New TCP congestion algorithm - BBR
-
@Sergei_Shablovsky said in New TCP congestion algorithm - BBR:
Please explain details how You make working QUIC congestion control in TCP/IP stack in pfSense CE 2.7.X ?
It is possible to use QUIC for VPN, but currently QUIC is mainly use for http3.
You should ask how to enable QUIC with haproxy on pfSense, as this is the right question.@Sergei_Shablovsky said in New TCP congestion algorithm - BBR:
options TCP_BBR # Enable BBR
options TCP_BBR2 # Enable BBR2To enable bbr on freebsd.
I don't think BBR2 is available on freebsd yet.@Sergei_Shablovsky said in New TCP congestion algorithm - BBR:
options TCP_CDG # Enable CDG
cc/cc_cdg ## Enable CDG@Sergei_Shablovsky said in New TCP congestion algorithm - BBR:
net.inet.tcp.cc.algorithm=bbr2
must be appended to /boot/loader.conf.You should add this option via System Tunables
@Sergei_Shablovsky said in New TCP congestion algorithm - BBR:
Is it possible to make this also in Plus version of pfSense?
Although I never use the plus version before, but I believe the CE version and the plus version shares the same kernel, since you can just upgrade to plus version from CE version.
-
@mikehu44444 said in New TCP congestion algorithm - BBR:
but I believe the CE version and the plus version shares the same kernel, since you can just upgrade to plus version from CE version.
No. Plus is freebsd 15 and CE is 14, so kernels are different.
Actually you cant just modify plus version, because it is not free and not open source.
https://www.netgate.com/support/frequently-asked-questions-pfsense-plus#:~:text=Is%20pfSense%20Plus%20software%20open,Routing%2C%20and%20of%20course%20FreeBSD. -
@mikehu44444 said in New TCP congestion algorithm - BBR:
To enable bbr on freebsd.
So, is this mean that this script would be working in pfSense CE version ?
#!/bin/sh # Function to log messages log_message() { echo "$1" logger -p local0.notice "RACK Enabler: $1" } # Function to restart networking services restart_networking() { log_message "Restarting networking services..." service netif restart && service routing restart log_message "Networking services restarted" } # Function to display countdown display_countdown() { local duration="$1" local message="$2" echo -n "$message" while [ "$duration" -gt 0 ]; do echo -n "$duration " sleep 1 duration=$((duration - 1)) done echo "0" } # Check if running as root if [ "$(id -u)" != "0" ]; then log_message "This script must be run as root" exit 1 fi # Step 1: Check available TCP stacks log_message "Checking available TCP stacks..." available_stacks=$(sysctl net.inet.tcp.functions_available) log_message "$available_stacks" if ! echo "$available_stacks" | grep -q "rack"; then log_message "RACK stack not available. Please ensure you're running FreeBSD 14 or higher." exit 1 fi # Step 2: Load the RACK kernel module if ! kldstat | grep -q tcp_rack; then log_message "Loading RACK kernel module..." if kldload tcp_rack; then log_message "RACK kernel module loaded successfully" else log_message "Failed to load RACK kernel module" exit 1 fi else log_message "RACK kernel module is already loaded" fi # Step 3: Set RACK as the default TCP stack log_message "Setting RACK as the default TCP stack..." if sysctl net.inet.tcp.functions_default=rack; then log_message "RACK set as default TCP stack" else log_message "Failed to set RACK as default TCP stack" exit 1 fi # Step 4: Verify the change log_message "Verifying the change..." new_default=$(sysctl net.inet.tcp.functions_available | grep -E "rack.*\*") log_message "New default TCP stack: $new_default" # Step 5: Make the change persistent log_message "Making the change persistent..." if grep -q "net.inet.tcp.functions_default=rack" /etc/sysctl.conf; then log_message "Persistent setting already exists in /etc/sysctl.conf" else echo "net.inet.tcp.functions_default=rack" >> /etc/sysctl.conf log_message "Added persistent setting to /etc/sysctl.conf" fi # Step 6: Suggest restart log_message "RACK has been enabled and set as the default TCP stack" log_message "Networking services will be restarted automatically unless cancelled" # Step 7: Wait for ESC key and restart networking if not pressed log_message "Press ESC within 10 seconds to cancel automatic restart of networking services..." if [ -t 0 ]; then # Check if script is running in a terminal # Start countdown in background display_countdown 10 "Time remaining: " & countdown_pid=$! # Wait for user input read -t 10 -n 1 key # Kill countdown process kill $countdown_pid 2>/dev/null if [ "$key" = $'\e' ]; then echo # Move to a new line after countdown log_message "ESC key pressed. Skipping network restart." else echo # Move to a new line after countdown restart_networking fi else log_message "Not running in an interactive terminal. Proceeding with network restart." restart_networking fi log_message "RACK enabler script completed successfully" -
@Sergei_Shablovsky said in New TCP congestion algorithm - BBR:
net.inet.tcp.functions_available
It would only work if the tcp_rack kernel module is present and it isn't included in 2.7.2.
Additionally pfSense use the gui system tunables instead of /etc/sysctl.conf so the persistent part would not work.
-
@stephenw10 said in New TCP congestion algorithm - BBR:
@Sergei_Shablovsky said in New TCP congestion algorithm - BBR:
net.inet.tcp.functions_available
It would only work if the tcp_rack kernel module is present and it isn't included in 2.7.2.
So, if I understand You correctly, we return to old queston "when Netgate compile kernel with CDG/BBR2/RACK/QUICK support for pfSense+ or CE ??!!!!" or workaround "how to recompile kernel with CDG/BBR2/RACK/QUICK support for pfSense CE" (as we see discussion abowe) ?
Additionally pfSense use the gui system tunables instead of /etc/sysctl.conf so the persistent part would not work.
No problem to modifying script to editing "system tunables" in config.xml ...:)
-
@w0w said in New TCP congestion algorithm - BBR:
@mikehu44444 said in New TCP congestion algorithm - BBR:
https://github.com/mikehu404/pfsense-bbr
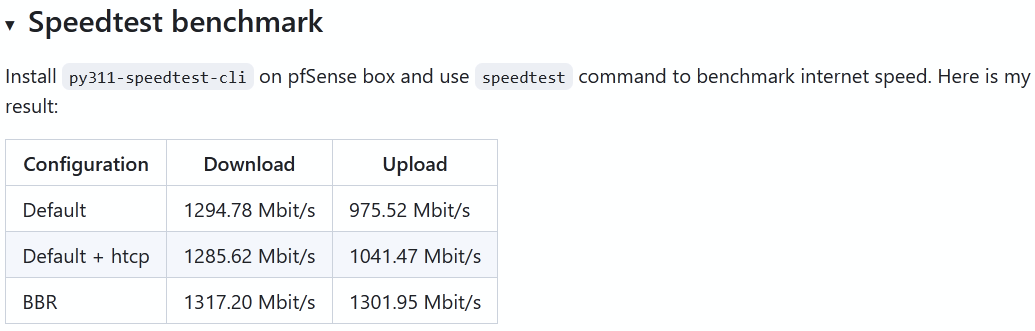
Great work!
In reality, there are very few situations where pfSense acts as a client or a server.
It would be nice to re-test the pfSense client's speed, but not pfSense itself.
I don't think we will see any difference. The tuning that is applicable should be applied to all FreeBSD kernels during the test.With all appreciation to Your R&D, but let's to make some small note that may explain so big difference in numbers:
-
Mostly, ISPs installing own separate Speedtest OOKLA server on their infrastructure (and sometime even routing all requests from users to own Seedtest server, if this possible) : because OOKLA Speedtest app (desktop, mobile or webapp) AUTOMATICALLY using the nearest Speedtest's server (selected by lowest lathency) and 90%+ OF USERS NOT CHOOSING OTHER TEST SERVER IN OTHER LOCATION in app settings, - THE SPEEDTEST's RESULTS WOULD BE a little INCORRECT (5-25%) from real;
-
Mostly, ISP making their own "Speedtest page" where in code it's own Speedtest's server are HARDLY PRE-SELECTED. So, the situation goes to item.1 above;
-
Because A LOT OF ISPs (in some US states (probably in a middle states or with less developed infrastucture states, in Western Europe, in MIddle Asia this percentage may be 80-95%) using core network equipment, and equipment on aggregate levels with simply OLD CONGESTION CONTROL (CC) like Tahoe, Reno, Westwood+, CUBIC, etc., this mean THE MODERN TCP/IP CC protocols WOULD BE ALWAYS WINNER IN REAL LIFE (probably NEXT 10-20years, up to the time, when MOST of equipment/os switch to modern TCP/IP CC, and then would be "next round").
-
So, ordinary unmodified FreeBSD v.14+ by default using CUBIC as the default TCP/IP CC algorithm. Previous versions used New Reno. However, FreeBSD supports a number of other choices.
P.S.
May be this is one of reasons why Netgate till now not including Speedtest (even as separate pkg) in CE or + version.
Because very hardly to explain to ordinary users "what this pesky Speedtest measurements mean".BUT I HOPE one day I have a time to make separate pkg for Speedtest, FAST, Librespeed and even smokeping to giving ability to all pfSense users flawlessly using this tools to measure WAN UPLINKs on initial pfSense setup at home or small office.
-
-
@Sergei_Shablovsky said in New TCP congestion algorithm - BBR:
May be this is one of reasons why Netgate till now not including Speedtest (even as separate pkg) in CE or + version.
Because very hardly to explain to ordinary users "what this pesky Speedtest measurements mean".
BUT I HOPE one day I have a time to make separate pkg for Speedtest, FAST, Librespeed and even smokeping to giving ability to all pfSense users flawlessly using this tools to measure WAN UPLINKs on initial pfSense setup at home or small office.Honestly, I don't know why WAN speeds need to be measured on the firewall. By its nature, pfSense is simply not designed for this, as it works in a pass-through mode, meaning the maximum speeds should be on the client PCs connected to pfSense, not the other way around. Of course, it would be great if the speeds were the same on both pfSense and the clients, but as I understand it, this is impossible and unnecessary overall.
As for BBR, I would conduct tests if I had the opportunity, but I'm not sure if it would offer any advantages in my configuration. Probably none.
I can't recall the exact reason why Netgate didn't even consider including this algorithm and compiling the necessary options in the kernel. Compatibility and stability, obviously, @stephenw10?
-
@w0w said in New TCP congestion algorithm - BBR:
@Sergei_Shablovsky said in New TCP congestion algorithm - BBR:
May be this is one of reasons why Netgate till now not including Speedtest (even as separate pkg) in CE or + version.
Because very hardly to explain to ordinary users "what this pesky Speedtest measurements mean".
BUT I HOPE one day I have a time to make separate pkg for Speedtest, FAST, Librespeed and even smokeping to giving ability to all pfSense users flawlessly using this tools to measure WAN UPLINKs on initial pfSense setup at home or small office.Honestly, I don't know why WAN speeds need to be measured on the firewall. By its nature, pfSense is simply not designed for this, as it works in a pass-through mode, meaning the maximum speeds should be on the client PCs connected to pfSense, not the other way around.
Honestly, please spend 20min for searching in this pfSense Users Forum how much times users asking again and again "why my speeed to internet so low..."! A LOT OF!
Of course, part of this questions are from newbies which not read pfSense docs carefully and because of this make some misconfiguration OR just not really understanding all ground aspects about Networking.But there are also a common PURE QUESTION: what is my UPLINK TO ISP SPEED?
@w0w, please told me, are YOU PERSONALLY not interested in to know WHAT IS REAL WAN UPLINK SPEED (i mean between Your WAN Eth port and Your ISP)?
Because may be something in ISP's hardware, cables, aggregate switches, etc. that IN YOUR CERTAIN CASE GIVE YOU LESS BANDWIDTH that you pay for?And how for example personally You measure UPLINK TO ISP BANDWITH ?
Of course, it would be great if the speeds were the same on both pfSense and the clients, but as I understand it, this is impossible and unnecessary overall.
I not wrote about that. (That's not possible at all technically for a couple of reasons.)
As for BBR, I would conduct tests if I had the opportunity, but I'm not sure if it would offer any advantages in my configuration. Probably none.
Thank You so much! I'm waiting ! :)
I can't recall the exact reason why Netgate didn't even consider including this algorithm and compiling the necessary options in the kernel. Compatibility and stability, obviously, @stephenw10?
Stability? Compability ? Please explain, what You are about in details?
CDG, BBR/BBR2, RACK, QUIC working last 5 years with no any issues in a lot of facilities and DC.And I still thinking the reason why Netgate not including the CDG, BBR/BBR2, RACK, QUIC support in their pfSense only because not making R&D bot on simulated (TRex or similar utility) and a real traffic and obtain a certain dataset that quickly pushing it to take a decision which CC to compile in kernel.
This decision also follow to impact on next 2(two) IMPORTANT items:
-
Is current Netgate applience (not U-rack, small models for home / small office use) able to working well with may be increased workload on NICs controllers and whole CPU/RAM/bus ?
Changing the factory's production process in current economical situation may be not good way. And of coarse this is INVESTING IN A FUTURE with NO IMMEDIATELY REVENUE RISE UP. -
Because "Each congestion control algorithm is implemented as a loadable kernel module." would be a some sort of problem to EXPLAIN TO END USERS which option (CDG, BBR/BBR2, RACK, QUIC) make by default and (more important!) WHY USER MAY NEED TOCHANGE this DEFAULT CC.
As we here all see, 90%+ of network appliances users in SOHO become less and less educated, and even more and more stupid...
P.S.
Of what we are speaking? Look at reality: this tread are in "Off-topic section", other threads related to CC on this pfSense Users Forum are with significant small views.
At the same moment this 'small' changing the CC in pfSense may increasing bandwith utilisation, speed, etc. to + 10-30% (depend on setup and use case). -
-
Good evening everyone
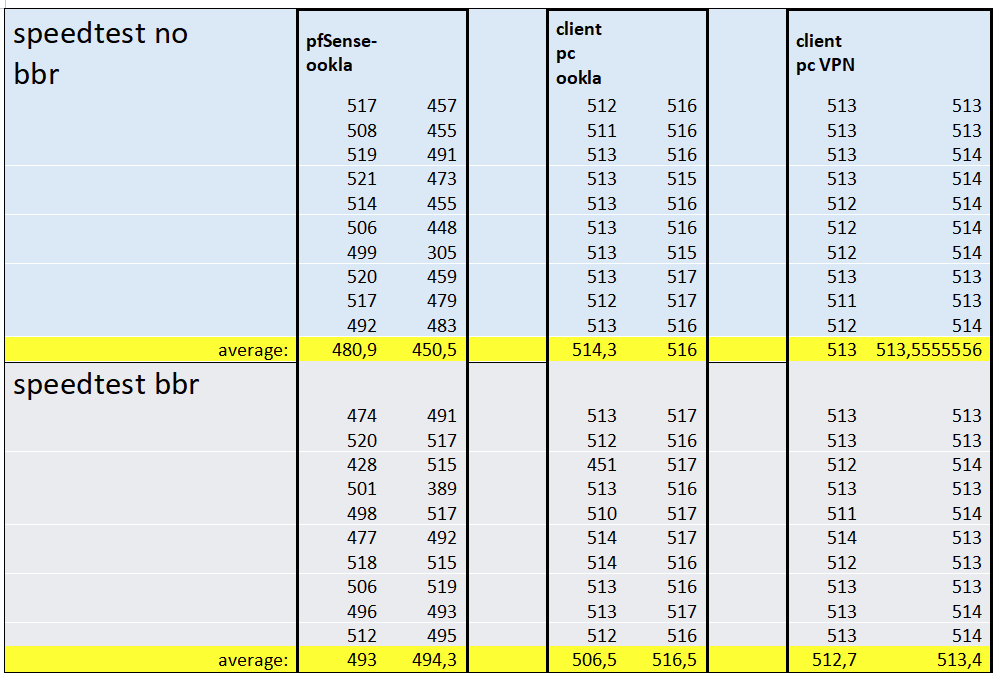
Did quick BBR and no-BBR tests, and the theory is absolutely confirmed. Even if you want to test your ISP speed with BBR on pfSense, you might not get the full speed, but it will be very close to it.
There's no benefit on client PC when BBR is active. The difference is statistically negligible, even with a small sample size. -
@mikehu44444
So, what is about tests? -
@w0w
Why You using SOHO SpeedSest (especially in situation where in 2024 must of all ISPs have OWN SPEEDTEST SERVER node installed or CREATE A HI-SPEED/LOW LATENCY routing by policies especially for impressing own clients) instead of TRex (best choice), Fast (more usable for ordinary peoples) or iperf3 (in multi-thread mode, not good and more synthetic tool, but anyway better than Ookla Speedtest) ?????!To be serious, only testing by TRex (both way - from outside and from inside) GIVE YOU ADEQUATE PICTURE OF what happened with Your REAL TRAFFIC.
Not like You type ‘speedtest’ in CLI and have right decisions. Not at all!
P.S.
You even not indicated which parameters of BBR2 on client node, which QoS on router (in the middle, if You use it), which parameters of BBR2 on pfSense’s BSD node, and CE or Plus version of pfSense You use for this tests! -
@Sergei_Shablovsky
Create your own software build, test everything you need, and ensure it meets your requirements. It's beyond my capabilities, and I don't want to waste my time anymore. -
It’s definitely not MY personal requirements, this affect EACH pfSense user. More (in case office/small/middle company in US/Europe ) or less (web surfer from Tanzania, techno-geek at home network or DevOps at home).
But making decision based on wrong testing strategy and wrong instruments -> wrong way and certainly wasting time and effort.
Agree?Before in this thread You wrote:
——
RACK and BBR will mostly have an effect running on endpoints, like streaming servers or tunnel endpoints. Since pfSense is a firewall there are not so many situations when BBR or RACK will give any benefit,
——
TCP congestion control is managed by endpoints (sever and/or client e.g. web browser and web server), so anything not placed on the firewall is not using cognestion control, like newreno or any other.
Endpoint means that firewall iself is an endpoint, then congestion control is applied, otherwise all other traffic is just passed to upstream/downstream interface.
——-I friendly pointing You that this is not correct and by saying “TCP congestion control is managed by endpoints” You show that You not deeply understanding how exactly QUIC (and so-called HTTP/3) working and how overall CC strategy, BSD/NIX TCP stack parameters, NICs parameters, ISPs switches on aggregate levels, ISPs routers (with sophisticated routing policies, shapers and limiters) on core level routers impact on packets flow back and forth between external users and Your application’s server.
And now You make that decision based on … ordinary SpeedTest ? Really wrong way to comparing CCs!
P.S.
Do You know that small (but important) example: Your server’s ~72Mb/s with 1ms ping -> after 1% PL (packet loss) on a user’s “last mile” BECOME ~54Mb/s with 4ms ping ~> after +100ms RTT added by “fat magistral” BECOME 5,7Mb/s with 104ms ping.Only 1% of PL and +100 RTT make Your “magic server’s 72Mb/s” to “5,7Mb/s” !
Imagine, what happened with 2-3% PL and 80-120 RTT ?
This all about YOU NEED MAKE PROFESSIONAL-GRADE MEASUREMENTS WITH RIGHT TOOLS !