Average writes to Disk
-
This is the SMART Test output from one of my boxes, APU2 Board with 16GB SSD...
241 Lifetime_Writes_GiB shows GB count written.... -> 4176.278 TB???? no way....SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000a 100 100 000 Old_age Always - 0 9 Power_On_Hours 0x0012 100 100 000 Old_age Always - 8694 12 Power_Cycle_Count 0x0012 100 100 000 Old_age Always - 42 168 SATA_Phy_Error_Count 0x0012 100 100 000 Old_age Always - 0 170 Bad_Blk_Ct_Erl/Lat 0x0013 100 100 010 Pre-fail Always - 0/20 173 MaxAvgErase_Ct 0x0000 100 100 000 Old_age Offline - 385 (Average 775) 192 Unsafe_Shutdown_Count 0x0012 100 100 000 Old_age Always - 4 194 Temperature_Celsius 0x0023 070 070 000 Pre-fail Always - 30 196 Not_In_Use 0x0000 100 100 000 Old_age Offline - 0 218 CRC_Error_Count 0x0000 100 100 000 Old_age Offline - 0 241 Lifetime_Writes_GiB 0x0012 100 100 000 Old_age Always - 4176278 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended captive Completed without error 00% 8694 - # 2 Short captive Completed without error 00% 8694 - # 3 Short offline Completed without error 00% 2557 - SMART Selective self-test log data structure revision number 0 Note: revision number not 1 implies that no selective self-test has ever been run SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay. -
@tohil said in Average writes to Disk:
241 Lifetime_Writes_GiB shows GB count written.... -> 4176.278 TB???? no way....
Smart is always Device specific - you have to dig for the correct interpretation of those values ... 4 PB is heavy and I don't believe it even its theoretically possible ...
-
@fireodo said in Average writes to Disk:
@tomashk said in Average writes to Disk:
zfs set sync=disabled zroot
Is this command permanent or has it to be made on each reboot? Thanks
It is permanent. You can check if it is set with this command:
zfs get -r sync zroot(it will show information for whole zfs file system)
and you can revert it with this command if I remember correctly:
zfs set sync=enabled zroot -
Thank you! Those settings do the trick! Maybe @jimp can take a look on this thread and maybe its something for the next version ...?
Regards,
fireodoKettop Mi4300YL CPU: i5-4300Y @ 1.60GHz RAM: 8GB Ethernet Ports: 4
SSD: SanDisk pSSD-S2 16GB (ZFS) WiFi: WLE200NX
pfsense 2.8.1 CE
Packages: Apcupsd, Cron, Iftop, Iperf, LCDproc, Nmap, pfBlockerNG, RRD_Summary, Shellcmd, Snort, Speedtest, System_Patches. -
Yeah I would hope that the default settings used for zfs install wouldn't be a determinant to life of SSD or eMMC would have issues with total writes as well..
I don't know of a way to check what eMMC reports for total life write, etc.
-
@johnpoz said in Average writes to Disk:
I don't know of a way to check what eMMC reports for total life write, etc.
As I don't have any device here with eMMC (OK, except my Phone but that's out of my research-reach :-D ) I cannot say anything about it. Is it smart capable? Documentation says its a kind of predecesor of SD-Card ...
-
If for whatever reason the onboard eMMC died, I know you can add a msata to it.. So that would always be an option.
But would be curious if there is a way to get info from it on total data written, etc.
-
There's no way to get write data from eMMC AFAIK.
-
@fireodo said in Average writes to Disk:
Thank you! Those settings do the trick! Maybe @jimp can take a look on this thread and maybe its something for the next version ...?
I changed it a few years ago because I was annoyed by constant blinking of the LED when SSD was working :). But I used those options having very basic knowledge of zfs. Now I know it a little bit better so I understand what are downsides of this configuration. And I guess it is far from being optimal. Also I'm not sure if setting it by default on zfs for next version would be good. There are too many variables for different devices to be sure if this is completely safe. But fortunately it easy to restore configuration if something is broken and I don't store important information on pfsense's drive.
-
@tomashk said in Average writes to Disk:
Also I'm not sure if setting it by default on zfs for next version would be good.
Thats why I thought it would be good if some of the developer with far more knowledge about that ZFS take a look at this situation and maybe find a more robust solution...
-
@stephenw10 if zfs does, at least in its default config cause more writes to the eMMC or SSD.. You mentioned something about
There was a bug at one time that was not mounting root as noatime
That increased drive writes in normal use, is there some change to the zfs config that might be prudent to change.. As being mentioned in this thread for example
System -> Advanced -> System Tunables - set vfs.zfs.txg.timeout to 180
I mean writing 20GB a day for not really doing anything does seem like a lot, its possible there is some error in the math, or interpretation of the info that leads to an exaggerated understanding off the amount written.. The amount of life time writes to eMMC is a concern if zfs is in fact drastically increasing the amount of data written..
An intelligent man is sometimes forced to be drunk to spend time with his fools
If you get confused: Listen to the Music Play
Please don't Chat/PM me for help, unless mod related
SG-4860 25.07.1 | Lab VMs 2.8.1, 25.07.1 -
@johnpoz said in Average writes to Disk:
I mean writing 20GB a day for not really doing anything does seem like a lot, its possible there is some error in the math
This cannot be excludet. I was searching and testing this matter aprox a week ago before I came to the forum with it.
Kettop Mi4300YL CPU: i5-4300Y @ 1.60GHz RAM: 8GB Ethernet Ports: 4
SSD: SanDisk pSSD-S2 16GB (ZFS) WiFi: WLE200NX
pfsense 2.8.1 CE
Packages: Apcupsd, Cron, Iftop, Iperf, LCDproc, Nmap, pfBlockerNG, RRD_Summary, Shellcmd, Snort, Speedtest, System_Patches. -
I always disable DNS Reply Logging, check if that helps..

-
One thing I've noticed here is that having the dashboard open with the system information widget up will cause significantly more disk writes. Something that can easily happen when you are testing:
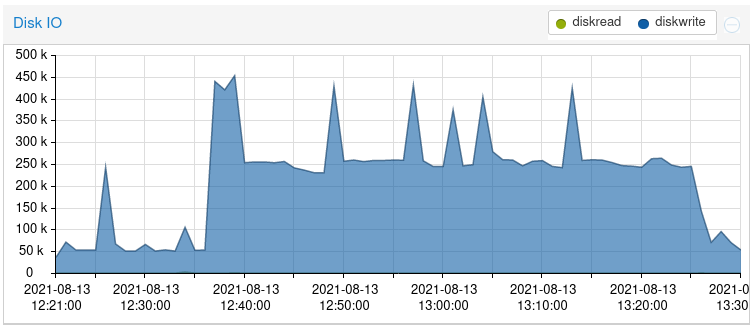
That's a 21.09 snapshot running ZFS.
Steve
-
@fireodo said in Average writes to Disk:
This cannot be exclude.
I didn't mean to seem like not trusting of your work, and how much data is being written. But I personally have a lack of understanding in enough depth to correlate what the output iostat shows and actual writes to the disk amounts too.
Even with smart data from SSD, these numbers can also be misinterpreted because the values shown in smart have to take into account the specific maker of the ssd, etc.. I have seen this myself on my nas, where is reports an insane amount of data written to the nvme cache. But if you do the math a bit different, then the numbers seem more sane..
Either way I feel your information does warrant further look into validation of how much actual data is being written.. Since if 20GB a day is being written, and you have small sized ssd or eMMC which do have limited amount of write for their life, the typical life could be shortened by a drastic amount..
edit: @stephenw10 that looks interesting.. Must be something new for 21.09, I do not see any sort of graph available in 21.05.1... Or is that something outside of pfsense, like vm host where you have pfsense running?
edit2: Would help if could pull such info from eMMC... From the limited amount looking into I have done so far, the mmc-util can be installed on pfsense.. but have not been able to glean any info from /dev/da0 using it.. Only thing I have managed to do is get this using smartctl
[21.05.1-RELEASE][admin@sg4860.local.lan]/: smartctl -d scsi -x /dev/da0 smartctl 7.2 2020-12-30 r5155 [FreeBSD 12.2-STABLE amd64] (local build) Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Vendor: Generic Product: Ultra HS-COMBO Revision: 1.98 User Capacity: 30,601,641,984 bytes [30.6 GB] Logical block size: 512 bytes >> Terminate command early due to bad response to IEC mode pageI would of hoped this would of provided some info like the smart info you can get from a ssd
[21.05.1-RELEASE][admin@sg4860.local.lan]/: mmc --help Usage: mmc extcsd read <device> Print extcsd data from <device>.But just asking for status returns
[21.05.1-RELEASE][admin@sg4860.local.lan]/: mmc status get /dev/da0 open: Operation not permittedAn intelligent man is sometimes forced to be drunk to spend time with his fools
If you get confused: Listen to the Music Play
Please don't Chat/PM me for help, unless mod related
SG-4860 25.07.1 | Lab VMs 2.8.1, 25.07.1 -
IMO, disabling sync means you put yourself in danger of not having a consistent filesystem on disk which is critical for a firewall. If sync is disabled it means ZFS lies to the OS about what has been committed to disk.
Maybe it could be disabled for just the log dataset, or
/tmpfor example, or something along those lines, but disabling it globally is a bad idea. Even log data could be critical in a situation that needs debugging.If it bugs you enough to disable it on a disk, I'd say that's a personal choice, but I'm not sure I could get behind recommending anyone do that by default.
I've been running ZFS on SSDs for years and so far haven't killed a disk with it.
Remember: Upvote with the 👍 button for any user/post you find to be helpful, informative, or deserving of recognition!
Need help fast? Netgate Global Support!
Do not Chat/PM for help!
-
ZFS is designed to be a highly resilient file system. That means it keeps multiple copies of some things spread around the disk to hopefully be able to patch around a future bad block. It also, by default, writes information to the disk every 5 seconds. Some of its behavior can be tweaked. Do a Google search for "zfs topology" and you will find some technical details.
Just my own WAG (wild-as*** guess), but ZFS is going to be much chattier writing to disk than a less robust file system such as UFS. It has to constantly flush things out to physical media, and write critical file system details to multiple locations. If you tweak it harshly and drastically alter the intervals between these disk writes, you may save your SSD from premature wear, but you will be losing some of the resiliency that drove you to install ZFS in the first place. This is because some critical piece of file allocation table update was still in RAM when the system crashed or lost power and had not gotten written to disk yet.
This may be a classic case of you can't "have your cake and eat it, too" ...
 .
. -
@jimp said in Average writes to Disk:
IMO, disabling sync means you put yourself in danger of not having a consistent filesystem on disk which is critical for a firewall. If sync is disabled it means ZFS lies to the OS about what has been committed to disk.
Maybe it could be disabled for just the log dataset, or /tmp for example, or something along those lines, but disabling it globally is a bad idea. Even log data could be critical in a situation that needs debugging.
If it bugs you enough to disable it on a disk, I'd say that's a personal choice, but I'm not sure I could get behind recommending anyone do that by default.Thanks for looking in and clarifying things! Much appreciated!
Regards,
fireodo -
@jimp said in Average writes to Disk:
I've been running ZFS on SSDs for years and so far haven't killed a disk with it.
Exactly - you would think if zfs drastically shortened the life of SSD, or eMMC there would be loads of info about it all over.
There has always been since the early days of SSD info about limiting unwarranted writes to lengthen in an attempt to extend their life.. But I have a few SSDs that have constant writes for years and have never had any issues.. Used SSD in my esxi host will multiple VMS on it - with constant writes.. The box is still working, ssd still works and looks healthy, etc.
Much of the info you can find is just not good on such details.. Even with small SSDs with 60TBW, that is a lot of freaking writes.. So even with large amounts per day you should have no problems out living the useful life of the device.. Sure not going to be using that ssd 20 years from now, etc..
But if in fact some 20GB of data is being written and you have some small say 4GB eMMC.. such amount of write could burn through its life in an amount in an amount of time that is shorter than what you would expect for the life of the device.. Could it not? I am just not clear on if the interpretation of what iostat shows actually works out to amount of data actually written. If so I would think there would be a more than few people bringing up that their 2GB or 4GB eMMC on their device has died, etc..
-
For my system I took these settings (considering also jimps opinion)
zfs set sync=disabled zroot/tmp (pfSense/tmp on new 2.5.2 install)
zfs set sync=standard zroot/var (pfSense/var)and fine tuning: vfs.zfs.txg.timeout=120
I hope to get a balance between security and the write intensity to disk. I will report in the next 24 hours.
Thank you all for your Patience and help!
fireodo