Upgrade HA cluster 2.4.4-p3 to 2.4.5 - persistent CARP maintenance mode causes gateway instability
-
My suggestion would be to packet capture CARP packets simultaneously on both nodes on an interface you know will exhibit the behavior you are claiming (probably WAN) and see what happens there when you switch the primary to maintenance mode.
Wireshark groks CARP if you set protocol 112 to decode as CARP not VRRP.
When you place the MASTER node into maintenance mode it should immediately start sending heartbeats as advskew 254 instead of 0. When the BACKUP sees that it will say "Hey, 100 < 254 so I need to transition to MASTER and start advertising," and it will.
As soon as the MASTER sees the advertisement from the other node it will say "Hey, 254 < 100 so I need to transition to BACKUP and stop advertising," and it will.
This happens on all interfaces with CARP VIPs and they all do this independent from each other on each interface.
Almost all problems like this are caused by the Layer 2 gear doing something silly.
-
I'm now convinced that multiple things are going at the same time (like many complex problems)
-
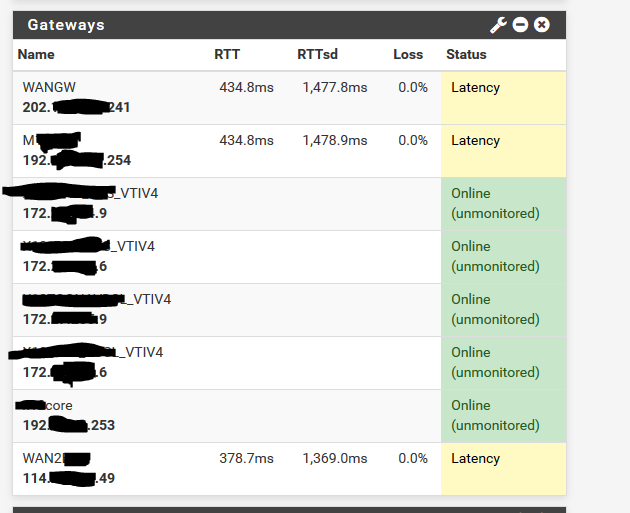
The firewalls are a reboot are spiking with very high CPU and take quite a while to "settle down" and I see this gateway latency, loss of external ping to the firewall actual WAN interface IP and the dashboard GUI shows high CPU. Others are also reporting spiking CPU too.
-
Something seems to be going on with CARP. This cluster was working quite fine, same switches it's plugged into, but now I'm getting CARP issues, no VPN traffic until I power down the backup firewall, but, the back is reporting a CARP backup and the primary correctly reporting at CARP master. Perhaps it's ARP issues, not sure. As soon as I power off the backup, VPN's start passing passing traffic. If both firewalls are up, zero VPN traffic will pass. It's all very strange.
I have VPN tunnels over VTI routing done by OSPF using the FRR package and standard direct IPSEC tunnels and ALL of the VPN traffic doesn't work until the backup is powered off.
Sure, naughty layer 2 switches will cause all sorts of CARP issues, multi master, flip flop, etc, but I would most definitely had that happening before on 2.4.4-p3.
-
-
Well, anecdotally I just did a pair of 4860-1Us and didn't drop a ping to the CARP VIP from the outside going into or out of maintenance mode when upgrading the primary. Everything was just like it always is. Perfect.
This cluster isn't doing anything like yours is. Just basic firewalling and some OpenVPN.
You'll probably want to lab up your environment and see if you can identify what is failing.
-
Also check your outbound NAT and make sure you do not have a bad set of rules there. If you made manual outbound NAT rules with a source of 'any' that would interfere with traffic from the firewalls themselves (like the monitoring traffic).
Normally gateway monitoring would not be involved with CARP at all and would have nothing to do with failover.
Remember: Upvote with the 👍 button for any user/post you find to be helpful, informative, or deserving of recognition!
Need help fast? Netgate Global Support!
Do not Chat/PM for help!
-
@jimp There is one single NAT outbound, not on the WAN, on another interface that does have a source of any
Could this one rule, even though is only to operate on the "M..." interface be the issue?

-
@nzkiwi68 Hmmm, only 1 site with HA CARP has this, the other site with HA CARP doesn't have any outbound NAT at all with a source of "any", so, it might be adding to the issues but it's not "the" issue.
-
Both HA sites have clustered firewall and FRR and pfBlocker.
I did notice this morning, I updated pfBlocker on site 2 and entered the MaxMind License Key and pushed save.
The VPN to the remote site (over VTI and FRR) lost 4 pings for pushing save on pfBlocker!
-
Spent some considerable time on both HA sites last night.
SiteA, a pair of C2758
Site B, a pair of XG-1537Both sites have 10 GbE, with multi interfaces on the 10 GbE (as VLANs).
SiteA - main problem
Cannot have both firewalls up, primary and backup. If you do, zero VPN traffic passes over direct traditional site to site IPSEC or over the VTI routed FRR interfaces.
Left with the backup firewall powered off and the site is working.SiteB - main problem
Massive instability following a reboot, and it just carries on and on, with all three gateways on both the primary and secondary firewall going nuts. The firewalls stagger and drop packets. In the end left the backup firewall powered off and after about 10-15 minutes following a reboot, the gateways stop going offline and the firewall settles down and becomes stable.This is what I tried;
- reinstalled pfSense and all the packages
- pkg-static clean -ay
- pkg-static install -fy pkg pfSense-repo pfSense-upgrade
- pkg-static upgrade -f
-
Upgraded pfBlockerNG to pfBlockerNG-devel 2.2.5_30
-
Got the MaxMind license key sorted and made 100% sure that pfBlocker, could, and did download a GeoIP database on all four firewalls
-
pfBlockerNG sorted out any old feeds and made 100% sure all the data feeds getting downloaded are good.
-
Forced disable Kernel PTI and rebooted everything (made no difference)
-
Fixed the "any" source outbound NAT rule at SiteB, but, that too didn't help any.
-
Lots and lots of reboots
Could it be a 10 GbE issue?
I have also upgraded another HA cluster (not 10 GbE) it it went mostly ok.
The secondary upgraded perfectly, but, the primary when I went to upgrade suddenly reported that 2.4.4-p3 was a newer version than available.
I forced the upgrade on the primary and it upgraded fine. It's all running stable.What is the underlying 10 GbE driver in 2.4.5, has this changed?
-
@nzkiwi68 said in Upgrade HA cluster 2.4.4-p3 to 2.4.5 - persistent CARP maintenance mode causes gateway instability:
SiteA - main problem
Cannot have both firewalls up, primary and backup. If you do, zero VPN traffic passes over direct traditional site to site IPSEC or over the VTI routed FRR interfaces.
Left with the backup firewall powered off and the site is working.Do you have FRR set to monitor the CARP VIP so that it only runs on whichever node is master? That sounds to me like FRR is running on both nodes and trying to route over both, perhaps confusing whatever is on the other end.
There isn't enough information to go on here though. At least need to know the status of the CARP VIPs, IPsec tunnels, and FRR on both nodes when it's experiencing the problem.
SiteB - main problem
Massive instability following a reboot, and it just carries on and on, with all three gateways on both the primary and secondary firewall going nuts. The firewalls stagger and drop packets. In the end left the backup firewall powered off and after about 10-15 minutes following a reboot, the gateways stop going offline and the firewall settles down and becomes stable.That sounds similar to an issue others have reported with large tables (usually from pfBlocker) on 2.4.5, where
pfctlends up using an inordinate amount of CPU time. Though most reports thus far have been confined to Hyper-V and Proxmox. There are other threads around for that which you might want to peruse to see if the other symptoms agree.Could it be a 10 GbE issue?
I have also upgraded another HA cluster (not 10 GbE) it it went mostly ok.
The secondary upgraded perfectly, but, the primary when I went to upgrade suddenly reported that 2.4.4-p3 was a newer version than available.
I forced the upgrade on the primary and it upgraded fine. It's all running stable.What is the underlying 10 GbE driver in 2.4.5, has this changed?
Doubtful. There may have been some driver updates along with the OS upgrade but it's unlikely to be related to that, given the described behavior.
Remember: Upvote with the 👍 button for any user/post you find to be helpful, informative, or deserving of recognition!
Need help fast? Netgate Global Support!
Do not Chat/PM for help!
-
@jimp said in Upgrade HA cluster 2.4.4-p3 to 2.4.5 - persistent CARP maintenance mode causes gateway instability:
Do you have FRR set to monitor the CARP VIP so that it only runs on whichever node is master? That sounds to me like FRR is running on both nodes and trying to route over both, perhaps confusing whatever is on the other end.
There isn't enough information to go on here though. At least need to know the status of the CARP VIPs, IPsec tunnels, and FRR on both nodes when it's experiencing the problem.
FRR is monitoring LAN CARP and is most certainly not running on both primary and backup firewalls. I though of that at the time and checked during my testing.
I also checked out CARP and CARP is not "flip flopping". Primary fw is master and backup fw is the standby for CARP.
Also site to site traditional IPSEC tunnels (not over VTI) also no longer pass traffic.That sounds similar to an issue others have reported with large tables (usually from pfBlocker) on 2.4.5, where
pfctlends up using an inordinate amount of CPU time. Though most reports thus far have been confined to Hyper-V and Proxmox. There are other threads around for that which you might want to peruse to see if the other symptoms agree.Yes, the others posts I'm reading also very similar, with gateways showing high latency, high CPU, etc. It also looks to be the same. I'm not having this occur on a third site HA site upgraded, but on 2 HA clusters, yes.
Also, I did see when I ran pftop pfctl chewing large CPU time. -
Just found this thread. I'm having the same issues since the upgrade of my (bare metal) cluster yesterday.
https://forum.netgate.com/topic/152185/carp-failures-after-upgrade-to-2-4-5/3 -
Probably not related to HA at all, from the looks of it.
Chattanooga, Tennessee, USA
A comprehensive network diagram is worth 10,000 words and 15 conference calls.
DO NOT set a source address/port in a port forward or firewall rule unless you KNOW you need it!
Do Not Chat For Help! NO_WAN_EGRESS(TM) -
Indeed, it is not related to HA or bare metal / VM. At first it looked so for me before finding all the threads and posts on the forum regarding the same problem after the upgrade to 2.4.5.
-
@Derelict I agree.
Initially it fooled me, because, it just "happened" to settle down as I exited CARP persistent maintenance mode, but, now, like all the other cases, I'm convinced there is a serious underlying issue with 2.4.5 that causes high CPU usage and the gateway latency and dropping packets.
It's NOT an HA or CARP issue.