Playing with fq_codel in 2.4
-
@mattund I have been, I would prefer to use out but it makes any troubleshooting I may need to do difficult. Not that I do traceroutes a lot but it annoyed me.
I have wondered if this was due to how the rule is creating states. Like it is rerouting the packet once the rule is applied; very weird.
There are two floating rules both in; one on WAN the other all of my vlans.
I wish I could just apply them to the WAN with in & out as the directions.
-
Hello, I am new here. I have been following this thread since last week. Tried the new patch and it's working as intended just like the manual. I leave everything in default, I just add the Upload/Download bandwidth Queue Management Algorithm
CoDel and FQ_Codel for Scheduler.I have tested it, hogging my connections doing 20 torrents and 1 download on IDM. Played Online game to see the ping and CMD ping www.google.com -t, I experienced 1 to 2 packet loss, and 3 to 5 ping dancing and I can still play like as if there were no downloads happening on the background.
Some issues on the syslog, but fixed it by this command: ifconfig <nics> -promisc

Just a heads up! This one though, it's just showing on the syslogs everytime.

By the way, I have Floating rules active and limiters(for LAN scheds, no queues).
Overall, thank you. This helps me a lot.
-
@xraisen Your nics shouldn't need to be in promiscuous mode. That is a message that I would ignore.
Promiscuous mode is just going to have your NIC accept all packets.
Non-Promiscuous mode will have you NIC drop packets not destined for it.
Unless you are doing packet captures I can't think of a reason you would want to run in promiscuous mode.
-
@cplmayo This was enabled default because I don't remember enabling this. But thanks for the info!
-
I'm also seeing the flowset busy log entries occasionally, I think it has to do with the fact that the rules don't always get deleted (just reconfigured). However, I am not positive on that yet. Others may have gotten around this or have other ideas...
EDIT:
We're a lot like opnsense with this patch, because they are using this (dummynet - not my patch lol) for their shaping I think. Well, regardless, this ticket:
https://github.com/opnsense/core/issues/1279
Due to the fact that the internal variables of each AQM instance is allocated and freed dynamically, re-configuring AQM (e.g. select CoDel for a pipe that currently uses PIE)
can lead the AQM code to access unallocated memory (freed during AQM re-configuration) and kernel panic could happen.
Therefore, I tried to avoid any potential kernel panic by preventing re-configuring AQM for busy pipe/queue.He suggests:
- Temporarily block the traffic (using IPFW rules) from passing through AQM PIE/queue until you finish your configuration.
- Delete the old pipes/queues that need to be re-configured with AQM and create them again with all the desired settings.
- Reboot the firewall
I think this really would need to be a code-level patch somehow. Somehow "unbusy" it, then apply
EDIT 2:
I find this kind of hilarious and coincidental, but I'm experiencing this right now. I'm going to screw around with my shaper.inc and see what it takes to shake this error.
EDIT 3:
Deleting and recreating the rules does nothing to alleviate the error, however setting the Queue Management Algorithm to on the Parent Limiter droptail worked to get it to stop throwing each apply for me.
-
@mattund From my experience with limiters and floating rules; always apply after any single change to a limiter. Each time I make a change I save and apply. I ran into problems at first when I would save several changes and apply at once.
May help may not.
For floating rules always reset states after making a change. This is due to how pfSense handles floating rules. It just helps to ensure that your floating rules are being applied to all of your traffic. If you add a floating rule and do not reset states only new traffic will be evaluated against the rule.
-
This post is deleted! -
@cplmayo said in Playing with fq_codel in 2.4:
@xraisen Your nics shouldn’t need to be in promiscuous mode. That is a message that I would ignore.
Promiscuous mode is just going to have your NIC accept all packets.
Non-Promiscuous mode will have you NIC drop packets not destined for it.
Unless you are doing packet captures I can’t think of a reason you would want to run in promiscuous mode.I found out why it was enabled. Because I use the NTOPNG package. I have uninstalled it, now it's gone. The package turned on the promiscuous mode to monitor the packets.
-
@mattund said in Playing with fq_codel in 2.4:
He suggests:
Temporarily block the traffic (using IPFW rules) from passing through AQM PIE/queue until you finish your configuration.
Delete the old pipes/queues that need to be re-configured with AQM and create them again with all the desired settings.
Reboot the firewallI have tried this method, but when doing "ipfw sched show" this will show up
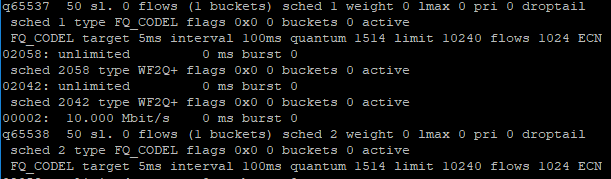
Notice the "Drop tail" cannot be changed to CoDel, PIE, RED and GRED and It's very persistent.
Please confirm this on your end.
EDIT 1:
Changing the Queue Management Algorithm to Tail Drop, the "config_aqm Unable to configure flowset, flowset busy!" was gone.
EDIT 2:
Trying Tail Drop + FQ_CODEL on scheds and CODEL on queues and use queues instead of scheds, gives me a better results without the syslog nagging. Hogging the bandwidth again for testing, I got zero packet loss and ping on www.google.com and CSGO are dancing to 0ms to 1ms swiftly like nothing happened. This is the best bandwidth management setup I have experienced so far on pfsense. Take note, I have an active traffic shaper (fairq+codel) on floating rules for voice, games and browsing priorities.
-
@xraisen Would you mind sharing some screenshots of your config :D
-
@zwck I have a 50Mbps Symmetrical connection. So, I will give 40Mbps to Wired, and 10Mbps to Wifi. What will happen, when the wired are full, it will not eat up all the bandwidth reserved for the wifi devices and vice versa. These are my config as follows.
STEP 1: Applied this patch for ez life.
@w0w said in Playing with fq_codel in 2.4:
Applied this diff https://github.com/pfsense/pfsense/compare/RELENG_2_4_3…mattund:RELENG_2_4_3.diff
Adding new queue by pressing button on limiter settings page opens new page and you can add new queue save and apply it, but it does not appear in the list and I don't see it anywhere. But it can be only in my case, just because I have some April version of 2.4.4, before PHP7 preparations were made.STEP 2: I created Aliases to separate Wired and WiFi
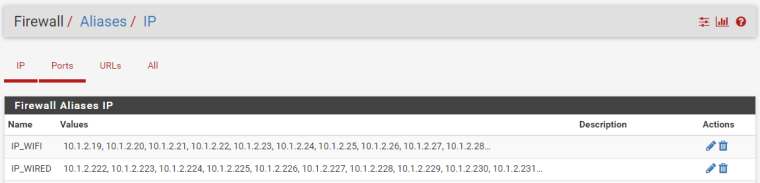
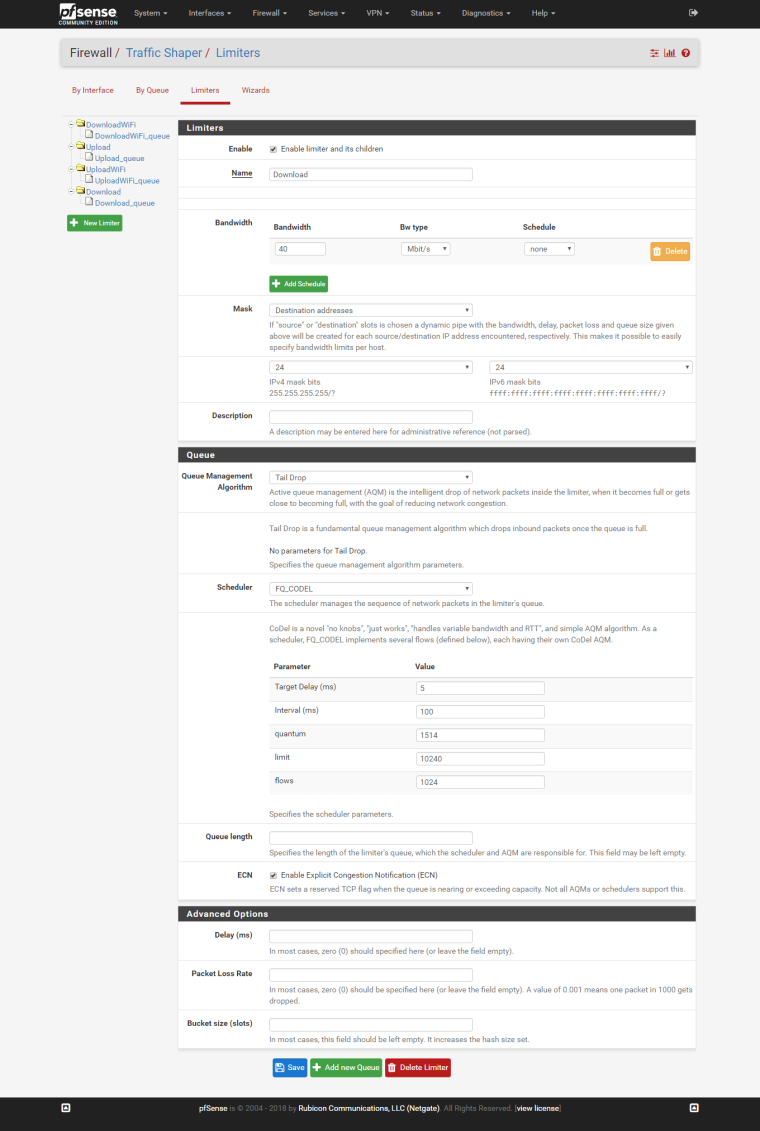
STEP 3: Create a limiters.
Download:
Upload:
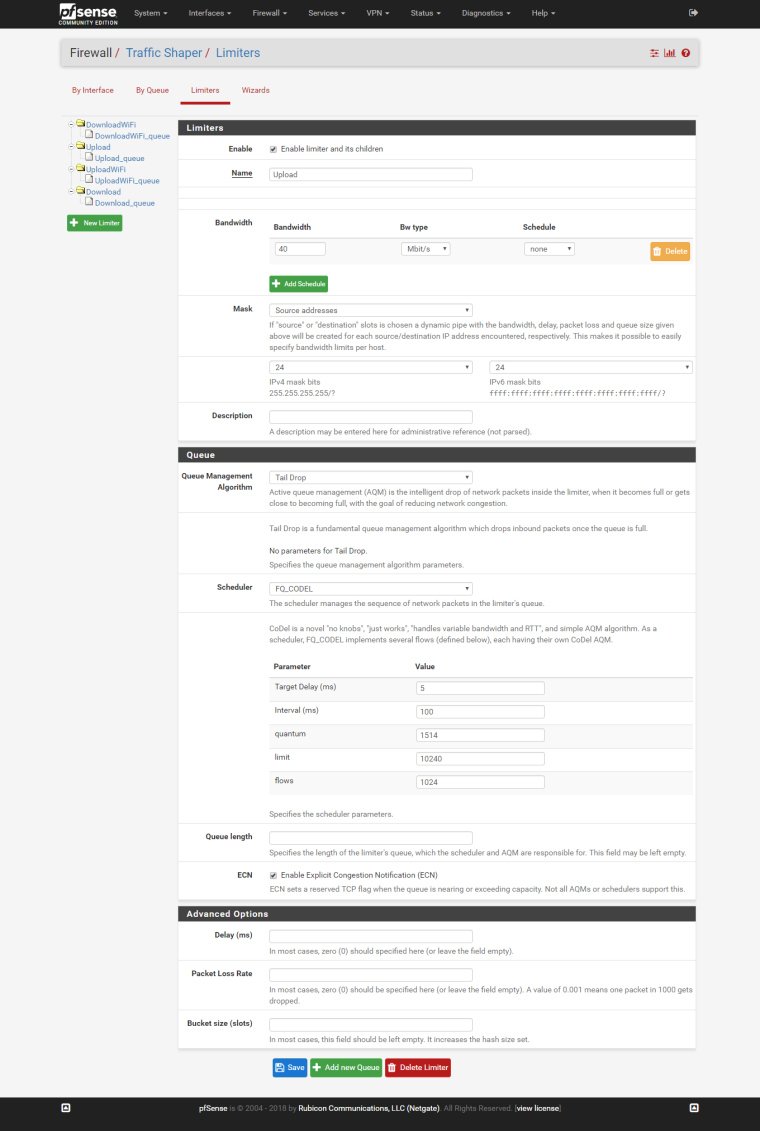
Same to other limiters, just change the bandwidth.
STEP 5: Create child queues
Download queue:
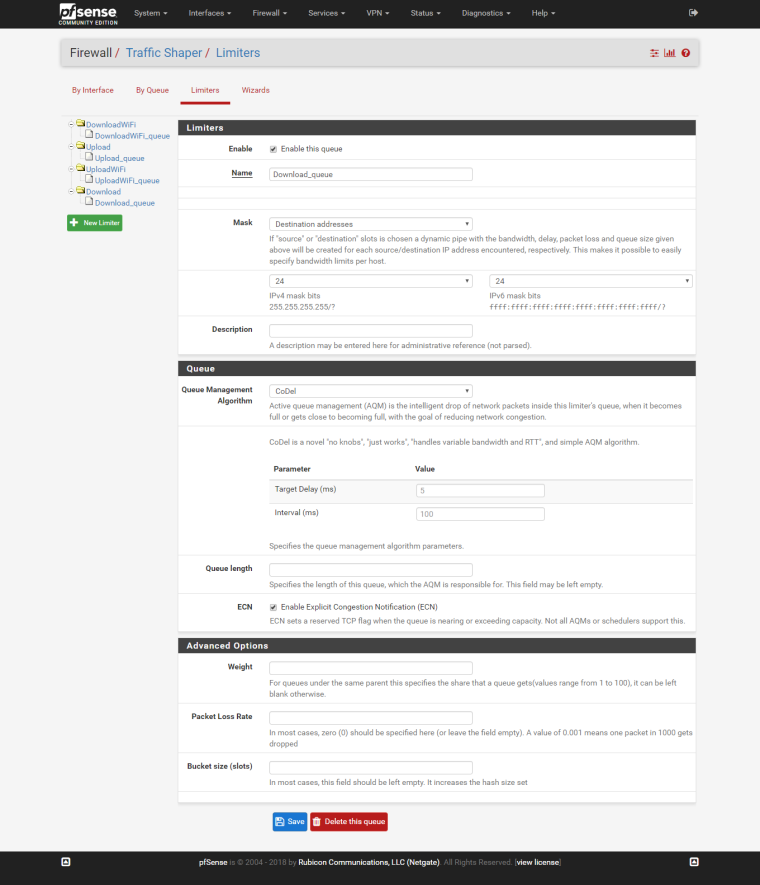
Upload queue:
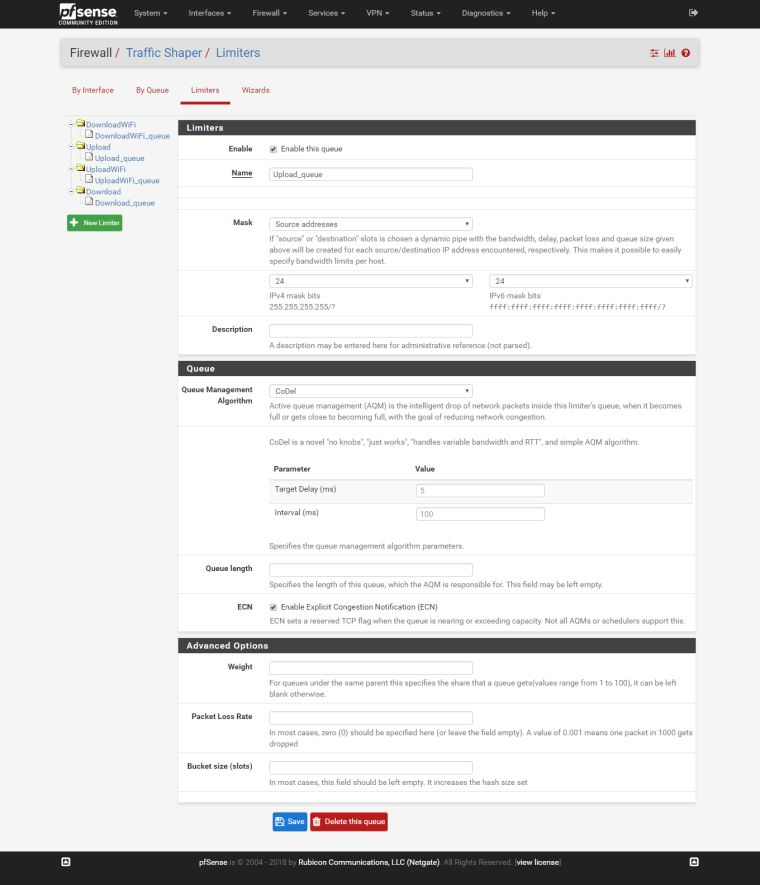
STEP 4: Create LAN rules and assign the pipe in/out as queue I've created.
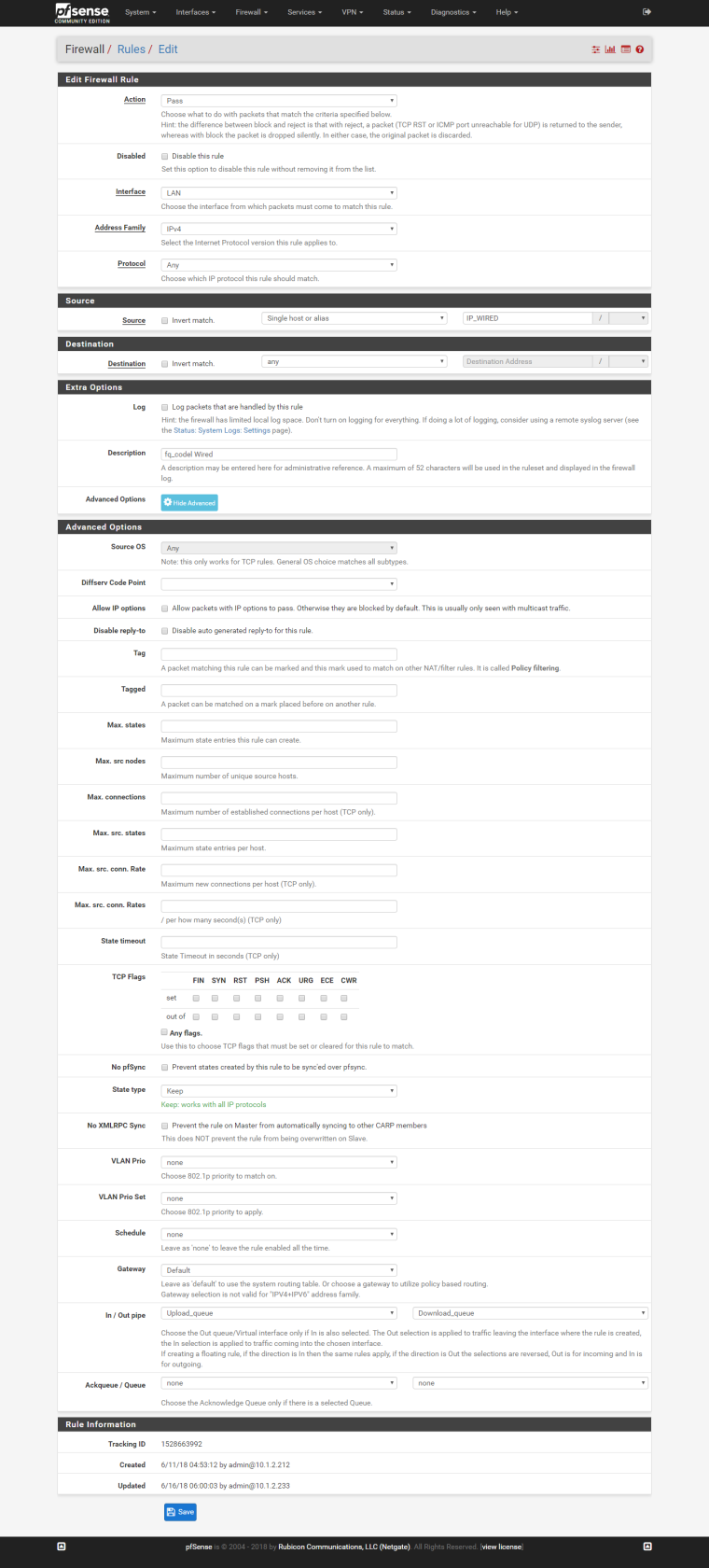
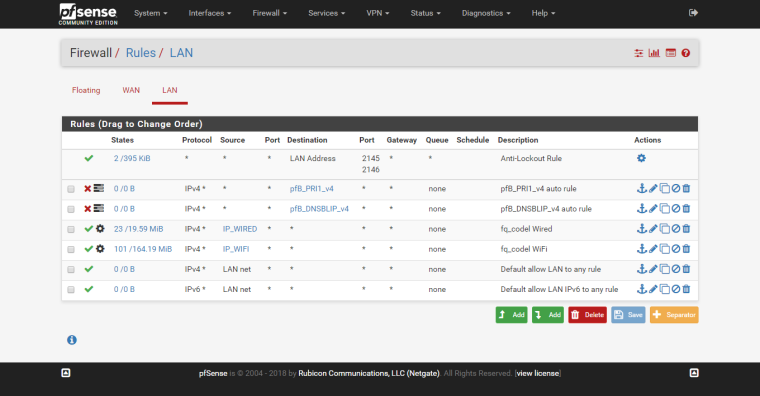
And so on...
My rules arrangements:
Why I use queue than sched? I believe its a Flexible “fair use” bandwidth limiter
References:
#1 https://www.gridstorm.net/pfsense-traffic-limiting-fair-share/
#2 https://www.reddit.com/r/PFSENSE/comments/3e67dk/flexible_vs_fixed_limiters_troubleshooting_with/My Traffic shaping rules for priorities. I am used to be a fan of HFSC, but I find this better than HFSC for my needs:
WAN: FAIRQ
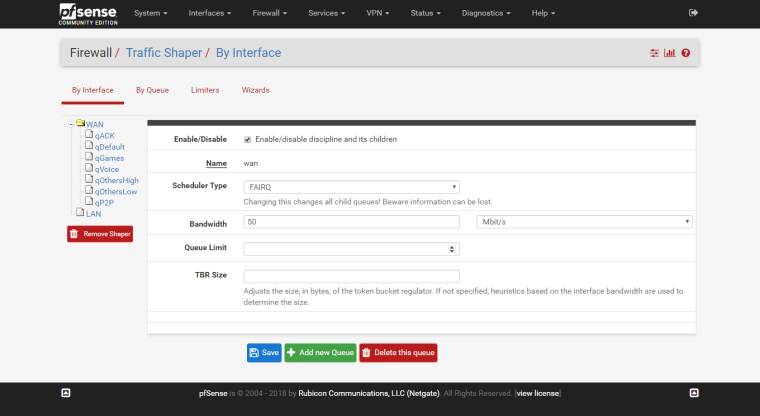
WAN Child example:
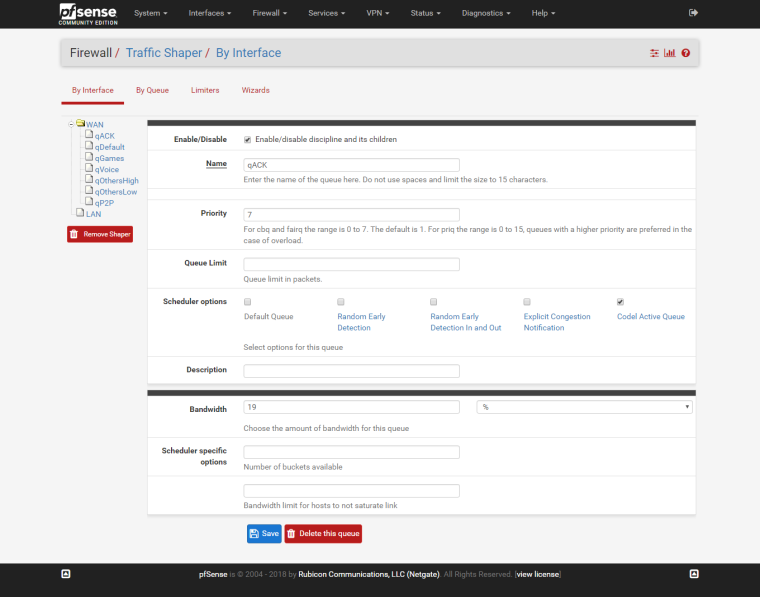
The rest are self-intuitive.
My floating rules:
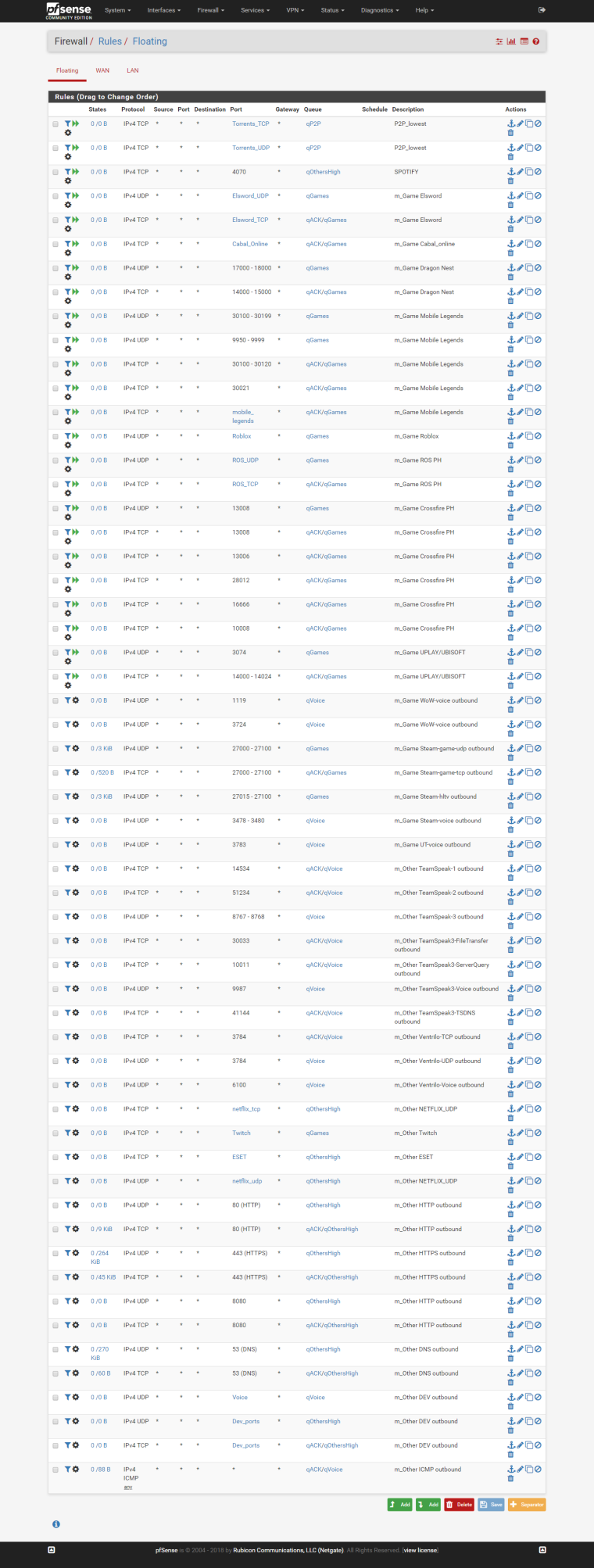
In my 4 years experience on pfsense, this is the best config I get so far for my requirements.
Many thanks to all members of this community. Ideas are from them, I just built it based from their brilliant minds. Credits and kudos to them!
EDIT 1:
I installed two packages only for my box. I have uninstalled squid and squidguard because it's not helping getting my desired QoS and I will stick to pfblockerng-devel by bbcan because it has a new feat that whatever squidguard had. I have installed FreeRadius for Captive Portal full control over it.
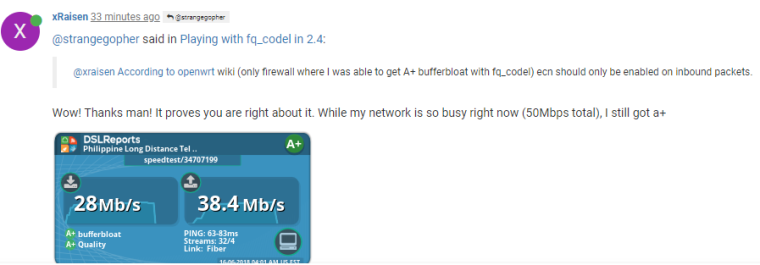
EDIT 2: Added this because it's really helpful.
-
@mattund So I'm an idiot and just figured out a way around the apparent routing loop. I redid my floating rules; created two rules one in and one out. However, I set the protocol to TCP/UDP since that is all I really want to apply QoS to anyway. No, that ICMP is not having the rule applied to it when I run a traceroute from a vLAN I can see the correct information.
So far for me, this has worked much better because I apply the rules directly to the WAN interface and not worry about creating extra rules to prevent shapping of local traffic.
So obvious and I can't believe I just thought of it today.
-
@xraisen According to openwrt wiki (only firewall where I was able to get A+ bufferbloat with fq_codel) ecn should only be enabled on inbound packets.
-
@mattund I still get those errors with Tail Drop as parent
-
@strangegopher said in Playing with fq_codel in 2.4:
@xraisen According to openwrt wiki (only firewall where I was able to get A+ bufferbloat with fq_codel) ecn should only be enabled on inbound packets.
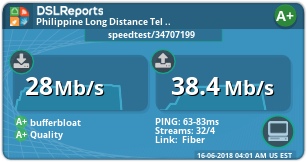
Wow! Thanks man! It proves you are right about it. While my network is so busy right now (50Mbps total), I still got a+
-
Also isn't fq_codel doing head drop, then why is parent selected as tail drop?
-
@strangegopher I believe something has to be set there, otherwise it is is set "for you" (and in that case, I think it defaults to tail drop?). So, while you're absolutely right about the functionality of both, I think that at the greater level dummynet does need some sort of plan for packets that exceed the queue size. Whether or not that ever happens since FQ_CODEL is on, I can't really say for sure. You'd think that FQ_CODEL would ultimately be a gatekeeper and never let taildrop see an excess ... that's my guess.
I'm actually really curious about the behavior now; I'll get back to you on what dummynet does without taildrop selected so we have some concrete evidence other than my assumption. Who knows, we might be able to add a "None" option?
EDIT: Got the answer, check this out:
if (fs->flags & DN_IS_RED) /* RED parameters */ sprintf(red, "\n\t %cRED w_q %f min_th %d max_th %d max_p %f", (fs->flags & DN_IS_GENTLE_RED) ? 'G' : ' ', 1.0 * fs->w_q / (double)(1 << SCALE_RED), fs->min_th, fs->max_th, 1.0 * fs->max_p / (double)(1 << SCALE_RED)); else sprintf(red, "droptail");That is the dummynet code that is responsible constructing the output of the
ipfw pipe show(etc) commands. It indicates that, if RED/GRED is off, then it's going to just say "droptail"/tail drop. Which, tells me that droptail is the fallback default behavior; FQ_CODEL must super-cede it in some way when it's enabled. In other words, if you don't specify Tail Drop, it'll default to it anyways, which would make a "None" option as I'd previously suggested unnecessary. But, if you think about it, it makes sense - we constrain these queues to some ultimate size - so we must have a way to enforce that. I think that Tail Drop is just dummynet's way of ensuring that promise, even if FQ_CODEL is really doing all the legwork. -
@mattund said in Playing with fq_codel in 2.4:
super-cede
That answers the question why droptail is very persistent when "flowset busy" log.
I have no problem with droptail but Codel should be placed there as AQM and tried RED, but it reverts back to droptail.
I am downloading like 3x more than my bandwidth limit, but IT JUST WORKS!
-
Does anyone know why this might have appeared in my logs?
fq_codel_enqueue maxidx = 342 fq_codel_enqueue over limit fq_codel_enqueue maxidx = 342 fq_codel_enqueue over limit fq_codel_enqueue maxidx = 342 fq_codel_enqueue over limit fq_codel_enqueue maxidx = 342 fq_codel_enqueue over limit fq_codel_enqueue maxidx = 342 fq_codel_enqueue over limit fq_codel_enqueue maxidx = 342 fq_codel_enqueue over limit fq_codel_enqueue maxidx = 342 fq_codel_enqueue over limit fq_codel_enqueue maxidx = 342 fq_codel_enqueue over limit fq_codel_enqueue maxidx = 342 fq_codel_enqueue over limit fq_codel_enqueue maxidx = 342 fq_codel_enqueue over limitIn fact it appeared ~450 times:
[2.4.3-RELEASE][admin@x.x.x]/root: dmesg | grep fq_codel_enqueue | wc -l 902My config is simple:
[2.4.3-RELEASE][admin@x.x.x]/root: ipfw sched show 00001: 95.000 Mbit/s 0 ms burst 0 q65537 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail sched 1 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 ECN Children flowsets: 1 BKT Prot ___Source IP/port____ ____Dest. IP/port____ Tot_pkt/bytes Pkt/Byte Drp 0 ip 0.0.0.0/0 0.0.0.0/0 68 53304 0 0 0 00002: 18.000 Mbit/s 0 ms burst 0 q65538 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail sched 2 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 ECN Children flowsets: 2 0 ip 0.0.0.0/0 0.0.0.0/0 61 5849 0 0 0At the time the messages appeared, the box was receiving a large (basically 100Mb/s linerate) of UDP traffic (bacula backup running) and I was also doing some testing using iperf.
The reason I noticed it was becuase a TCP stream I had running at the time was terrible, it dropped to dialup speeds while the bacula traffic was running.I have a 100/20 connection, which you can see I have told fq_codel to have 95/18 of to ensure that things work well.
Does fq_codel struggle with large streams of incoming UDP traffic?
And does anyone know why I got those messages in my dmesg?Thanks! fq_codel has been otherwise amazing.
-
@muppet I have seen this too, although not with limits that high (the default of 10240). A number of people have reported this same issue, and in my experience it does also seem to be provoked by UDP traffic. The explanation in section 5.1 here:
https://tools.ietf.org/id/draft-ietf-aqm-fq-codel-02.html
implies - as expected based on the log message - that this indicates that your queue limit has been reached so packets are being dropped. Although it also suggests that in this case packets will be dropped "from the head of the queue with the largest current byte count." You would think that in this case that would be the queue handling all that UDP traffic, but if that were happening, it should mitigate the impact on other flows (which is not what you're seeing since TCP suffers badly). Additionally, I have seen others report that their pfSense machine crashes if they get enough of these sustained log messages. I don't know that it was ever clear whether the "over limit" event itself or the accompanying flood of log messages was to blame for those crashes though. Unfortunately, I don't have any solution. Section 4.1.3 of the same document linked above suggests that a limit of 10240 should be fine for connection speeds of up to 10Gbps, so there must be something else gong on here, but I don't know what.