Upgrade HA cluster 2.4.4-p3 to 2.4.5 - persistent CARP maintenance mode causes gateway instability
-
To be clear you were seeing latency to the gateways (or their monitoring IPs) but not packet loss?
I would not expect CARP to be an issue here as the monitoring pings do not use the CARP IP.
Steve
-
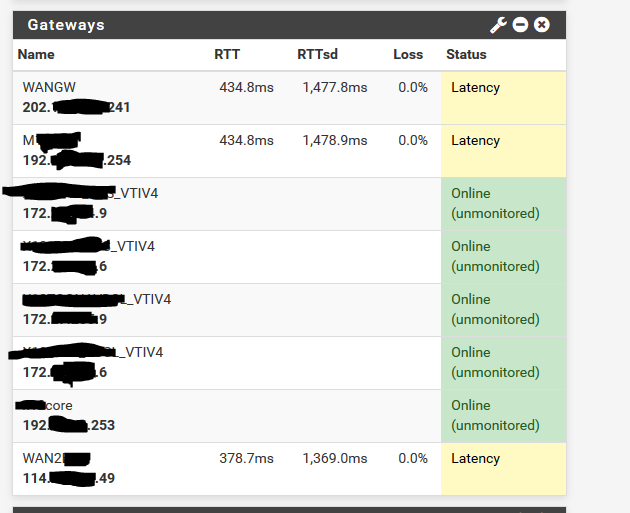
@stephenw10 I saw packet loss as well, from a server inside the network when the gateways were going nuts it too was dropping packets pinging the WAN gateway.
-
In the scenario I described, I would expect the CARP VIP might flip between the two but as Steve said, gateway monitoring should use the interface address/MAC.
Pings from the inside should egress from the CARP VIP though, which could have been bouncing between the nodes.
I tested this in a lab using VMs and none of the CARP VIPs went MASTER/MASTER or seemed to fight about it when I had maintenance mode enabled on both even though they were both at 1/254. But this is in a fairly pristine VM lab with essentially no latency between them. I can certainly see environmental factors yielding somewhat different results. Having both nodes at the same advbase/advskew should certainly be avoided. Again, just a theory.
-
I've just reverted some minor changes on that firewall cluster and the gateways issue is happening again, right now.
My new theory is a problem with an interface that;
- the parent interface is not enabled but has a specified MAC address
- multiple VLAN sub interfaces are attached to that parent interface
Because the gateway issue is happening right now, I cannot get a stable cluster and there doesn't seem to be any reason for it.
-
The parent interface of VLAN sub interfaces must be enabled.
Or, more accurately, there cannot be an interface assigned to the parent interface and not marked as enabled (which means explicitly disabled).
-
Edited my post above, CANNOT get a stable cluster.
Ok, I'm enabling Opt14 - the parent interface and see how that goes... Thanks.
-
Enabling the parnet interface and rebooting has not stopped the issue.
Ok, not really sure what's going on, but the gateways flop from just fine to all three gateways showing similar loss and latency (which is not true) and the firewall drops traffic.
I can't figure out what's doing it. It doesn't always happen at the same time for the primary and backup, but occasionally it does overlap
-
Packet Capture the icmp traffic and see where the fault actually lies.
If you do not trust the packet capture built into the pfSense software, capture on a mirror port on the outside switch.
If the echo request is being sent and the reply is missing or delayed, there is absolutely nothing the firewall can do about that.
-
@Derelict It's definitely firewall related somehow, because;
From an external IP address (from home) I have a continuous ping running to the main WAN gateway.
At the same time, I have a 2 other continuous pings running to the primary firewall WAN interface IP and the backup firewall WAN interface IP.What I see is;
-
The WAN gateway never drops a packet
-
Both firewalls "stutter" and drop traffic to their WAN interface and at that time, both firewalls "think" all 3 gateways simultaneously have high latency, etc, all the same time (not true) and it's far to coincidental.
Now, after going "nuts" for while it's finally settled down and both primary and the backup gateways are stable, but, somethings going on. This didn't happen with 2.4.4-p3 and now it is.
Something is going on that seems to be hiccuping the entire routing table / firewall after a reboot and this persists for a while. Could FRR be involved somehow? What processes cause the firewall to reload interfaces or the routing table?
-
-
This is an HA pair of XG-1537 with LAN on interface ix0 (10Gbe SFP+) and 3 VLAN sub interfaces on the LAN ix0.
WAN and other interfaces are on 1 Gbe copper UTP ports.
Interface igb3 (copper 1 Gbe) unused but also 3 x VLAN sub interfaces on igb3.
-
in quick testing here, it appears related to the pfblocker "maxmind GeoIP settings", either deleting the key or checking the box "disable maxmind csv database updates" makes the pfblocker pages respond near instantly again and gets rid of the long boot hang-time, which I'm assuming is breaking everything else and causing flapping in a loop as it keeps trying to reload it for high latency and other things!
I haven't tested further than that and cannot guarantee that's the only issue at hand, tested on minimal configured vm with nearly no traffic, but it slows it way down in many functions.
**NOTE, I'm not using carp here, but I had the same latency issues and everything flapping. -
I'm seeing the exact same behavior. When entering persistent CARP maintenance mode on primary, the secondary experiences high gateway latency for several seconds before calming down.
-
My suggestion would be to packet capture CARP packets simultaneously on both nodes on an interface you know will exhibit the behavior you are claiming (probably WAN) and see what happens there when you switch the primary to maintenance mode.
Wireshark groks CARP if you set protocol 112 to decode as CARP not VRRP.
When you place the MASTER node into maintenance mode it should immediately start sending heartbeats as advskew 254 instead of 0. When the BACKUP sees that it will say "Hey, 100 < 254 so I need to transition to MASTER and start advertising," and it will.
As soon as the MASTER sees the advertisement from the other node it will say "Hey, 254 < 100 so I need to transition to BACKUP and stop advertising," and it will.
This happens on all interfaces with CARP VIPs and they all do this independent from each other on each interface.
Almost all problems like this are caused by the Layer 2 gear doing something silly.
-
I'm now convinced that multiple things are going at the same time (like many complex problems)
-
The firewalls are a reboot are spiking with very high CPU and take quite a while to "settle down" and I see this gateway latency, loss of external ping to the firewall actual WAN interface IP and the dashboard GUI shows high CPU. Others are also reporting spiking CPU too.
-
Something seems to be going on with CARP. This cluster was working quite fine, same switches it's plugged into, but now I'm getting CARP issues, no VPN traffic until I power down the backup firewall, but, the back is reporting a CARP backup and the primary correctly reporting at CARP master. Perhaps it's ARP issues, not sure. As soon as I power off the backup, VPN's start passing passing traffic. If both firewalls are up, zero VPN traffic will pass. It's all very strange.
I have VPN tunnels over VTI routing done by OSPF using the FRR package and standard direct IPSEC tunnels and ALL of the VPN traffic doesn't work until the backup is powered off.
Sure, naughty layer 2 switches will cause all sorts of CARP issues, multi master, flip flop, etc, but I would most definitely had that happening before on 2.4.4-p3.
-
-
Well, anecdotally I just did a pair of 4860-1Us and didn't drop a ping to the CARP VIP from the outside going into or out of maintenance mode when upgrading the primary. Everything was just like it always is. Perfect.
This cluster isn't doing anything like yours is. Just basic firewalling and some OpenVPN.
You'll probably want to lab up your environment and see if you can identify what is failing.
-
Also check your outbound NAT and make sure you do not have a bad set of rules there. If you made manual outbound NAT rules with a source of 'any' that would interfere with traffic from the firewalls themselves (like the monitoring traffic).
Normally gateway monitoring would not be involved with CARP at all and would have nothing to do with failover.
Remember: Upvote with the 👍 button for any user/post you find to be helpful, informative, or deserving of recognition!
Need help fast? Netgate Global Support!
Do not Chat/PM for help!
-
@jimp There is one single NAT outbound, not on the WAN, on another interface that does have a source of any
Could this one rule, even though is only to operate on the "M..." interface be the issue?

-
@nzkiwi68 Hmmm, only 1 site with HA CARP has this, the other site with HA CARP doesn't have any outbound NAT at all with a source of "any", so, it might be adding to the issues but it's not "the" issue.
-
Both HA sites have clustered firewall and FRR and pfBlocker.
I did notice this morning, I updated pfBlocker on site 2 and entered the MaxMind License Key and pushed save.
The VPN to the remote site (over VTI and FRR) lost 4 pings for pushing save on pfBlocker!
-
Spent some considerable time on both HA sites last night.
SiteA, a pair of C2758
Site B, a pair of XG-1537Both sites have 10 GbE, with multi interfaces on the 10 GbE (as VLANs).
SiteA - main problem
Cannot have both firewalls up, primary and backup. If you do, zero VPN traffic passes over direct traditional site to site IPSEC or over the VTI routed FRR interfaces.
Left with the backup firewall powered off and the site is working.SiteB - main problem
Massive instability following a reboot, and it just carries on and on, with all three gateways on both the primary and secondary firewall going nuts. The firewalls stagger and drop packets. In the end left the backup firewall powered off and after about 10-15 minutes following a reboot, the gateways stop going offline and the firewall settles down and becomes stable.This is what I tried;
- reinstalled pfSense and all the packages
- pkg-static clean -ay
- pkg-static install -fy pkg pfSense-repo pfSense-upgrade
- pkg-static upgrade -f
-
Upgraded pfBlockerNG to pfBlockerNG-devel 2.2.5_30
-
Got the MaxMind license key sorted and made 100% sure that pfBlocker, could, and did download a GeoIP database on all four firewalls
-
pfBlockerNG sorted out any old feeds and made 100% sure all the data feeds getting downloaded are good.
-
Forced disable Kernel PTI and rebooted everything (made no difference)
-
Fixed the "any" source outbound NAT rule at SiteB, but, that too didn't help any.
-
Lots and lots of reboots
Could it be a 10 GbE issue?
I have also upgraded another HA cluster (not 10 GbE) it it went mostly ok.
The secondary upgraded perfectly, but, the primary when I went to upgrade suddenly reported that 2.4.4-p3 was a newer version than available.
I forced the upgrade on the primary and it upgraded fine. It's all running stable.What is the underlying 10 GbE driver in 2.4.5, has this changed?