Playing with fq_codel in 2.4
-
@tman222 - also, I'd like more folk to start posting "debloat events/day". Codel kicks in rarely, but I'm pretty sure every time it does it saves on a bit of emotional upset and jitter for the user. For example I get about 3000 drops/ecn marks a day on my inbound campus link (about 12000 on the wifi links), and outbound a 100 or so. Every one of those comforts me 'cause I feel like I'm saving a ~500ms latency incursion for all the users of the link.
I'm kind of curious how many drops/marks a day your 10gigE/1gig link has.
-
@dtaht said in Playing with fq_codel in 2.4:
@tman222 - also, I'd like more folk to start posting "debloat events/day". Codel kicks in rarely, but I'm pretty sure every time it does it saves on a bit of emotional upset and jitter for the user. For example I get about 3000 drops/ecn marks a day on my inbound campus link (about 12000 on the wifi links), and outbound a 100 or so. Every one of those comforts me 'cause I feel like I'm saving a ~500ms latency incursion for all the users of the link.
I'm kind of curious how many drops/marks a day your 10gigE/1gig link has.
Thanks @dtaht - I'd be happy to share that info. What's the best way to collect that data under FreeBSD? I'm assuming you are referring to the fq_codel packet drops over a 24hr period instead of interface drops. Thanks again.
-
Heh. I don't know. I tried to fire up bsd once recently and found it entirely alien.
In linux it's
tc -s qdisc show dev whatever
They also show up as interface drops, so I use mrtg to track it. I don't have ecn marks though, in my snmp mib. That's growing important.
If you figure it out (or it's a missing facility) let us know!
-
I note also flent can collect a lot of stats along the way on it's tests - cpu usage, qdisc stuff, etc - but we have not a lot of bsd support in there. see flent/flent/tests/*.inc
-
Another test in flent I've started using more of late is the "square wave" tests. These "speak" to those with more of an EE background. There's one that directly compares bbr and cubic in particular. Most people find the rrul test overwhelming at first. I used it on a recent preso to broadcom: http://flent-fremont.bufferbloat.net/~d/broadcom_aug9.pdf
-
@dtaht said in Playing with fq_codel in 2.4:
Heh. I don't know. I tried to fire up bsd once recently and found it entirely alien.
In linux it's
tc -s qdisc show dev whatever
They also show up as interface drops, so I use mrtg to track it. I don't have ecn marks though, in my snmp mib. That's growing important.
If you figure it out (or it's a missing facility) let us know!
Thanks @dtaht - I do know that one can see the statistics of fq_codel with the "ipfw sched show" command, but I'm not sure how to go about logging that for a 24 hour period. If anyone else here has an idea, please do let me know. Maybe the logging functionality is something that still needs to be added?
@dtaht said in Playing with fq_codel in 2.4:
I note also flent can collect a lot of stats along the way on it's tests - cpu usage, qdisc stuff, etc - but we have not a lot of bsd support in there. see flent/flent/tests/*.inc
So I do run the Flent application through Linux (Debian Stretch) and I see those different test options through the front UI. The only thing I can't seem to figure out is how to add parameters to the test through the UI -- maybe to do that I have to run from the command line.
@dtaht said in Playing with fq_codel in 2.4:
Another test in flent I've started using more of late is the "square wave" tests. These "speak" to those with more of an EE background. There's one that directly compares bbr and cubic in particular. Most people find the rrul test overwhelming at first. I used it on a recent preso to broadcom: http://flent-fremont.bufferbloat.net/~d/broadcom_aug9.pdf
Thanks @dtaht for this additional info. I didn't quite know which test you meant before I saw the presentation :). I ran the TCP 4 Up Squarewave test as well and got some interesting results. Using fq_codel on the WAN link and netperf.bufferbloat.net as the testing server on the other side, it doesn't look nearly as nice as what you have in your slides (in fact it looks closer what you had on slide 36). It's somewhat similar on a local 10Gbit to 10Gbit test (although no fq_codel enabled there): Had to turn the IDS/IPS off on the interfaces and the flows started to behave more, but still not quite as nice as what you had. Having said that, I think my results might be influenced by the fact that I already have TCP BBR enabled on my Linux machines, which requires the FQ scheduler to be enabled as well via tc qdisc. Do you think I should turn that off and rerun with the cubic defaults?
Thanks again for all your insight and advice.
-
re: "ipfw sched show" command, but I'm not sure how to go about logging that for a 24 hour period.
cron job for (date; ipfw sched show) >> debloat_events
re: additional stats. I usually script those but there is a way to stick additional stats in the default .rc file I think.
--te=cpu_stats=machine,machine --te=qdisc_stats=login@machine,... --te=qdisc_interfaces=etc
re "nearly as nice". One of my fears is of bias without actual testing - "I made this change and the network feels better, ship it!" - where people often overestimate the networks bandwidth, or fiddle with bbr, etc and don't measure. So my other favorite flent feature is you can upload somewhere your .flent.gz files and have an expert take a look (hint hint). Flent by default stores very little metadata about your machine so I'd hoped people would be comfortable sharing its data more widely, unlike, for example packet captures. (note the -x option grabs a lot more).
I am under the impression pacing works universally on modern kernels but have not tested it - particularly not under a vm. That's another fav flent feature, go change out sch_fq for fq_codel and you can easily compare the two plot changes over that single variable.
I love flent. It's the tool that let bufferbloat.net pull so massively ahead of other researchers in the field.
-
It's probable your graph looks like pg 36 'cause that box is on the east coast? we have flent servers all over the world - flent-fremont.bufferbloat.net on the west coast, one in germany, denmark, and london, several on the east coast, one in singapore....
-
@dtaht said in Playing with fq_codel in 2.4:
It's probable your graph looks like pg 36 'cause that box is on the east coast? we have flent servers all over the world - flent-fremont.bufferbloat.net on the west coast, one in germany, denmark, and london, several on the east coast, one in singapore....
Thanks @dtaht - I think that box (netperf.bufferbloat.net) might be located near Atlanta judging by a traceroute to it. Is the list of all Flent servers available publicly somewhere? Or are those testing servers only available to the contributors of the project?
Thanks again.
-
we probably should publish it because it doesn't vary much any more. We used to have 15, now, it's 7? 6? So far we haven't any major scaling issues.
Unlike speedtest.net we don't have a revenue model, and the hope was we'd see folk setting up their own internal servers for testing. It's just netperf and irtt.
-
@dtaht
I really respect the work that was done by you and people fighting bufferbloat over the world.
As for me I use AQM everywhere it possible, to eliminate bufferbloat from my networks. The one problem is still to be investigated is those networks where we can't to detect the bottleneck size aka bandwidth limit varies a lot during day usage. I know there is a lot of such ISP networks in Japan, for example.
Yes we can set bandwidth limit to the minimum one, but it not smart enough, it would be good to detect the current bandwidth automatically and adjust everything. I do know that there are some software and router scripts samples on the net that do it in various ways, but it still need to be studied and developed in many systems, also pfSense. -
@w0w - and you. keep fighting the bloat!
My sadness is that I'd hoped we'd see all the core bufferbloat-fighting tools in DSL/fiber/cablemodems by now. BQL + FQ-codel work well on varying line rates, so long as your underlying driver is "tight". We also showed how to do up wifi right. Also thought we'd see ways (snmp? screen scraping?) of getting more core stats out of more devices, so as to be able to handle sag better.
with sch_cake we made modifying the bandwidth shaping nondestructive and really easy (can pfsense's shaper be changed in place?) - it's essentially
while getlinestatssomehow()
do
tc change dev yourdevice newbandwidth
doneSo far the only deployment of that feature is in the evenroute, but I'm pretty sure at least a few devices can be screenscraped.
As for detecting issues further upstream, there are ways appearing, but they need to be sampling streams to work (see various tools of kathie's: https://github.com/pollere )
-
Hi @dtaht,
I have a basic question regarding bufferbloat that I never quite understood. I can understand how there can be bufferbloat on the uplink of a WAN connection (e.g. 1Gbit LAN interfaces sending into a e.g. 10Mbit cable modem upload). However, what causes bufferbloat on the download since generally the interface the data is being sent into is larger than the download speed on the WAN interface (e.g. a 250Mbit cable modem download speed sent into a 1Gbit LAN interface)?
Thanks in advance for the insight and explanation, I really appreciate it.
-
The buffering in that case builds at the CMTS (on the other side of the cablemodem). CMTS's tend to have outrageous amounts of FIFO buffering (680ms on my 120Mbit comcast connection), so, if you set your inbound shaper to less than their setting, you shift the bottleneck to your device and can control it better. It's not always effective (you can end up in a pathological situation where the CMTS is buffering madly as fast as you are trying to regain control of the link), but setting up an inbound shaper to 85% or so of your provisioned rate generally works, and you end up with zero inbound buffering for sparse packets, and 5-20ms for bigger flows, locally.
Does that work for you? (It's still an open question for me as to how netgate does inbound shaping).
It's horribly compute intensive to do it this way, but since we've been after the cablecos for 7+ years now to fix their CMTSes with no progress, shaping inbound is a necessity. In my networks, I drop 30x more packets inbound than outbound but my links stay usable for tons of users, web PLTs are good, voip and videoconferencing "just work", netflix automagically finds the right rate... etc.
That work for you? The buffering comes from bad shapers on the far side of the link. It's not just CMTSes that are awful. DSL is often horrific. I'm now seeing some 1G GPON networks with several seconds of downlink buffering. I guess they didn't get the memo.
-
I actually kind of wish I hadn't stopped work on "bobbie", a better policer. fq_codel is far too gentle and has the wrong goal for inbound shaping. Yes - it works better than anything we've ever tried, but a better policer would have zero delay for all packets at a similar cost in bandwidth and far less cpu. I think. Haven't got around to it. (basically you substitute achieving a rate in a codel like algorithm instead of a target delay). Tis research for someone else to do, I'm pretty broke after helping get sch_cake out the door.
-
Over here ( https://github.com/dtaht/fq_codel_fast ) I'm trying to speed up fq_codel a bit, and add an integrated multi-cpu inbound shaper.
-
@dtaht - thanks for the response - that makes a lot of sense.
Event though I used a cable modem in the example in my previous post, the question was really about GPON. I suppose what ends up happening is that there are buffers at at the GPON card (hardware) for both upload and download. If there is too much data being pushed into the link from upstream servers (i.e. a bunch of people downloading), the buffers start to fill up and packet delay (bufferbloat) occurs for downstream users. Since GPON bandwidth is generally shared among several users, I suppose the severity can vary depending on the amount of users, their usage patterns, and level of congestion. Furthermore, I suppose it's likely easier to experience bufferbloat on the uplink direction since GPON is asymmetric (2.4Gbit down / 1.2Gbit up).
In my personal experience with a gigabit GPON link I have been fortunate: I can set inbound/outbound shaping at >95% of max bandwidth and still not experience any significant delay/bloat.
-
Yes, the GPON folk did not think hard about buffering, and it won't be much of a problem in their early deployments until they start oversubscribing more links. This is a flaw repeated time after time in this industry - 3g grew to suck, 4g was "better", 5g is going to fix 4g... (and 2g, 'cause so many have exited the band now, can be surprisingly good nowadays).
Recently I gave a presentation to broadcom ( http://flent-fremont.bufferbloat.net/~d/broadcom_aug9.pdf ) Another one of my hopes in the bufferbloat project was that someone would solve the over-subscription problem up front for a change - and I thought we'd have a chance with GPON and gfiber, but the team I was on got dissolved about 9 months from being able to deploy.
Sigh:
http://www.dslreports.com/speedtest/results/isp/r3910-google-fiber
-
I'm going to have some serious issues attempting to measure the reduction of bufferbloat from fq_Codel
This is with shaping disabled. Dear lord, what is my ISP doing? I love fiddling and they're taking that away from me. I just realized I forgot to disable BitTorrent. Explains my low upload speed.
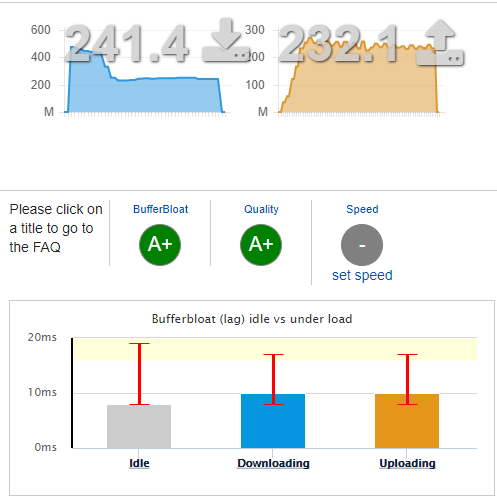
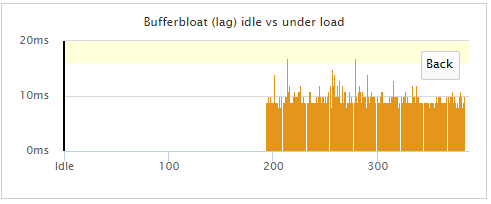
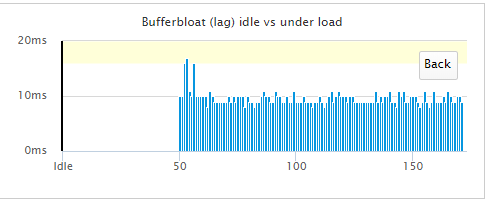
-
I just updated from 2.4.3 to the 2.4.4 release candidate and am keen to try out fq_codel. I haven't read all 434 (!) posts of this thread, but can anyone kindly point me to a basic beginner's guide or instructions to setting it up for a simple home connection?