Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5


-
Later today I will downgrade from 2.4.5 to 2.4.4-p3. Is there anything anyone would like me to do before I downgrade and after to help mitigate your latency issues? I suppose this is an opportunity to compare like configurations other than the pfsense version.
-
@muppet said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
Redmine
I don't see a Redmine ticket yet, please submit one.
-
FYI: I just opened a Netgate ticket and reported the situation with 2.4.5
The workaround for now:
- disable "Block bogon networks" on WAN interfaces
- In System => Advanced => Firewall & NAT: set "Firewall Maximum Table Entries" to a value < 65535
With this changes the pfBlockerNG-devel cannot load lists anymore with an overall value > "Firewall Maximum Table Entries" - count of custom rule sets.
Unasigned or reserved IP addresses will not be blocked anymore.
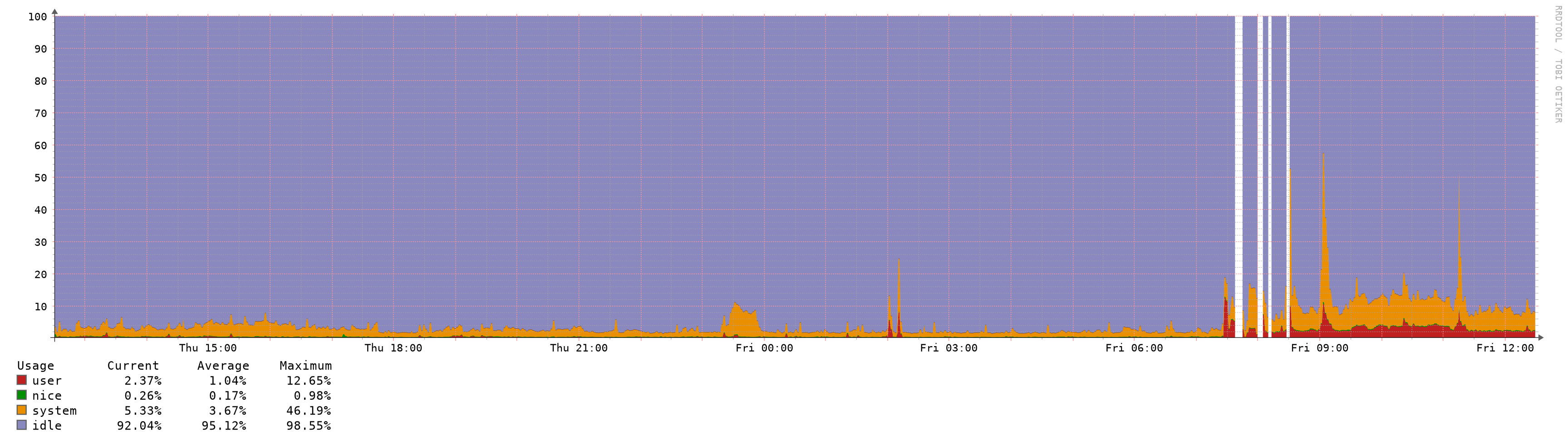
CPU usage stays at ~1-5% without spikes.
Memory usage in my setup is 20-30% higher compared to 2.4.4-P3, but the spikes are gone.I will test now the behavior of changing rule sets and interfaces/VLAN setups.
-
I've reverted to 2.4.4-p3. I have tried but can not get it to exhibit the same behavior. I can add or remove very large tables and there is no meaningful latency or any unexpected cpu spikes.
What conclusion can be drawn from this adventure? To be honest I'm not entirely sure. Only an understanding of how pf has changed in the upgrade from 11.2 Release to 11.3 Stable will reveal what is going on.
For now I'm happy to just get on with things...
-
@jwj said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
Only an understanding of how pf has changed in the upgrade from 11.2 Release to 11.3 Stable will reveal what is going on.
For now I'm happy to just get on with things...
I reverted to 2.4.4 p3 but discovered that I still couldn't run Snort due to the changes recently made, so I went back to 2.4.5. I have Snort and pfBlockerNG-devel installed.
I ended up playing with the settings in System, Advanced, Power Savings. Not sure what the defaults were, but with PowerD enabled and AC Power, Battery Power, and Unknown Power set to Hiadaptive, Adaptive, Adaptive respectively, I don't see the CPU spikes anymore but I do still see increases in latency but they are less than 100ms on my pfSense box. Out of curiosity, does anyone know what Unknown power is? The setting for that one seemed to be the most sensitive with respect to CPU increases.
I'm tired of messing with this and ready to move on. I can live with the way my box is working at the present time.
Hopefully they can find what the issue is and fix it before we get to pfSense version 2.5 which is based on FreeBSD 12.x. Who knows what new problems may arise then...
Edit: The reason I got to playing with the Power Savings settings was because the CPU temperature was running around 42 to 50 degrees C with 2.4.5 installed and it normally runs around 22 to 25 degrees C with 2.4.4 p3 installed. With the Power Savings settings that I specified above, the temperature is around 25 degrees C now.
-
@jdeloach I don't recall the exact thread or procedure but you can get snort/suricata to work on 2.4.4-p3 by changing the repository to point to 2.4.4 and installing the "older" versions. Search around a bit if you think you'll have another go at downgrading.
I'm back on 2.4.5 also, it's fine if you just don't touch anything that causes the thing to want to reload the filters... Life goes on such as it is...
-
How to change to the 2.4.4 repository is described here . According to Stephenw10 the old Versions are still online, but I haven't tried it on a fresh install yet.
-
@Artes said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
How to change to the 2.4.4 repository is described here . According to Stephenw10 the old Versions are still online, but I haven't tried it on a fresh install yet.
I did what stephenw10 posted, I thought, but obviously I did something wrong and didn't see the older version of Snort. It was my first time to try to roll back. It's no big deal as I got the temperature issue with the CPU worked out so it's not running so hot. If this comes up again I'll give it another try. Anyways, at the moment I'm happy with the way it's working with the new version of pfSense.
-
@getcom Can you post here you ticket number so we can follow it on redmine?
I had a quick look and couldn't see it...
Thanks!!
-
Opening a support ticket and a bug report on redmine are two different things. Given the situation and the priorities Netgate has to support their paying customer base I wouldn't hold your breath for a resolution and patch anytime soon. As they (Netgate) said in the release announcement upgrading was not recommended for some customers at this time.
https://www.netgate.com/blog/pfsense-2-4-5-release-now-available.html
-
@tman222 said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
net.pf.request_maxcount
changing "Firewall Maximum Table Entries" in the gui, is just directly changing the "net.pf.request_maxcount" under syctl output.
you either have to reboot or I think status > filter reload, will update it. but maybe not! -
I also experienced this problem with high CPU usage from 2.4.5 in Hyper-V. The only way to fix it was to limit the virtual CPUs to one. I'm now running my own newly built pfSense box, so the problem is now moot for me.
-
My internet connection was nearly unusable for some days... It was really hard (or let's say: impossible) to have voice- and video calls at my home office. And then search for hours for the root cause after the day of work. Since I had some more problems with my network and changed parts of the equipment (10Gbit Switch and network cards) I didn't think about pfSense being the root cause.
For me it helped to stop the dpinger-service, but the workaround in Post #901871 works much better, since it doesn't stop the advantages of my multi WAN setup (loadbalancing and failover).I opened an issue on Redmine: #10414
At the moment they can't reproduce it. But this thread looks like several installations are affected. Maybe you can also help to find out steps to definitely reproduce the issue so they can do further tests? -
I'm also affected.
HW: SG-4860If the process pfctl has a 100% peak, ping latency is also very high.
Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=1125ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=1613ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=1190ms TTL=55 Reply from 9.9.9.9: bytes=32 time=5ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 Reply from 9.9.9.9: bytes=32 time=2ms TTL=55 -
Very similar CPU performance issues with another topic on Hyper-V as a VM which I have contributed to. As others have said, it is definitely not a PFBLOCKER issue.
Hyper-V performance
https://forum.netgate.com/topic/149595/2-4-5-a-20200110-1421-and-earlier-high-cpu-usage-from-pfctl/10Physical server performance
https://forum.netgate.com/topic/151819/2-4-5-high-latency-and-packet-loss-not-in-a-vm/2Some users have reported assigning only 1 CPU within the VM resolves the problem but this would suggest there is a multi core issue with the build at this time?
Has anyone had any feedback from Netgate as yet?
-
I have wrote a few days ago that i am ok with pfBlocker and pfSense 2.45 version, but today i reboot pfSense VM and problem is returns, BUT, i have found temporary CRAZY solution, just need to manually update feeds of pfblocker and problem is gone (CPU and RAM is much more using, than on 2.4.4 but it not 100% freeze every few seconds). 2.4.5 is problematic version, and it's more complicated with enabled pfBocker on fresh boot...
-
@Gektor said in Increased Memory and CPU Spikes (causing latency/outage) with 2.4.5:
I have wrote a few days ago that i am ok with pfBlocker and pfSense 2.45 version, but today i reboot pfSense VM and problem is returns, BUT, i have found temporary CRAZY solution, just need to manually update feeds of pfblocker and problem is gone (CPU and RAM is much more using, than on 2.4.4 but it not 100% freeze every few seconds). 2.4.5 is problematic version, and it's more complicated with enabled pfBocker on fresh boot...
I do that after every update to be sure that everything is working. In my case this was not changing anything.
My previous post related to the "Firewall Maximum Table Entries" and downsizing the value below 65535 does not change the behavior if something has to be changed.
It is not only this pfctl patch which is causing the issues. We have check more patches. -
@cuco I have updated #10414 offering to help them reproduce the issue, which I can reproduce at will.
-
Same issue here on a bare metal cluster. Upgraded to 2.4.5 and the CPU spikes and unstable HA. After each change on the primary node, the secondary node becomes master for a second or two and then becomes a slave again. Why? Because the primary node doesn't send a heartbeat ping for 5 seconds while the filter reloads.
It removed the values of "Firewall Maximum States" and "Firewall Maximum Table Entries" so that they fall back to the default (for me states = 3236000 and table entries = 200000). After a reload of the filter all went back to normal (also after a reboot of both machines all still good).
I now have pfBlocker removed and block bogon tables unchecked (if I check them, I have to increase table entries to 400000). When I increase to 500000 and enable blogon networks on the secondary node: the problem returns. When I uncheck bogon networks and remove the value of 'table entries' again: problem solved.
So for now what works for me as a temporary solution: don't increase table entries but use default values, don't enable bogon networks and don't enable pfBlocker.
A view of the CPU spikes on the master node. Around 9am I moved the table entries value to the default.
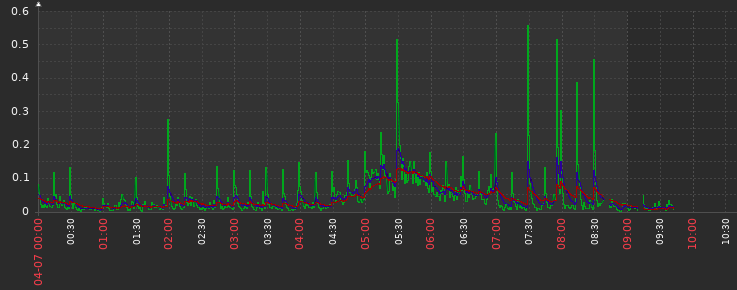
How that node looked the last days (updated on april 6 around 10am):

-
Any news on this?
The whole thing is a serious desaster and no minor problem in my opinion.