of testing, all I an do is guess. Even if I could do better than 0.1ms, I'm not sure it would matter nor would it be useful for every case. Many times specializing for one particular case makes you worse in many other cases. Trying to configure HFSC exactly to maximize one thing could be made useless because of shifting traffic patterns.
I do enjoy the discussions. I have found several errors in my understanding.
-
The 256Kb/64Kb audio session example from the HFSC paper is actually on a 45Mbit link.
Whether or not somebody needs HFSC's exclusive features (you probably don't IMO) I cannot know, but if someone is going to use them, use them right, damnit. :)
Is your LAN still crashing?
-
The detailed level of how exactly HFSC from a math perspective is quite a bit over the head of almost anyone. I would rather take a more statistical view, which is "good enough". You talk about using bursts to control packet ordering because the examples they give lead you down that path with the papers. But who has a 45Mb link and only gives 256Kb/s to VoIP?! Really, that's crazy.
The level of detail being discussed for their examples does not scale. They are using examples in time resolutions of 10s of milliseconds, when in the real world, you're going to be working in micro and nano seconds. This is magnitudes beyond what people can handle in their mental models. It's like trying to describe how much power is released in a super nova. You can try to use analogies of tons of TNT, but it still does not do it justice. Kilobits per second, yeah, that's fine, but gigabits? Nope.
When you're working with such short time scales, being accurate can be detrimental to the overall picture. Statistics becomes a better way of handling large numbers of stuff. If you have a low link speed where packets take more than 10ms, you may need to know more about HFSC.
-
The detailed level of how exactly HFSC from a math perspective is quite a bit over the head of almost anyone. I would rather take a more statistical view, which is "good enough". You talk about using bursts to control packet ordering because the examples they give lead you down that path with the papers. But who has a 45Mb link and only gives 256Kb/s to VoIP?! Really, that's crazy.
The level of detail being discussed for their examples does not scale. They are using examples in time resolutions of 10s of milliseconds, when in the real world, you're going to be working in micro and nano seconds. This is magnitudes beyond what people can handle in their mental models. It's like trying to describe how much power is released in a super nova. You can try to use analogies of tons of TNT, but it still does not do it justice. Kilobits per second, yeah, that's fine, but gigabits? Nope.
When you're working with such short time scales, being accurate can be detrimental to the overall picture. Statistics becomes a better way of handling large numbers of stuff. If you have a low link speed where packets take more than 10ms, you may need to know more about HFSC.
You are disagreeing with leaders in the field of networking calculus and statistics.
I would not be so bold with nothing but anecdotes to support your assertions…
Just read the paper. Many of your questions and concerns are answered in plain english, some are even answered in the first damn line of the paper... :)
I read through the paper every time I make an HFSC-related post, to re-confirm my understanding and assure my post is as factual as possible. This is becoming annoying... I would rather we both try to understand HFSC, than you try to guess and I correct you.You might find this simple, 2-page paper useful (I did); http://blizzard.cs.uwaterloo.ca/keshav/home/Papers/data/07/paper-reading.pdf
Like Derelict said, let's take our HFSC-centric posts to my "HFSC explained" thread, so we can keep any useful HFSC info in a central place. :)
-
The detailed level of how exactly HFSC from a math perspective is quite a bit over the head of almost anyone. I would rather take a more statistical view, which is "good enough". You talk about using bursts to control packet ordering because the examples they give lead you down that path with the papers. But who has a 45Mb link and only gives 256Kb/s to VoIP?! Really, that's crazy.
The level of detail being discussed for their examples does not scale. They are using examples in time resolutions of 10s of milliseconds, when in the real world, you're going to be working in micro and nano seconds. This is magnitudes beyond what people can handle in their mental models. It's like trying to describe how much power is released in a super nova. You can try to use analogies of tons of TNT, but it still does not do it justice. Kilobits per second, yeah, that's fine, but gigabits? Nope.
When you're working with such short time scales, being accurate can be detrimental to the overall picture. Statistics becomes a better way of handling large numbers of stuff. If you have a low link speed where packets take more than 10ms, you may need to know more about HFSC.
You are disagreeing with leaders in the field of networking calculus and statistics.
I would not be so bold with nothing but anecdotes to support your assertions…
Just read the paper. Many of your questions and concerns are answered in plain english, some are even answered in the first damn line of the paper... :)
I read through the paper every time I make an HFSC-related post, to re-confirm my understanding and assure my post is as factual as possible. This is becoming annoying... I would rather we both try to understand HFSC, than you try to guess and I correct you.You might find this simple, 2-page paper useful (I did); http://blizzard.cs.uwaterloo.ca/keshav/home/Papers/data/07/paper-reading.pdf
Like Derelict said, let's take our HFSC-centric posts to my "HFSC explained" thread, so we can keep any useful HFSC info in a central place. :)
I'm not disagreeing with them, I'm just saying math proofs don't tell you how to use HFSC practically, only that it works "as expected" assuming you understand it. 99% of well experienced and educated people in networking will not understand how network traffic works in sub 1ms time scales, so don't even think about time scales that small. I do agree that my "evidence" is anecdotal, I have limited tools. Another term for "anecdotes" is "data points", albeit with high uncertainty, there is some truth to anecdotes.
In order to property configure HFSC the way you you've been giving examples, you would need to know these and how these interact:
- Packet Size
- PPS(Packets per Second) during transmission
- Average Bandwidth
- Number of flows
- Distribution of packets within a flow
- Distribution of packets among all flows
The examples the HFSC links use are simple to prove a point, but do not reflect the complications of a real network. To take the example at face value is to over-simplify the issue, in other words, don't think about individual packets unless that's exactly what happens at the bandwidths you're working with.
Up to this point I've been arguing an almost laissez faire sort of configuration while you've been arguing an extremely precise. I know I was mostly playing devil's advocate to give an alternative view, but I think the middle ground is best. In this paper(http://www.cs.cmu.edu/~hzhang/papers/SIGCOM97.pdf) that you linked at one point in another thread, it talks about 160byte VoIP packets with an average of 64Kb/s. The way they configured and talked about the burst duration is as a target latency. They set the duration to 5ms as they wanted a 5ms target. m1 was set to the packet size, 160 bytes(not bandwidth like you've mentioned), then spread over the 5ms, they gave the example of 256Kb/s. Because 160bytes/5ms=256Kb.
What I was able to gain from this example is you set the m1 bandwidth equal to the size you wish to "burst", and the duration to the time in which you wish the extra bytes to be transferred.
I feel fairly confident that the d(duration), for the purpose of latency sensitive traffic, should be set to your target worst latency. m1 should be thought of not as bandwidth, but the size in bits of the total number of packets relieved during that duration. m2 would be set as the average amount of bandwidth consumed.
-
I'm not disagreeing with them, I'm just saying math proofs don't tell you how to use HFSC practically, only that it works "as expected" assuming you understand it. 99% of well experienced and educated people in networking will not understand how network traffic works in sub 1ms time scales, so don't even think about time scales that small. I do agree that my "evidence" is anecdotal, I have limited tools. Another term for "anecdotes" is "data points", albeit with high uncertainty, there is some truth to anecdotes.
In order to property configure HFSC the way you you've been giving examples, you would need to know these and how these interact:
- Packet Size
- PPS(Packets per Second) during transmission
- Average Bandwidth
- Number of flows
- Distribution of packets within a flow
- Distribution of packets among all flows
The examples the HFSC links use are simple to prove a point, but do not reflect the complications of a real network. To take the example at face value is to over-simplify the issue, in other words, don't think about individual packets unless that's exactly what happens at the bandwidths you're working with.
**Up to this point I've been arguing an almost laissez faire sort of configuration while you've been arguing an extremely precise. I know I was mostly playing devil's advocate to give an alternative view, but I think the middle ground is best. In this paper(http://www.cs.cmu.edu/~hzhang/papers/SIGCOM97.pdf) that you linked at one point in another thread, it talks about 160byte VoIP packets with an average of 64Kb/s. The way they configured and talked about the burst duration is as a target latency. They set the duration to 5ms as they wanted a 5ms target. m1 was set to the packet size, 160 bytes(not bandwidth like you've mentioned), then spread over the 5ms, they gave the example of 256Kb/s. Because 160bytes/5ms=256Kb.
What I was able to gain from this example is you set the m1 bandwidth equal to the size you wish to "burst", and the duration to the time in which you wish the extra bytes to be transferred.
I feel fairly confident that the d(duration), for the purpose of latency sensitive traffic, should be set to your target worst latency. m1 should be thought of not as bandwidth, but the size in bits of the total number of packets relieved during that duration. m2 would be set as the average amount of bandwidth consumed.**
Incorrect. m1 and m2 define bandwidth.
This quote from the HFSC paper is useful because it clarifies differences between the parameters used in the paper (u-max, d-max, r), and the parameters that pfSense uses (m1, d, m2).
Each session i is characterized by three parameters: the largest unit of work, denoted u-max, for which the session requires delay guarantee, the guaranteed delay d-max, and the session's average rate r. As an example, if a session requires per packet delay guarantee, then u-max represents the maximum size of a packet. Similarly, a video or an audio session can require per frame delay guarantee, by setting u-max to the maximum size of a frame. The session's requirements are mapped onto a two-piece linear service curve, which for computation efficiency is defined by the following three parameters: the slope of the first segment m1, the slope of the second segment m2, and the x-coordinate of the intersection between the two segments x. The mapping (u-max, d-max, r) -> (m1, x, m2) for both concave and convex curves is illustrated in Figure 8.
The paper uses u-max (packet/frame size) in it's examples, but pfSense uses m1 (bandwidth).
When glancing at a configuration using m1, d, and m2, it is obvious whether the parameters are meant to decrease delay (m1 > m2) or increase delay (m1 < m2).
The u-max/d-max notation is not as intuitive.I pulled the quote from the HFSC thread, if you would like to move this HFSC-related conversation there.
https://forum.pfsense.org/index.php?topic=89367.0Edit: Fixed typo in quote from HFSC paper.