Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5


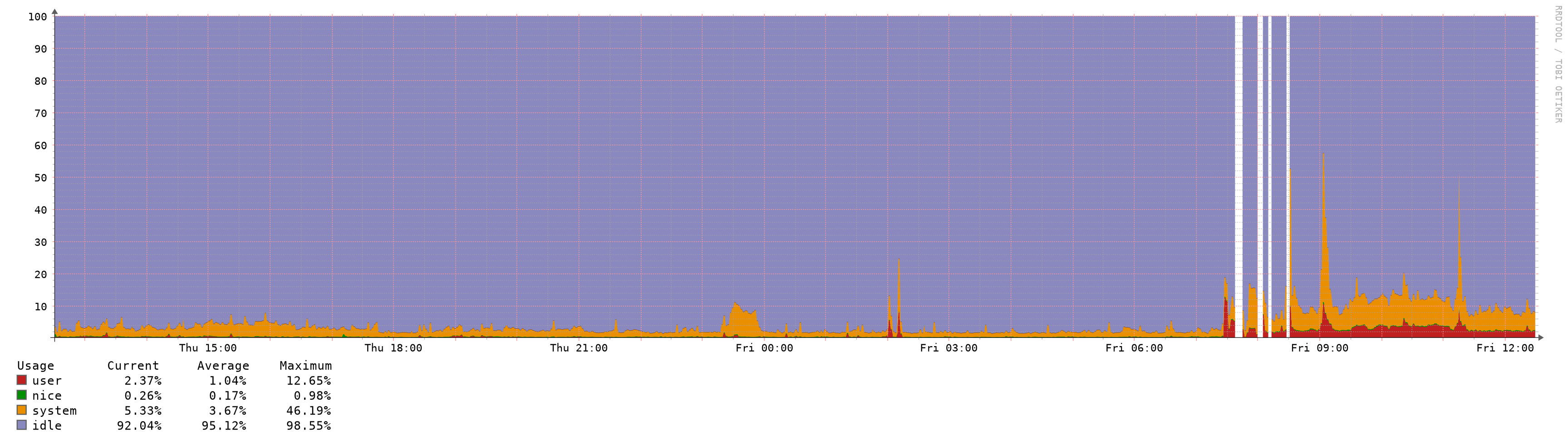
-
-
I'm experiencing the same issues as reported here under my post "Upgrade HA cluster 2.4.4-p3 to 2.4.5 - persistent CARP maintenance mode causes gateway instability" https://forum.netgate.com/topic/151698/upgrade-ha-cluster-2-4-4-p3-to-2-4-5-persistent-carp-maintenance-mode-causes-gateway-instability
2 sites now running really badly. Both sites running 10Gbase-SR with multi VLANs on the 10 Gb interfaces.
SiteA - main problem
Cannot have both firewalls up, primary and backup. If you do, zero VPN traffic passes over direct traditional site to site IPSEC or over the VTI routed FRR interfaces.
Left with the backup firewall powered off and the site is working.SiteB - main problem
Massive instability following a reboot, and it just carries on and on, with all three gateways on both the primary and secondary firewall going nuts. The firewalls stagger and drop packets. In the end left the backup firewall powered off and after about 10-15 minutes following a reboot, the gateways stop going offline and the firewall settles down and becomes stable. -
I turned off bogons. I deactivated pfblocker. I set the max table size to 60000. Rebooted. The reboot was quick again, like 2.4.4-p3. I ping6 google.com from a lan side device while doing a filter reload. The ping times don't change by any meaningful amount.
Makes me wonder if the pfctl fix was overlooked when the release was built?
Set max table size to 100000. Reboot. Reboot is longer again. Turn on pfblocker and some ip lists that add up to more than 60000 but less than 100000. Problem returns. Latency when reloading the filters. Bigger tables bigger problem.
Edited to add: the max table size doesn't appear to make any difference, other than setting a hard limit on table size. The actual size of the aliases/tables is what triggers the problem.
It sure looks to me that anything over that sixty some thousand mark causes the issue. I could be wrong, wouldn't be the first time, but this sure looks like the issue.
-
@jwj said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
I turned off bogons. I deactivated pfblocker. I set the max table size to 60000. Rebooted. The reboot was quick again, like 2.4.4-p3. I ping6 google.com from a lan side device while doing a filter reload. The ping times don't change by any meaningful amount.
Makes me wonder if the pfctl fix was overlooked when the release was built?
Set max table size to 100000. Reboot. Reboot is longer again. Turn on pfblocker and some ip lists that add up to more than 60000 but less than 100000. Problem returns. Latency when reloading the filters. Bigger tables bigger problem.
Edited to add: the max table size doesn't appear to make any difference, other than setting a hard limit on table size. The actual size of the aliases/tables is what triggers the problem.
It sure looks to me that anything over that sixty some thousand mark causes the issue. I could be wrong, wouldn't be the first time, but this sure looks like the issue.
The actual patch file can be accessed here: https://security.FreeBSD.org/patches/EN-20:04/pfctl.patch. What the patch does is remove the former arbitrary hardcoded limit of 65,535 (defined as PF_TABLES_MAX_REQUEST) and allows the use of a
sysctlparameter instead. Deeper research into the otherpfrelated source code would be required to determine if allowing that larger PF_TABLES_MAX_REQUEST value has an adverse impact.Looking a bit farther into what the patch actually does gives me a theory. The 65,535 number does not appear to be a limit on the number of IP addresses in a given table. It appears, instead, to be a limit on the number of tables or addresses you can add to the firewall during a single call to the corresponding
ioctl()function. That limit was formerly hardcoded to 65,535. Now, with the addition of asysctlvariable for customizing this limit, I can envision a scenario where with a very high value for this newsysctlvalue that you are overloading the otherpfareas. In particular, you would be requesting "too many tables and/or addresses in a singleioctl()call". So this may well be why lowering the value improves performance! You are no longer "overloading" the otherioctlroutines that are actually creating the tables or addresses in RAM. -
@getcom said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
The system is not accessible for minutes if anything changed.
As I added some new VLANs it never came back, I had to go onsite for a reboot which is not so easy at the moment because everybody is working from home.It happened again: I need a VLAN tag on one interface which was previously working as normal device.
- created a new VLAN
- changed name of parent device because name should be reused in the VLAN device
- changed static IPv4 to none
- press Save
- apply change
- bamm...connection interrupted, VPN stays connected, but without any traffic...it does not come back, VPN reconnection not working
- no chance to connect over the second gateway
- again I have to go onsite
This is a dual WAN/tier 1/tier 2 setup.
With 2.4.5 in a multiwan setup you cannot change anything on the interfaces without loosing the firewall.
This is a show blocker and loosing larger lists too.
Tomorrow I will drive to the customer and rollback to the 2.4.4-p3 release and the previous pfB until there is a fix available.. -
Seeing as this appears to affect so many people, is it worth writing up a decent Redmine ticket and submitting it?
-
@jwj said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
I turned off bogons. I deactivated pfblocker. I set the max table size to 60000. Rebooted. The reboot was quick again, like 2.4.4-p3. I ping6 google.com from a lan side device while doing a filter reload. The ping times don't change by any meaningful amount.
Makes me wonder if the pfctl fix was overlooked when the release was built?
Set max table size to 100000. Reboot. Reboot is longer again. Turn on pfblocker and some ip lists that add up to more than 60000 but less than 100000. Problem returns. Latency when reloading the filters. Bigger tables bigger problem.
Edited to add: the max table size doesn't appear to make any difference, other than setting a hard limit on table size. The actual size of the aliases/tables is what triggers the problem.
It sure looks to me that anything over that sixty some thousand mark causes the issue. I could be wrong, wouldn't be the first time, but this sure looks like the issue.
See my later edit to my post here: https://forum.netgate.com/topic/151690/increased-memory-and-cpu-spikes-causing-latency-outage-with-2-4-5/91. I have a theory why a value less that 65,536 seems to work better.
-
This post is deleted! -
@bmeeks Makes sense, since they're all loaded with one call. Total number of all tables would have to be under that number.
Also makes me take note of the fact that the "fork" of pfsense is still on 11.2 even as they have been more aggressive with pursuing freebsd upgrades historically.
-
@getcom Yep, that looks like my SiteA issue, if both firewalls are on, zero VPN traffic passes yet CARP is fine.
-
Power down the backup firewall and VPN traffic instantly starts passing, or
-
Power down the primary firewall and after failover stuff occurs, VPN traffic starts passing
-
-
@jwj said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
@bmeeks Makes sense, since they're all loaded with one call. Total number of all tables would have to be under that number.
Also makes me take note of the fact that the "fork" of pfsense is still on 11.2 even as they have been more aggressive with pursuing freebsd upgrades historically.
A possible solution for loading very large numbers of tables or IP addresses would be split them up into chunks of 65,000 or less and iterate through a loop making a series of
ioctl()function calls to create the tables or addresses. -
@bmeeks said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
@jwj said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
I turned off bogons. I deactivated pfblocker. I set the max table size to 60000. Rebooted. The reboot was quick again, like 2.4.4-p3. I ping6 google.com from a lan side device while doing a filter reload. The ping times don't change by any meaningful amount.
Makes me wonder if the pfctl fix was overlooked when the release was built?
Set max table size to 100000. Reboot. Reboot is longer again. Turn on pfblocker and some ip lists that add up to more than 60000 but less than 100000. Problem returns. Latency when reloading the filters. Bigger tables bigger problem.
Edited to add: the max table size doesn't appear to make any difference, other than setting a hard limit on table size. The actual size of the aliases/tables is what triggers the problem.
It sure looks to me that anything over that sixty some thousand mark causes the issue. I could be wrong, wouldn't be the first time, but this sure looks like the issue.
The actual patch file can be accessed here: https://security.FreeBSD.org/patches/EN-20:04/pfctl.patch. What the patch does is remove the former arbitrary hardcoded limit of 65,535 (defined as PF_TABLES_MAX_REQUEST) and allows the use of a
sysctlparameter instead. Deeper research into the otherpfrelated source code would be required to determine if allowing that larger PF_TABLES_MAX_REQUEST value has an adverse impact.Looking a bit farther into what the patch actually does gives me a theory. The 65,535 number does not appear to be a limit on the number of IP addresses in a given table. It appears, instead, to be a limit on the number of tables or addresses you can add to the firewall during a single call to the corresponding
ioctl()function. That limit was formerly hardcoded to 65,535. Now, with the addition of asysctlvariable for customizing this limit, I can envision a scenario where with a very high value for this newsysctlvalue that you are overloading the otherpfareas. In particular, you would be requesting "too many tables and/or addresses in a singleioctl()call". So this may well be why lowering the value improves performance! You are no longer "overloading" the otherioctlroutines that are actually creating the tables or addresses in RAM.This makes sense, but as a consequence, this then makes pfBlockerNG unusable or with larger values, pfSense itself makes it unusable. The choice is yours...if you currently need both, you will need a fix or rollback in the near future.
-
@getcom said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
@bmeeks said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
@jwj said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
I turned off bogons. I deactivated pfblocker. I set the max table size to 60000. Rebooted. The reboot was quick again, like 2.4.4-p3. I ping6 google.com from a lan side device while doing a filter reload. The ping times don't change by any meaningful amount.
Makes me wonder if the pfctl fix was overlooked when the release was built?
Set max table size to 100000. Reboot. Reboot is longer again. Turn on pfblocker and some ip lists that add up to more than 60000 but less than 100000. Problem returns. Latency when reloading the filters. Bigger tables bigger problem.
Edited to add: the max table size doesn't appear to make any difference, other than setting a hard limit on table size. The actual size of the aliases/tables is what triggers the problem.
It sure looks to me that anything over that sixty some thousand mark causes the issue. I could be wrong, wouldn't be the first time, but this sure looks like the issue.
The actual patch file can be accessed here: https://security.FreeBSD.org/patches/EN-20:04/pfctl.patch. What the patch does is remove the former arbitrary hardcoded limit of 65,535 (defined as PF_TABLES_MAX_REQUEST) and allows the use of a
sysctlparameter instead. Deeper research into the otherpfrelated source code would be required to determine if allowing that larger PF_TABLES_MAX_REQUEST value has an adverse impact.Looking a bit farther into what the patch actually does gives me a theory. The 65,535 number does not appear to be a limit on the number of IP addresses in a given table. It appears, instead, to be a limit on the number of tables or addresses you can add to the firewall during a single call to the corresponding
ioctl()function. That limit was formerly hardcoded to 65,535. Now, with the addition of asysctlvariable for customizing this limit, I can envision a scenario where with a very high value for this newsysctlvalue that you are overloading the otherpfareas. In particular, you would be requesting "too many tables and/or addresses in a singleioctl()call". So this may well be why lowering the value improves performance! You are no longer "overloading" the otherioctlroutines that are actually creating the tables or addresses in RAM.This makes sense, but as a consequence, this then makes pfBlockerNG unusable or with larger values, pfSense itself makes it unusable. The choice is yours...if you currently need both, you will need a fix or rollback in the near future.
I'm going to go back and research how this was coded in FreeBSD 11.2/RELEASE (which is what 2.4.4_p3 was based on). Will be interesting to see what may have changed from 11.2 to 11.3 of FreeBSD.
LATER EDIT: The PF_TABLES_MAX_REQUEST limit was a hardcoded value (a defined constant, actually) in the 11.2-RELEASE of FreeBSD. The recent FreeBSD 11.3/STABLE patch I referenced in an earlier post above is titled "Missing Tuneable", but I think it might really should have been titled "New Tuneable". Using "Missing" in the title could be taken by some to mean it was there previously in earlier versions and was erroneously removed and is being restored by the patch. Instead, it appears to me the patch added this system tuneable as a new feature and removed the former hardcoded limit. Anecdotal evidence from posters in this thread indicates allowing that former hard limit to now be essentially unlimited can produce undesirable side effects.
-
If I'm not mistaken that "tunable" wasn't in 2.4.4-p3 in System->Advanced->Firewall tab. Could someone double check that please.
So, in 2.4.4-p3 how did the big, ~110k, bogonsv6 table get loaded in 2.4.4-p3? If I set it to 60000 and then turn on bogons I get the can not allocate memory error and Alert.
-
@bmeeks said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
@getcom said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
@bmeeks said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
@jwj said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
I turned off bogons. I deactivated pfblocker. I set the max table size to 60000. Rebooted. The reboot was quick again, like 2.4.4-p3. I ping6 google.com from a lan side device while doing a filter reload. The ping times don't change by any meaningful amount.
Makes me wonder if the pfctl fix was overlooked when the release was built?
Set max table size to 100000. Reboot. Reboot is longer again. Turn on pfblocker and some ip lists that add up to more than 60000 but less than 100000. Problem returns. Latency when reloading the filters. Bigger tables bigger problem.
Edited to add: the max table size doesn't appear to make any difference, other than setting a hard limit on table size. The actual size of the aliases/tables is what triggers the problem.
It sure looks to me that anything over that sixty some thousand mark causes the issue. I could be wrong, wouldn't be the first time, but this sure looks like the issue.
The actual patch file can be accessed here: https://security.FreeBSD.org/patches/EN-20:04/pfctl.patch. What the patch does is remove the former arbitrary hardcoded limit of 65,535 (defined as PF_TABLES_MAX_REQUEST) and allows the use of a
sysctlparameter instead. Deeper research into the otherpfrelated source code would be required to determine if allowing that larger PF_TABLES_MAX_REQUEST value has an adverse impact.Looking a bit farther into what the patch actually does gives me a theory. The 65,535 number does not appear to be a limit on the number of IP addresses in a given table. It appears, instead, to be a limit on the number of tables or addresses you can add to the firewall during a single call to the corresponding
ioctl()function. That limit was formerly hardcoded to 65,535. Now, with the addition of asysctlvariable for customizing this limit, I can envision a scenario where with a very high value for this newsysctlvalue that you are overloading the otherpfareas. In particular, you would be requesting "too many tables and/or addresses in a singleioctl()call". So this may well be why lowering the value improves performance! You are no longer "overloading" the otherioctlroutines that are actually creating the tables or addresses in RAM.This makes sense, but as a consequence, this then makes pfBlockerNG unusable or with larger values, pfSense itself makes it unusable. The choice is yours...if you currently need both, you will need a fix or rollback in the near future.
I'm going to go back and research how this was coded in FreeBSD 11.2/RELEASE (which is what 2.4.4_p3 was based on). Will be interesting to see what may have changed from 11.2 to 11.3 of FreeBSD.
LATER EDIT: The PF_TABLES_MAX_REQUEST limit was a hardcoded value (a defined constant, actually) in the 11.2-RELEASE of FreeBSD. The recent FreeBSD 11.3/STABLE patch I referenced in an earlier post above is titled "Missing Tuneable", but I think it might really should have been titled "New Tuneable". Using "Missing" in the title could be taken by some to mean it was there previously in earlier versions and was erroneously removed and is being restored by the patch. Instead, it appears to me the patch added this system tuneable as a new feature and removed the former hardcoded limit. Anecdotal evidence from posters in this thread indicates allowing that former hard limit to now be essentially unlimited can produce undesirable side effects.
Agreed, I`m just thinking about if I should revert the patch and compile the "unleashed" FreeBSD 11.3 kernel for testing.
-
@bmeeks - I think you are on the right track with the ioctl() calls and how this might have changed going from 11.2 to 11.3. Since the value was 65535 before, how were large tables loaded in 11.2 and prior? Did the kernel allow multiple iotctl() call in succession or something similar? In 11.3 and beyond are we then potentially limited to making just one very large ioctl() call instead (by setting the new net.pf.request_maxcount tunable) as a security precaution?
Another related issue on Redmine:
https://redmine.pfsense.org/issues/9356
I guess my natural question is, would the optimal value be something close to the largest single table (e.g. IP alias / block list)? That assumes that it is a separate ioctl() call for loading each set of entries vs. trying to load everything with one call. Something interesting to try might be to leave the max table size (pfSense > Advanced > Firewall & NAT > Firewall Maximum Table Entries) unchanged at the default value (or whatever value it was adjusted to if default was too low) and then adjust just the net.pf.request_maxcount tunable to be a little larger than the single largest table (IP alias / block list), by setting it in loader.conf.local. Does anyone see any improvement in performance in such a scenario?
-
@tman222 said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
@bmeeks - I think you are on the right track with the ioctl() calls and how this might have changed going from 11.2 to 11.3. Since the value was 65535 before, how were large tables loaded in 11.2 and prior? Did the kernel allow multiple iotctl() call in succession or something similar? In 11.3 and beyond are we then potentially limited to making just one very large ioctl() call instead (by setting the new net.pf.request_maxcount tunable) as a security precaution?
Another related issue on Redmine:
https://redmine.pfsense.org/issues/9356
I guess my natural question is, would the optimal value be something close to the largest single table (e.g. IP alias / block list)? That assumes that it is a separate ioctl() call for loading each set of entries vs. trying to load everything with one call. Something interesting to try might be to leave the max table size (pfSense > Advanced > Firewall & NAT > Firewall Maximum Table Entries) unchanged at the default value (or whatever value it was adjusted to if default was too low) and then adjust just the net.pf.request_maxcount tunable to be a little larger than the single largest table (IP alias / block list), by setting it in loader.conf.local. Does anyone see any improvement in performance in such a scenario?
I'm not a kernel coding expert, so I don't know the answers to some of the questions here. I just did a quick scan of the 11.2 and 11.3 source files for some of the
pfmodules to see that the changes were in the listed patch. There may have been other changes to FreeBSD 11.3 that are not covered in that patch I linked above. If there were other changes, then those may also be in play. Really are going to have to wait on the pfSense developer team to figure it out. They have the required skills and knowledge. -
It probably makes no difference but i tried turning my default for Firewall Maximum Table Entries from 1,000,000 to the lowest acceptable value of 400,000. I rebooted and it wouldnt provide internet access so i returned the value back to default and reboot again, since then things have seemed more stable.. i will monitor.
-
Looking at the pfctl code. A "reload" is a flush followed by a load. It's the purge that violates the hard limit as best I can tell. Tables are loaded one by one. Any one table larger than the limit would error. Why the purge error is beyond my very rusty c skills. That's why the total items in all tables greater than the limit causes an error.
I'm not convinced that the limit has anything to do with the latency issue other than smaller total items in tables causes less latency. Other things have changed in the way that is implemented, again as best I can tell.
I'm entirely in over my head at this point and I don't have the time (days) to get back in the right mindset to figure out the code.
-
Did a few tests and found that setting the net.pf.request_maxcount value independent of Maximum Table Entries value made little difference - still seeing latencies and load spike briefly. I tried 200000 for request_maxcount (against a Max Table Entry value of 2 Million) as well as 131071 (to see if helped to be a power of 2). No dice unfortunately. As others have already alluded to, there seems to be something deeper here that changed.
