HFSC explained - decoupled bandwidth and delay - Q&A - Ask anything
-
Ok. I'll bite.
Let's shape a site-to-site OpenVPN. I have one over which lots of different traffic gets sent and received. VoIP, file transfers, etc.
I realize it's pretty hard to shape the traffic inside the tunnel, so I want to start by shaping the OpenVPN connection itself.
I just ran a packet capture and when I am sending a file using scp, the maximum UDP packet sent is 1433 bytes, which is 11464 bits.
I have a 10Mbit/sec upload that is pretty reliable at that rate. That means it'll take .001156 seconds to send one packet, or 11.56ms
If I wanted to guarantee 15ms delay up to 2Mbit/sec average would I set:
m1: 11464
d: 11.56
m2: 20% (or 2,000,000)What about linkshare/bandwidth settings? When do they come into play if at all? After the 2Mbit/sec real-time is exceeded?
Should I just round up the packet size to 1500?
If I wanted to make sure this service curve was ALWAYS in effect, could I put a 2Mbit upperlimit in place as well, effectively limiting my OpenVPN to 2Mbits upload but with all traffic always in the real-time queue?
-
Interesting. I had a qVPN set at:
Bandwidth 5%
real-time - - 5%
link-share - - 5%–- 172.22.81.8 ping statistics ---
100 packets transmitted, 100 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 48.403/50.989/68.843/2.543 msI changed that to:
Bandwidth 10%
real-time 11.5Kb 12 10%
link-share - - 10%–- 172.22.81.8 ping statistics ---
100 packets transmitted, 100 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 56.007/58.560/66.571/1.727 ms--- 172.22.81.8 ping statistics ---
100 packets transmitted, 100 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 56.491/59.047/71.021/2.572 msDelay increased by about 8ms. But my phone reported 12ms jitter throughout an upload speed test.
Note that you can't just leave the bandwidth blank. It puts something in there by default and the rules won't load. I think it uses the interface speed or something.
-
Ok. I'll bite.
Let's shape a site-to-site OpenVPN. I have one over which lots of different traffic gets sent and received. VoIP, file transfers, etc.
I realize it's pretty hard to shape the traffic inside the tunnel, so I want to start by shaping the OpenVPN connection itself.
I just ran a packet capture and when I am sending a file using scp, the maximum UDP packet sent is 1433 bytes, which is 11464 bits.
I have a 10Mbit/sec upload that is pretty reliable at that rate. That means it'll take .001156 seconds to send one packet, or 11.56ms
If I wanted to guarantee 15ms delay up to 2Mbit/sec average would I set:
m1: 11464
d: 11.56
m2: 20% (or 2,000,000)m1 needs to be bitrate and d needs to be your worst-case delay. Also, I think 0.001156 seconds is ~1.16ms. :P
If you want your OpenVPN to always get good response, you could give it the maximum real-time allocation of 80%. 8Mbit can send a 1433 byte packet in 1.4ms, so you config should be:
m1=8Mb
d=2 (round up from 1.4)
m2=2MbWhat about linkshare/bandwidth settings? When do they come into play if at all? After the 2Mbit/sec real-time is exceeded?
You could, depending on your setup, either allocate your OpenVPN queue with real-time, using your current configuration, or with link-share you could set all other queues to have an allowed increase in worst-case delay.
Imagine if a packet had a leaf queue real-time allocation of 10Mbit, a leaf queue link-share/"Bandwidth" allocation of 20Mbit, and a root queue "Bandwidth" (usually link-rate) of 50Mbit. This would mean the packet will get 10Mbit guaranteed, from real-time, and using the ratio of the 20Mbit link-share to additionally allocate all unused bandwidth. So, if there was a competing link-share queue with 10Mbit allocated, our original packet packet would have 10Mbit (guaranteed by real-time) plus the additional bandwidth, calculated by splitting the excess bandwidth proportionally between our 2 active link-share queues. Our packet would get a total bandwidth of 10Mbit plus ~67% of 40Mbit, so… like ~36.8Mbit for our packet.
Edit#2: Here is a more intuitve explanation of the above example. Imagine 2 packets were queued simultaneosly, with one being assigned to qPacket and the other being assigned to qOtherPkt. This would mirror the above example.
*WAN Bandwidth=**50Mb** –qPacket Bandwidth/Link-share.m2=**20Mb** Real-time.m2=**10Mb** –qOtherPkt Bandwidth/Link-share.m2=**10Mb**Should I just round up the packet size to 1500?
Just for the sake of correctness and avoiding unknown consequences, I say no.
I am still trying to figure out the impact of over-sizing this value. It may just cause more CPU usage or it might cause … well, I dunno. :)Edit: Notice that, simply because of the limited granularity of milliseconds, the configuration I calculate above had to be rounded up to 2ms, and an 8Mbit connection can send 16000bits/2000bytes in 2ms, so… maybe it does not matter. I was hoping that the u-max (actual packet size, not bitrate) would act like admission control and put oversized packets into a different queue, but I have not experienced this in any of my simulations. I hope it proves to be true though.
If I wanted to make sure this service curve was ALWAYS in effect, could I put a 2Mbit upperlimit in place as well, effectively limiting my OpenVPN to 2Mbits upload but with all traffic always in the real-time queue?
Yes.
In theory, real-time allocation defines both the minimum and maximum bandwidth, but I have not been able to allocate real-time without also having link-share functionality in the queue. This is somewhat tolerable though, since we have upper-limit.Let me know if any of this works. :)
-
Interesting. I had a qVPN set at:
Bandwidth 5%
real-time - - 5%
link-share - - 5%–- 172.22.81.8 ping statistics ---
100 packets transmitted, 100 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 48.403/50.989/68.843/2.543 msI changed that to:
Bandwidth 10%
real-time 11.5Kb 12 10%
link-share - - 10%–- 172.22.81.8 ping statistics ---
100 packets transmitted, 100 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 56.007/58.560/66.571/1.727 ms--- 172.22.81.8 ping statistics ---
100 packets transmitted, 100 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 56.491/59.047/71.021/2.572 msDelay increased by about 8ms. But my phone reported 12ms jitter throughout an upload speed test.
Note that you can't just leave the bandwidth blank. It puts something in there by default and the rules won't load. I think it uses the interface speed or something.
Your results are somewhat expected since you essentially told the queue to limit the bitrate of a packet to 11.5Kb for 12ms. See if the configuration in my above post improves your delay.
-
Yeah, being off by a place value doesn't help :/
-
Yeah, being off by a place value doesn't help :/
I blame the metric system. :)
…
Note that you can't just leave the bandwidth blank. It puts something in there by default and the rules won't load. I think it uses the interface speed or something.Though, I think you can put 1Kb (arbitrary number), so it will not throw errors, then put 0Kb into link-share's m2. I tested this and did not get the expected results. Here is a quote by the author of ALTQ to explain what my expected results were;
It is also possible to set either of the service curves to be 0.
When the real-time service curve is 0, a class receives only excess bandwidth.
When the link-sharing service curve is 0, a class cannot receive excess bandwidth. Note that 0 link-sharing makes the class non-work conserving.I need to test this more. Whether setting link-share to 0 works as expected or not is unimportant considering that we have upper-limit to accomplish practically the same thing.
-
Here is a graph that shows how a service curve works. This graph shows a service curve (blue color) with the following values;
m1=256Kb (slope of first segment)
d=5 (x-projection of where the slopes meet, aka the maximum transmission delay)
m2=64Kb (slope of second segment)This example is from the audio session example from the HFSC paper. The audio stream sends a single 160 byte packet every 20 ms (equivalent to 64Kbps).
The blue lines are the service curve (m1, d, m2).
The red lines show the audio packets. (Arrival/departure time and amount of data transmitted.)
The black lines show the time where no data is being transmitted.
The orange lines denote 20ms time-spans, starting from the arrival of the first audio packet at 5ms.
The x-axis is time and the y-axis is data transmitted.In the graph, the first audio packet arrives at 5ms. You can see that the transmission time of a 160 byte audio packet is 5ms (160 bytes @ 256Kbps), while the long-term average is 64Kbps. Notice how the graphing of the audio packets perfectly follows the service curve.

-
How to use link-share.
Link-share works in ratios because it's primary function is to "share" bandwidth between other link-share allocations. Link-share achieves this sharing ability by using "virtual time" for all link-share queues, which allows for bit-rates to increase or decrease, but the proportions will stay the same. Real-time, uses actual time. You can see my post here for an example of link-share's proportional throughput sharing. Do realize that you cannot guarantee absolute bitrates with link-share (unless there are no real-time allocations), but you can guarantee a proportional percentage of the unused bandwidth.Example: If I give 600Kb to queue-A, and 300Kb to queue-B, if a real-time queue needs to preempt, the virtual time may be increased from 1 second to 2 seconds (because real-time forced it's way in), causing the 600Kb of queue-A, and the 300Kb of queue-B to drop to 300Kb and 150Kb, respectively, for the given time-span. The proportions of the unused bandwidth are kept intact (2:1).
Because of link-share's non-absolute number "problem", I think it is nonsense to use link-share to decrease delay. Although, I do think it makes sense to use link-share to increase worst-case delay, for example m1=0Kb, d=50, m2=<arbitrary bitrate=""></arbitrary> would give a queue an increased worst-case (since it is link-share, it will get the best delay it can without preempting higher priority queues) delay of 50ms, while simultaneously still allowing whatever bandwidth ratio as set by m2. This means other link-share (and real-time, obviously) allocations would be able to preempt.
I need to do some rather complex testing (for my level of networking skills) to prove whether or not link-share's m1/d can be depended on to decrease delay, in relation to other link-share queues.
PS - Link-share may be able to decrease delay by setting m1 higher than m2 (ex. m1=256Kb, d=5, m2=64Kb), but the problem that confuses me is that link-share's m2 (and maybe m1?) is assuredly dynamic (unknown), which makes the relationship to m1/d very confusing, since their ratios may change whenever a higher priority queue needs throughput. This is why I think link-share should only be used to increase delay (0Kb cannot be proportioned any other way than 0, as far as I know).
Help Me!
I need to make a more concise and intuitive wiki entry about HFSC and if you guys could give me some pointers on what I need to include, explain more clearly, or any other pointers (does my graph make sense or just confuse?), I would like to hear them. What do I need to include? What should I leave out, or put into a separate "HFSC details" section? Do you want to see more real-world graphs, stats, etc? What popular traffic-shaping examples should I include?I have climbed so deep into the HFSC rabbit-hole that it is hard to see out. :P
:D
-
Interesting. I had a qVPN set at:
Bandwidth 5%
real-time - - 5%
link-share - - 5%–- 172.22.81.8 ping statistics ---
100 packets transmitted, 100 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 48.403/50.989/68.843/2.543 msI changed that to:
Bandwidth 10%
real-time 11.5Kb 12 10%
link-share - - 10%–- 172.22.81.8 ping statistics ---
100 packets transmitted, 100 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 56.007/58.560/66.571/1.727 ms--- 172.22.81.8 ping statistics ---
100 packets transmitted, 100 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 56.491/59.047/71.021/2.572 msDelay increased by about 8ms. But my phone reported 12ms jitter throughout an upload speed test.
Note that you can't just leave the bandwidth blank. It puts something in there by default and the rules won't load. I think it uses the interface speed or something.
Did you ever try this out? I remember it calculating to ~2ms delay vs ~6ms.
I prefer to look at it like you dropped your latency by 66%, instead of simply saying you only improved your latency by an unnoticeable 4ms… ;)
I bet gamers would be excited to drop their ping by a few %. Anyone know of any good articles on the general type of traffic that modern FPSs have? (Low bandwidth, small packet, high PPS UDP?) I found a few articles and papers, but most were old.
-
Not really. I'm currently running this on WAN:
queue qVPN on em2 bandwidth 15% hfsc ( realtime (30%, 4, 15%) )
It seems to have improved my remote desktop but I don't really have a way to measure it at the moment.
-
Mumble with a 128Kb/s stream and 10ms per 160 byte packet. Similar to the HFSC example, but twice as much bandwidth, which also means 1/2 the delay. Instead of 20ms delays, now we're at 10ms delays, for one stream. If you want to have enough bandwidth for 4 steams, you need 512Kb/s, which now means you have a 2.5ms delay. Is it really worth configuring m1+d over 2.5ms?
This example doesn't work as simple for for a few streams because there is a good chance all 4 people are on the same Murmur server at the same time, meaning they'll be all getting packets at roughly the same time, increasing the chance of packets arriving in a single burst. As you start to approach a larger business and you have 100 people, most will not be talking at the same time or in the same group at the same time. Very little synchronizing.
I still think m1+d is primarily a tool for managing low bandwidth or very special situations.
2.5ms is best-case delay, but your worst-case delay is still 10ms.
If 512Kb is enough bandwidth for 4 servers, you have not decreased the worst-case/guaranteed delay. If all 4 sessions were active simultaneously, the worst-case delay would be exactly the same as if there was 1 session active with 128Kb allocated. Four 160 byte packets @ 512Kbit/sec = 10ms. One 160 byte packet @ 128Kb = 10ms.
An important feature of HFSC, or any QoS implementation, is guaranteed delay bounds. QoS relies on worst-case guarantees. "Best-effort" is rather useless for real-time services.
It's late and I know I'm missing a bit of something in my numbers, but they are ballpark and delay should approach 0ms as the bandwidth goes up. Even one of the HFSC papers shows the maximum 160byte packet delay as a simple function of packet-size/bandwidth, with the 160byte packet @ 64Kb/s having a just under 20ms measured latency during their torture test.
Again, I'm not trying to downplay m1+d, but just be careful of your audience if trying to help a home user.
Please cite your source for that. I believe you are mistaken.
I am looking at the HFSC paper and the graph for the audio session shows ~1ms delays. Here is a (poor quality) picture from the slideshow at the author's website:
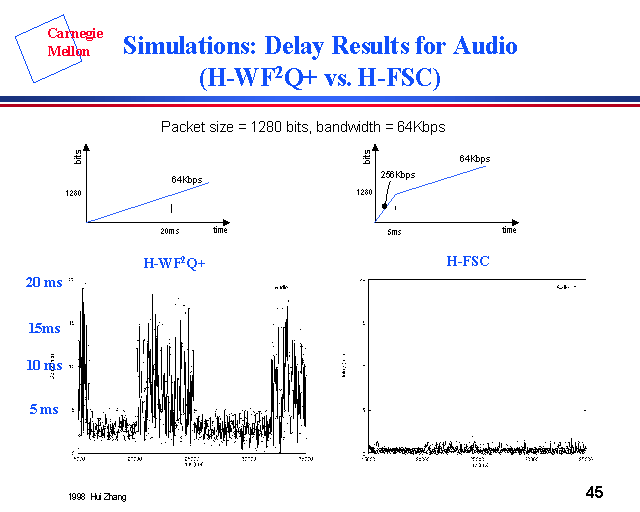
Please cite your source for that. I believe you are mistaken.
Real-time audio queue:
m1=256Kb [ u-max × 8 × (1000ms ÷ 5ms) ]
d=5
m2=64KbYou even used this as your example. This is what I was talking about when I said
Even one of the HFSC papers shows the maximum 160byte packet delay as a simple function of packet-size/bandwidth, with the 160byte packet @ 64Kb/s having a just under 20ms measured latency during their torture test.
Even your linked image shows the same thing, 1280bit(160byte) packet with a graph that shows a 20ms max, which is the time it takes a 64Kb/s link to send 160bytes, then a second graph that shows a 5ms max, which is the time it takes to send 160bytes down a 256Kb link. Yes, most of the time it's around 1ms, but the guaranteed max is 5ms, and there is a data point or two near the 5ms border.
If 512Kb is enough bandwidth for 4 servers, you have not decreased the worst-case/guaranteed delay. If all 4 sessions were active simultaneously, the worst-case delay would be exactly the same as if there was 1 session active with 128Kb allocated. Four 160 byte packets @ 512Kbit/sec = 10ms. One 160 byte packet @ 128Kb = 10ms.
Yes and no. The maximum delay is based on the maximum amount of consecutive data the must be sent at the "same time". In the case of a single 64Kb stream sending 160byte packets, the individual packets must be sent atomically. As your bandwidth increases, the number of packets increase, but the size remains the same. Yes, your worst case remains the same, but the chance of the worst case has been reduced by the number of streams.
Say you started off with a 50% chance of greater than 5ms of delay with 1 stream, but now you have 4 streams and 4x the bandwidth, so now your chance is 1/4 of 50%. At some point that chance of the worst case becomes statistically insignificant. Of course there can be pathological cases that are sometimes biased towards, and an absolute guarantee is nice to have. but it does come at the expense of requiring very intimate knowledge of your traffic patterns and bandwidth requirements, which are ever changing. But given a certain set of assumptions, you can know what your maximum delay will be.
It's rare to have exactly the amount of bandwidth you need, you either have too much or too little. With too much, delay should not be an issue, with too little, event HFSC can't help you. This is not a good argument for technicality reasons, but is a good argument for practicality reasons. I only say this because I don't want people to focus too much on micromanaging their bandwidth, when it's easier and safer to have a safety buffer.
This is why I personally went with a 45%/30% for my high priority queue. I should have plenty of raw bandwidth, but in case crap hits the fan, it can support a bit of burst.
-
Please cite your source for that. I believe you are mistaken.
Real-time audio queue:
m1=256Kb [ u-max × 8 × (1000ms ÷ 5ms) ]
d=5
m2=64KbYou even used this as your example. This is what I was talking about when I said
Even one of the HFSC papers shows the maximum 160byte packet delay as a simple function of packet-size/bandwidth, with the 160byte packet @ 64Kb/s having a just under 20ms measured latency during their torture test.
Even your linked image shows the same thing, 1280bit(160byte) packet with a graph that shows a 20ms max, which is the time it takes a 64Kb/s link to send 160bytes, then a second graph that shows a 5ms max, which is the time it takes to send 160bytes down a 256Kb link. Yes, most of the time it's around 1ms, but the guaranteed max is 5ms, and there is a data point or two near the 5ms border.
If 512Kb is enough bandwidth for 4 servers, you have not decreased the worst-case/guaranteed delay. If all 4 sessions were active simultaneously, the worst-case delay would be exactly the same as if there was 1 session active with 128Kb allocated. Four 160 byte packets @ 512Kbit/sec = 10ms. One 160 byte packet @ 128Kb = 10ms.
Yes and no. The maximum delay is based on the maximum amount of consecutive data the must be sent at the "same time". In the case of a single 64Kb stream sending 160byte packets, the individual packets must be sent atomically. As your bandwidth increases, the number of packets increase, but the size remains the same. Yes, your worst case remains the same, but the chance of the worst case has been reduced by the number of streams.
Say you started off with a 50% chance of greater than 5ms of delay with 1 stream, but now you have 4 streams and 4x the bandwidth, so now your chance is 1/4 of 50%. At some point that chance of the worst case becomes statistically insignificant. Of course there can be pathological cases that are sometimes biased towards, and an absolute guarantee is nice to have. but it does come at the expense of requiring very intimate knowledge of your traffic patterns and bandwidth requirements, which are ever changing. But given a certain set of assumptions, you can know what your maximum delay will be.
It's rare to have exactly the amount of bandwidth you need, you either have too much or too little. With too much, delay should not be an issue, with too little, event HFSC can't help you. This is not a good argument for technicality reasons, but is a good argument for practicality reasons. I only say this because I don't want people to focus too much on micromanaging their bandwidth, when it's easier and safer to have a safety buffer.
This is why I personally went with a 45%/30% for my high priority queue. I should have plenty of raw bandwidth, but in case crap hits the fan, it can support a bit of burst.
You are advising people in a thread dedicated to understanding a QoS algorithm, and you say "best effort" is good enough. By definition, "best effort" cannot support QoS, so you may be arguing to the wrong crowd. :( Then you follow up with "with too little [bandwidth], even HFSC can't help you.", like HFSC is at fault for being incapable of sending 20mbit through a 10mbit pipe… You need to spend more time on your posts.
Meh... I am tired of correcting your premature assumptions. Let us just pretend that I corrected a bunch of stuff in your post and move on.
Yeah, there are some unrealistic expectations of QoS/HFSC, but is that related to the topic of this thread? I say no, but as long as the posts are helpful, I have no problem. I know you are capable of making a better quality of post, but you chose not to, which is why I am angry.
If you have a simple, concise posit with some sources or detailed examples to support it, please share it. Heck, even just ask a question once or twice if you could use some help. I think I have corrected 40+ statements that were factually incorrect and got like 3 questions from you. I have made mistakes myself, but they were not for lack of effort (well, maybe sometimes...).
-
i recently moved back to HFSC from CBQ and so far it works good, in my case what Nullity says, his theory holds true. I deal in voip only but only difference is where i live, isp blocks voip so we setup a udp openvpn tunnel a route voip calls only through it and after doing packet captures on pfsense i realized the voip audio packets instead of 160bytes were 279 byes for me considering the openvpn overhead so based on this i set me voip queue as Nullity described in his voip post and i noticed my call jitter went down by a few ms on a saturated line (my line speed is 12Mb down and 3Mb up, but it goes to 12.5/3.5).
what i wanted to know is if we use this realtime values do we still need to use link share because in all the argument above i got confused if that holds true in a saturated situation or realtime
-
i recently moved back to HFSC from CBQ and so far it works good, in my case what Nullity says, his theory holds true. I deal in voip only but only difference is where i live, isp blocks voip so we setup a udp openvpn tunnel a route voip calls only through it and after doing packet captures on pfsense i realized the voip audio packets instead of 160bytes were 279 byes for me considering the openvpn overhead so based on this i set me voip queue as Nullity described in his voip post and i noticed my call jitter went down by a few ms on a saturated line (my line speed is 12Mb down and 3Mb up, but it goes to 12.5/3.5).
what i wanted to know is if we use this realtime values do we still need to use link share because in all the argument above i got confused if that holds true in a saturated situation or realtime
In the original HFSC implementation, there was no separate real-time & link-share (or upper-limit) parameter. There was only a single "service curve" parameter that simultaneously set both real-time & link-share to the same values.
So, set them both to the same (unless you know a good reason to do otherwise). Simultaneously using link-share & rea-time should not hurt since real-time has priority anyway.
Also, remember that most pfSense queues already have link-share's m2 param set to the queue's "Bandwidth" value automatically…
-
ok thanks so shall i set the bandwidth, link share and realtime to same or can bandwidth be set higher than realtime, if we use link share then that overrides bandwidth right.
the other thing i noticed is suppose if the line speed is 12.5Mbps down and we set the root queue to 12Mbps then the effective speed i get is around 11Mbps or at most 11.5Mbps, it goes no where near the 12Mbps mark set on the root queue, now the same if i change to CBQ then it very accurately touches the full 12Mnps (this i tested just with one lan client connected and maxed out the line with speedtest as well as tried with torrents)
the other issue is pfsense doesnt allow setting a root queue bandwidth in decimals so if line is 12.5Mbps, i cant set 12.25Mbps so i have to convert to Kbps and use that
-
I wouldn't use realtime, it's non-intuitive and very easy to use it wrong. Link-share is good enough.
-
Well I don't understand what's wrong in using it, all it does is give that queue a minium value all the time compared to link share which would give that queue the set bandwidth when it's back logged, and in the case of voip you need to have real-time bandwidth available as soon as the call starts so the signaling isn't delayed which would inturn increase call setup and RTP time. Even if there is no traffic for that queue which has real-time set that bandwidth isn't lost and still available for other queues.
In voip we at least know the packet size and what interval it's sent so I guess it's straight forward to set a proper value for real-time
-
Well I don't understand what's wrong in using it, all it does is give that queue a minium value all the time compared to link share which would give that queue the set bandwidth when it's back logged, and in the case of voip you need to have real-time bandwidth available as soon as the call starts so the signaling isn't delayed which would inturn increase call setup and RTP time. Even if there is no traffic for that queue which has real-time set that bandwidth isn't lost and still available for other queues.
In voip we at least know the packet size and what interval it's sent so I guess it's straight forward to set a proper value for real-time
Real-time's values are absolute (and limited to ~80% of total bandwidth). This is important when you are precisely allocating known traffic types like VOIP.
Link-share's values are not absolute, they are proportional (and can use 100% of total bandwidth, unlike real-time). This means accurate, completely predictable allocation is not possible with link-share. Link-share, as the name suggests, is meant only to share bandwidth. See this post for a clear example of link-share's proportional nature. (Pay attention to the first test, where my WAN bandwidth was correctly configured to 640Kbit.)
I would use real-time to improve/guarantee latency.
I would use link-share to control bandwidth or make latency worse, like you could allocate 5Mbit (m2) but also set m1=0Kbit & d=500, which would mean that traffic is allocated 5Mbit but packets can be delayed for up to 500ms, allowing other traffic to have better latency. The traffic will not be delayed unless there is other traffic. -
ok i understood realtime now, basically it can be used in cases where u know the type of traffic and its bitrate so then can reduce the latency on it.
one thing i didnt understand regarding the other link u gave me is do we set linkshare on the root queue or just the bandwdith
below is my current setup, can u tell me if its fine or simply point out whats wrong
WAN - bandwidth 100Mb
-qInternet - bandwidth 3000Kb - UL 3000Kb - LS 3000Kb - codel
–qACK - bandwidth 30% - LS 30% - codel - priority 6
--qOthersDefault - bandwidth 10% - LS 10% - codel - priority 4
--qP2P - bandwidth 5% - LS 5% - codel - priority 1 - default
--qVoIP - bandwidth 45% - RT 447Kb/5/224Kb - LS 45% - codel - priority 7
--qOthersHigh - bandwidth 10% - LS 10% - codel - priority 5LAN - bandwidth 100Mb
-qInternet - bandwidth 12000Kb - UL 12000Kb - LS 12000Kb - codel
--qACK - bandwidth 15% - LS 15% - codel - priority 6
--qOthersDefault - bandwidth 50% - LS 50% - codel - priority 4
--qP2P - bandwidth 5% - LS 5% - codel - priority 1 - default
--qVoIP - bandwidth 20% - RT 447Kb/5/224Kb - LS 20% - codel - priority 7
--qOthersHigh - bandwidth 10% - LS 10% - codel - priority 5 -
Well I don't understand what's wrong in using it, all it does is give that queue a minium value all the time compared to link share which would give that queue the set bandwidth when it's back logged, and in the case of voip you need to have real-time bandwidth available as soon as the call starts so the signaling isn't delayed which would inturn increase call setup and RTP time. Even if there is no traffic for that queue which has real-time set that bandwidth isn't lost and still available for other queues.
In voip we at least know the packet size and what interval it's sent so I guess it's straight forward to set a proper value for real-time
- Realtime always comes from the root queue, and can be greater than the parent queue's available bandwidth and even upperlimit, allowing you to starve your parent queue
- Realtime counts bandwidth consumed above your real-time negatively against you and will lower your bandwidth, violating the "minimum" exception. Rule of thumb, NEVER allow a queue with realtime to exceed it's allotted realtime bandwidth
- Link-share already gives me "immediate" bandwidth. I currently cannot measure a difference between my link being saturated or idle to within an accuracy or 0.01ms and 0.001% loss, and I only use linkshare.
Likshare has 99% of the benefit and none of the dangers. The primary benefit of realtime seems that it makes it simpler to not have to think about managing parent queues, except that simplicity comes at the cost of possibly harming the parent queues.
They added realtime for a reason, but without knowing more about the reason and implementation, I cannot empirically measure a benefit over linkshare. There may be some benefit for very slow links where the MTU is relatively large compared to the bandwidth