New TCP congestion algorithm - BBR
-
The patch may be for Linux, but the algorithm could be implemented by anyone, assuming they don't lay claim to a patent.
It wouldn't help a router/firewall, but it would be useful for any servers.
-
I saw this post over on HackerNews and thought you might be interested, Harvy. The poster is a FreeBSD kernel dev. https://news.ycombinator.com/item?id=12681091
(Regarding TCP improvements in FreeBSD 11.)
It matters most for people doing 10-100gbps throughput, CPU usage will be lower and more stable in all cases though.
There has been a lot of improvement to many network card drivers in 11, and I am helping to push/fund the final integration of Matt Macy's "iflib" for the common intel em/igb/ixgbe drivers.
There are a lot of goodput improvements coming soon, which will affect all TCP users. I had Matt Macy upgrade TCP CUBIC to match 2016 RFC and most Linux behaviors (HyStart). Hiren Panchasara has been working full time for almost 2 years to address many other goodput and correctness issues in the TCP stack. Some of these are in 11, but the majority will hit in 11.1.
Another company is working on the recently announced BBR congestion control from Google and a TCP stack with RACK/PRR https://wiki.freebsd.org/DevSummit/201606/Transport. The end result of all this will be a more tightly integrated and coherent TCP implementation, which should make FreeBSD have the best network stack again in 2017 after falling behind for a while. -
How start the BBR
-
Fujitsu Labors was doing it in 2013 too, perhaps not the same but 30 times faster then the ordinary TCP
protocol we are using until today, Fujitsu Laboratories Ltd. - Press release -
@BlueKobold:
Fujitsu Labors was doing it in 2013 too, perhaps not the same but 30 times faster then the ordinary TCP
protocol we are using until today, Fujitsu Laboratories Ltd. - Press releaseThat's an interesting read, but it seems Fujitsu's tech was a tunneling tech that wrapped around TCP between two tunneled networks and acted similar to a TCP accelerator by reducing ACK latency, compensating for packetloss, and allowing smaller transmission windowed TCP connections from being limited to bandwidth by high RTTs.
-
now i using BBR in unbuntu17.10, it is work now.
i want to change the pfsense to BBR or cubic, it is can't change.
i add cc_cubic_load="YES" in loader.conf and net.inet.tcp.cc.algorithm=cubic in sysctl.conf
Shell Output - sysctl net.inet.tcp.cc.available show net.inet.tcp.cc.available: newreno
still can't change it.
who know how change it?
-
I know I'm late to the party, but I actually found out about this algorithm just recently as I was searching for network settings to tune for Linux hosts.
Ran some tests using TCP BBR and I have to say I'm quite impressed with the performance:
-
Performing a local test using Flent between two 10Gbit Linux hosts using TCP BRR and sitting on different network segments (i.e. the test was done across the firewall) resulted in more stable data transfer and lower latency. Using TCP - BBR I had no trouble pushing 14 - 16Gbit of traffic across the pfSense firewall (Flent is a bi-directional test) with latencies on average between 1 - 2 ms during the test. Using the prior (default) TCP congestion algorithm (Cubic) data transfer was less stable (more variability in bandwidth) and total bandwidth was a little lower as well. Latencies were closer to the 3 - 6ms range.
-
Performing a WAN test I also got better upload performance than before. I have a 1Gbit symmetric Fiber connection and using TCP BBR I saw higher upload speeds, especially over longer distances (e.g. between East Coast and West Coast). I use fq_codel to manage WAN traffic since I have 10Gbit hosts sending traffic into a 1Gbit interface -- it all seems to work quite well still with TCP BBR enabled on the hosts.
-
-
@yon Google is working on BBR2. Lots of improvements in making it both more friendly and more resilient.
-
@harvy66 said in New TCP congestion algorithm - BBR:
@yon Google is working on BBR2. Lots of improvements in making it both more friendly and more resilient.
Hi @Harvy66 - any ideas what specifically they are working on changing/updating? Thanks in advance.
-
how i get the new BBR in freebsd or linux?
-
@tman222 said in New TCP congestion algorithm - BBR:
I know I'm late to the party, but I actually found out about this algorithm just recently as I was searching for network settings to tune for Linux hosts.
Ran some tests using TCP BBR and I have to say I'm quite impressed with the performance:
-
Performing a local test using Flent between two 10Gbit Linux hosts using TCP BRR and sitting on different network segments (i.e. the test was done across the firewall) resulted in more stable data transfer and lower latency. Using TCP - BBR I had no trouble pushing 14 - 16Gbit of traffic across the pfSense firewall (Flent is a bi-directional test) with latencies on average between 1 - 2 ms during the test. Using the prior (default) TCP congestion algorithm (Cubic) data transfer was less stable (more variability in bandwidth) and total bandwidth was a little lower as well. Latencies were closer to the 3 - 6ms range.
-
Performing a WAN test I also got better upload performance than before. I have a 1Gbit symmetric Fiber connection and using TCP BBR I saw higher upload speeds, especially over longer distances (e.g. between East Coast and West Coast). I use fq_codel to manage WAN traffic since I have 10Gbit hosts sending traffic into a 1Gbit interface -- it all seems to work quite well still with TCP BBR enabled on the hosts.
How You install it on pfSense ?
Please describe in details, if possible.
-
-
@tman222 said in New TCP congestion algorithm - BBR:
Using the prior (default) TCP congestion algorithm (Cubic) data transfer was less stable (more variability in bandwidth) and total bandwidth was a little lower as well. Latencies were closer to the 3 - 6ms range.
Cubic - is VERY old CC algorithm, and outdated even in 2012...
Better to compare QUIC and BBR2/BBR.
BTW, BBR (and BBR2) more pushed by Netflix (due they need effective netflow with less latency for their server farms), and QUIC are more pushed by Google (due they need effective netflow with less latency & big quantity of packet drops because last 8-9 years traffic goes more “mobile”).
-
https://github.com/netflix/tcplog_dumper
-
@yon-0 said in New TCP congestion algorithm - BBR:
https://github.com/netflix/tcplog_dumper
If I understand the page You previously post (translate from China to Eng) there are only one way - rcompiling the kernel.
Using a FreeBSD -head (r363032 minimum, to have the extra TCP stack headers installed), compile a new kernel with BBR and extra TCP stack enabled:And because pfSense CE open source, I able doing that, but in TNSR - definitely no.
Am I right ?
—
CLOSE SKY FOR UKRAINE https://youtu.be/_tU1i8VAdCo !
Help Ukraine to resist, save civilians people’s lives !
(Take an active part in public protests, push on Your country’s politics, congressmans, mass media, leaders of opinion.) -
This post is deleted! -
Compile New Kernel Now we are ready to compile the new kernel to activate the TCP BBR. Create a new file RACK (you can use any name you want) in the folder /usr/src/sys/amd64/conf/RACK. Inside the file will need to add the options for TCP BBR and the file should look like this: $ cat /usr/src/sys/amd64/conf/RACK include GENERIC ident RACK makeoptions WITH_EXTRA_TCP_STACKS=1 options RATELIMIT options TCPHPTS Next step is to run the following commands (in order) to compile the kernel (this step will take a while) 1) make -j 16 KERNCONF=RACK buildkernel 2) make installkernel KERNCONF=RACK KODIR=/boot/kernel.rack 3) reboot -k kernel.rack The old kernel will be available but with the name "kernel.old". After rebooting, will use the new kernel because of the command "reboot -k kernel.rack", however to make it persistent will require to adjust couple of files (will explain later in this article). Once you have built, installed and rebooted to the new kernel we need to load the RACK kernel module tcp_bbr.ko: kldload /boot/kernel.rack/tcp_bbr.ko Now you should see the new module in the functions_available report, by typing the command: sysctl net.inet.tcp.functions_available The output will be: net.inet.tcp.functions_available Stack D Alias PCB count freebsd * freebsd 3 bbr bbr 0: Now will require to change the default to TCP BBR: sysctl net.inet.tcp.functions_default=bbr and the output will be: net.inet.tcp.functions_default: freebsd -> bbr root@freebsd # sysctl net.inet.tcp.functions_available net.inet.tcp.functions_available: Stack D Alias PCB count freebsd freebsd 3 bbr * bbr 0k After rebooting, will use the old Kernel, but we can make it persistent. Modify the Loader To force FreeBSD to use the new Kernel after rebooting, will require to adjust 3 files: /etc/sysctl.conf /etc/rc.conf /boot/loader.conf Inside /etc/sysctl.conf we can also add command for optimisation, including the command to enable TCP BBR as a default congestion control function. The file should looks like this: $ cat /etc/sysctl.conf # $FreeBSD$ # # This file is read when going to multi-user and its contents piped thru # ``sysctl'' to adjust kernel values. ``man 5 sysctl.conf'' for details. # # Uncomment this to prevent users from seeing information about processes that # are being run under another UID. #security.bsd.see_other_uids=0 # set to at least 16MB for 10GE hosts kern.ipc.maxsockbuf=16777216 # set autotuning maximum to at least 16MB too net.inet.tcp.sendbuf_max=16777216 net.inet.tcp.recvbuf_max=16777216 # enable send/recv autotuning net.inet.tcp.sendbuf_auto=1 net.inet.tcp.recvbuf_auto=1 # increase autotuning step size net.inet.tcp.sendbuf_inc=16384 net.inet.tcp.recvbuf_inc=524288 # set this on test/measurement hosts net.inet.tcp.hostcache.expire=1 # Set congestion control algorithm to Cubic or HTCP # Make sure the module is loaded at boot time - check loader.conf # net.inet.tcp.cc.algorithm=cubic net.inet.tcp.cc.algorithm=htcp net.inet.tcp.functions_default=bbr net.inet.tcp.functions_inherit_listen_socket_stack=0 The 2nd change is to add the following line inside /etc/rc.conf: kld_list="/boot/kernel.rack/tcp_bbr.ko" and finally the last change is to modify the /boot/loader.conf file, should look like this: $ cat /boot/loader.conf ### Basic configuration options ############################ kernel="kernel.rack" # /boot sub-directory containing kernel and modules bootfile="kernel.rack" # Kernel name (possibly absolute path) module_path="/boot/kernel.rack" # Set the module search path cc_htcp_load="YES" After modifying the files, reboot the server and you should see the HTCP algorithm as well as TCP BBR function as the chosen options: $ sudo sysctl net.inet.tcp.cc.available net.inet.tcp.cc.available: CCmod D PCB count newreno 0 htcp * 6 $ sudo sysctl net.inet.tcp.functions_available net.inet.tcp.functions_available: Stack D Alias PCB count freebsd freebsd 5 bbr * bbr 1 -
https://www.linkedin.com/pulse/frebsd-13-tcp-bbr-congestion-control-andrew-antonopoulos/?trk=articles_directory
who try install bbr in freebsd?
-
In addition, I recently tested using the Quic protocol for network transmission, and the vpn test is more than 5-10 times faster than the existing wireguard. Especially in the case of a bad network environment, it is more obvious.
I think pfsense should be more aggressive in innovating technology instead of using very, very old technology. It always feels outdated. -
Hi Guys
Late to the party, I just wrote an article on how to build custom pfSense bbr kernel.
You can try out my custom build kernel at your own risk.
Here is the link:
https://github.com/mikehu404/pfsense-bbr -
@mikehu44444 said in New TCP congestion algorithm - BBR:
https://github.com/mikehu404/pfsense-bbr
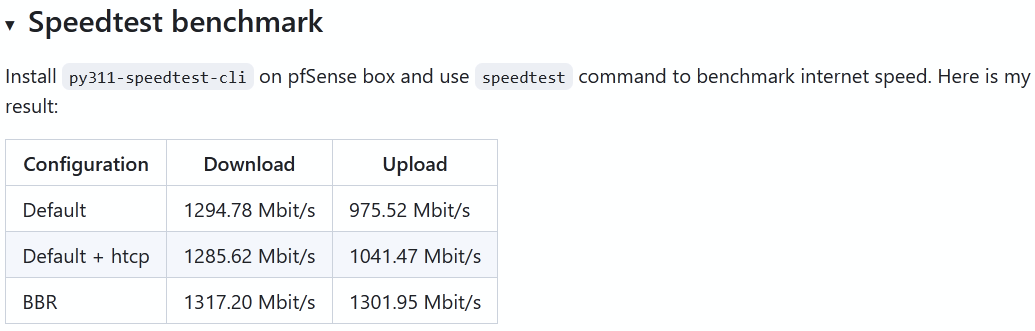
Great work!
In reality, there are very few situations where pfSense acts as a client or a server.
It would be nice to re-test the pfSense client's speed, but not pfSense itself.
I don't think we will see any difference. The tuning that is applicable should be applied to all FreeBSD kernels during the test.