Traffic shaping with cake and pie? :)
-
Is PFSense going to use the cake/pie qos methods in near future releases?
-
Pie is nearly identical to Codel for characteristics. The main difference is pie plays better with hardware implementations. You can already use Codel.
Cake is not actually done yet and their mailing list is caught in a "Can we fix some edge cases or do we need to revert some much wanted but not required features to go back to a stable version". They really want it to work for almost everything, from 100Gb datacenter connections to high latency satellite connections. It's a hard problem.
fq_Codel is coming to dummynet soon
 . I think it's at least in FreeBSD head. This won't work with normal interface shaping, but it should with the limiters and I would hope someone could port to ALTQ. fq_Codel actually works nearly as good as Cake or better* for most normal bandwidths and latencies.
. I think it's at least in FreeBSD head. This won't work with normal interface shaping, but it should with the limiters and I would hope someone could port to ALTQ. fq_Codel actually works nearly as good as Cake or better* for most normal bandwidths and latencies.
*Only because of some of those edge cases caused by most recent features.The other thing to remember about Cake is it's a shaper plus AQM. Not a huge different for most users, but it would most likely not be used with HFSC or any of the other shapers that allow you to control bandwidth allocations.
-
I only researched PIE for a short time but I think CoDel is better. Actually, just disregard that statement…
Anyway, the same project that is bringing codel & fq-codel to FreeBSD has also implemented PIE & FQ-PIE. http://caia.swin.edu.au/freebsd/aqm/
It'll be neat to test all these algorithms in pfSense soon.
-
Here are some benchmarks in regards to each queuing discipline/ queuing script. Personally, I prefer Cake to anything else
https://www.bufferbloat.net/projects/bloat/wiki/RRUL_Chart_Explanation/
http://burntchrome.blogspot.com/2016/12/cake-latest-in-sqm-qos-schedulers.html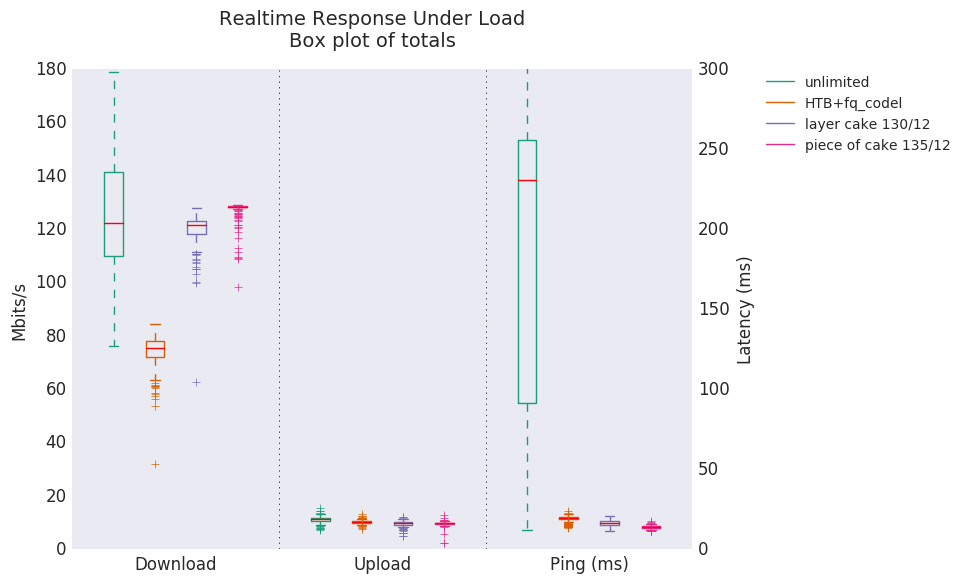
-
Looks like Piece of Cake has the highest download, lowest ping, and nearly identical upload. HTB+fq_Codel seems to be too aggressive for download.
The makers of Cake also have a future plan for a "Bobby" AQM, named after a slang for police to give a light "tap" to drop an incoming packet. The idea is that download is different from upload in that the cost of transferring the data has already happened, making it undesirable to drop packets. But if you don't drop/mark packets, you can't signal upstream to back-off. Codel, fq_Codel, and Cake are all a bit aggressive in this because they're meant to handle egress instead of ingress.
-
I have spent some time today on my unit trying to fine tune it to my needs and the results surprised me, as I previously considered fq_codel (or fairq_codel combo) to be king for everything.
Little summary first.
I have little interest in capping throughput, my needs are to prevent packet loss to time sensitive traffic and also to mitigate latency varience as much as possible.
For outbound upstream traffic, it was easy, fairq+codel works really well and I get no packet loss and only slight affect on latency.
Downstream however I have had a harder time. My main problem is when I download something on steam because it floods the line with dozens of connections I get packet loss on other traffic if I leave it unregulated. On my previous router an asus ac68 running merlin asuswrt, the downstream rules I had using fq_codel kept latency at a very nice level when downloading but never controlled the packet loss, I just used steam's own speed limiter to minimise the issue (note tho even at capped speed's at half my line rate I still got some packet loss, simply due to how aggressive steam is when downloading).
fairq+codel on the downstream had a worse latency when downloading than the asuswrt setup did and packet loss was pretty much the same, so unsatisfactory. PRIQ+codel improved things on latency noticeably and a little on packet loss but was still not happy. I couldnt get CBQ working, and CODELQ is almost useless. This leaves what I am on now which is HFSC+codel on the downstream.
There is a myth out there that since the packets have already arrived, there is little benefit in shaping downstream traffic, and a even worse myth is that the recipient cannot control the way these packets arrive, both are wrong. TCP is a end to end negotiation protocol, it has multiple variables called 'windows' which dictate how fast data flows, 2 of those windows are managed by the sender and 1 is managed by the recipient, if the recipient reduces its window then that is enough to reduce the flow of packets. Likewise if the recipient drops packets and causes retransmissions then the sender will backoff as a result and as such that also slows the flow of packets.
Using HFSC which is the hardest to configure I found by allocating high enough minimum speeds to the traffic queues I want to never drop packets, that the performance characteristics are the best results I have got for the downstream. So basically I allow the lower priority queues to hit high speeds but they have no minimum speed set so pfSense can drop them off as much as it needs, but the higher priority queues have min speed's set that I know are high enough to ensure I will not have issues. HSFC takes some learning but I think I at least have enough of the basics now to have a reasonable working config which I hope I can improve over time.
-
There is a myth out there that since the packets have already arrived, there is little benefit in shaping downstream traffic, and a even worse myth is that the recipient cannot control the way these packets arrive, both are wrong. TCP is a end to end negotiation protocol, it has multiple variables called 'windows' which dictate how fast data flows, 2 of those windows are managed by the sender and 1 is managed by the recipient, if the recipient reduces its window then that is enough to reduce the flow of packets. Likewise if the recipient drops packets and causes retransmissions then the sender will backoff as a result and as such that also slows the flow of packets.
That "myth" applies to latency, not bandwidth. From a latency perspective, once packets have arrived there is practically nothing that intelligent queueing can do to improve the latency of that packet. This scenerio assumes that your WAN is slower than your LAN, meaning that there should be practically no queue.
My favorite QoS tutorial is: http://www.linksysinfo.org/index.php?threads/qos-tutorial.68795/
It explains the differences between upload & download QoS very well without being overly technical and/or theoretical.Also, codel (and practically all popular TCP algorithms) works by dropping packets so I dunno if your objective of zero dropped packets is plausible. ECN-marked packets are a possibility but support is far from universal.
-
Ok perhaps I didnt explain what I meant well enough.
I mean manipulating the traffic flow of inbound packets from bulk downloaders such as steam, by slowing down those flows, it then ensures that my line itself will not slow down the flow of packets I want to arrive quickly.
The results are easy to see on dslreports speedtester which pings your connection whilst you download of their server's. Also I test via ssh latency and even simply running pings, all these tests show the latency of small packets improved by configuring downstream shaping.
So some results from pings.
Idle pings 8-9ms to bbc.co.uk
Downloading without a shaper pings increase 20-50ms to bbc.co.uk (for 6 threads).
With a shaper that becomes the bottleneck depending on the configuration, but for fairq+codel I got it down to about 9-25ms, with HSFC its 8-11ms.I also have a samknows black box on my line which runs tests at set intervals, typically speedtests but also things like streaming tests as well as monitoring my line latency via a 24/7 service. In the hours since I enabled HSFC the samknows box has stopped causing large latency spikes on the graph.
In the UK all isp's selling broadband over openreach infrastructure have to set a line profile which basically is a rate limit slightly below the line rate, this will cause some back buffering when a line is maxed out, but even if this wasnt in place typical congestion which has no discrimination will affect packets if the line is saturated. In my case I have moved the bottleneck to the ingress queue's and simply making sure certain packets are processed right away, whilst others are intentionally dropped or delayed to ensure the line has free capacity.
You can get similar results e.g. in a ftp client restricting the receive tcp buffer size to a very low value, or doing things like reducing the tcp rwin size in the OS, it slows down your maximum speeds, but in turn downloading doesnt affect latency or packet loss as there is no bottleneck been reached.
So yes I cannot ensure every single packet is processed instantly (under bottleneck conditions) but I can manipulate which packets get through without hindrance.
-
The goal of shaping download is to signal the sender to backoff before the bufferbloated FIFO queue on your ISP does it. either way it's going to happen, but you can better control how and when.
-
yeah thats pretty much what I am doing.