Playing with fq_codel in 2.4
-
@uptownvagrant from the xml file (thx for the guidance) you are running with the default quantum of 1514. Can you retry with 300 to see if the ping problem still exists?
I note that quantum should generally match the mtu - 1518 if you are vlan tagging - and yes, below 40mbit or so, 300 has been a good idea.
The other thing I can think of is adding an explicit match rule for icmp as a test.
The other other thing I notice is the slope changes a bit and the height of the graph is ~3ms on the 500Mbit test rather than about 2ms. This implies there's a great deal of
buffering on the rx side of the routing box, and your interrupt rate could be set higher to service less packets more often.Lastly, while you are here, if you enable ecn on the linux client and server also
sysctl -w net.ipv4.tcp_ecn=1
you'll generally see the tcp performance get "smoother". (but I haven't reviewed the patch and don't remember if ecn made it into the bsd code or not)
-
@luckman212 yes, if you have two different interfaces at two different speeds you should set the limiter separately.
-
@uptownvagrant yep, nat can be a major issue for any given protocol, and it would not surprise me if that was the source of the icmp lossage with load. I'm still puzzled about "the burp at the end of the test" thing (which also might be a nat issue, running out of some conntracking resource, etc)
-
@strangegopher cablemodems do ipv6 by default now, so I would stress that future shapers/limiters always match all protocols. Otherwise (see wondershaper must die).... as for your performance closer to the spec, does the limiter have support for docsis framing? The sch_cake shaper does, and we can nail the upstream rate exactly. It's like, 3 lines of code in sch_cake....
-
@dtaht please elaborate interested in cake
-
@dtaht Thanks again! I actually tested quantum 300, limit 600, on the just the 9800Kbps queue, and then on both, and saw roughly the same behavior with regard to ICMP. I also tried quantum 300, limit 600, on the 9800Kbps queue and quantum 1514, limit 1200, on the 49000Kbps queue without much change either. I also created en explicit ICMP match rule and tested but there was no significant change. :(
I'll grab a packet capture during limiter saturation to see if ECN is being flagged on the FreeBSD/pfSense box and will enable ECN on the Linux boxes in the lab. I'll also investigate the buffering you mentioned and finally I'll test without NAT.
@strangegopher my $.02, the match rule has the advantage of matching all traffic without having to add the queues to all of your explicit pass rules on the LAN. So for those running a deny all except explicitly allowed configuration it can be a little cleaner setup and less rules to futz with if there are queue changes.
-
Hey i played a littlebit with flent after setting up a simple shaper.
1Gbit symetrical, and i used netperf.bufferbloat.net for my tests.
Not sure how usefull these results are.shaper off

shaper 900mbit on
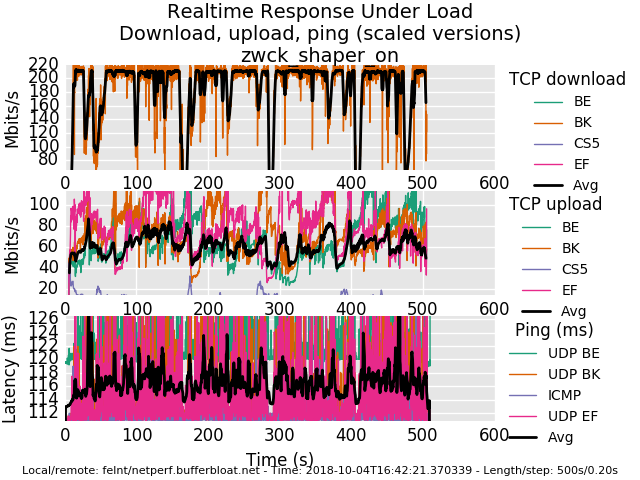
0_1538667306903_rrul-2018-10-04T164221.370339.zwck_shaper_on.flent.gz
0_1538667308924_rrul-2018-10-04T172307.046314.zwck_shaper_off.flent.gz
25mbit
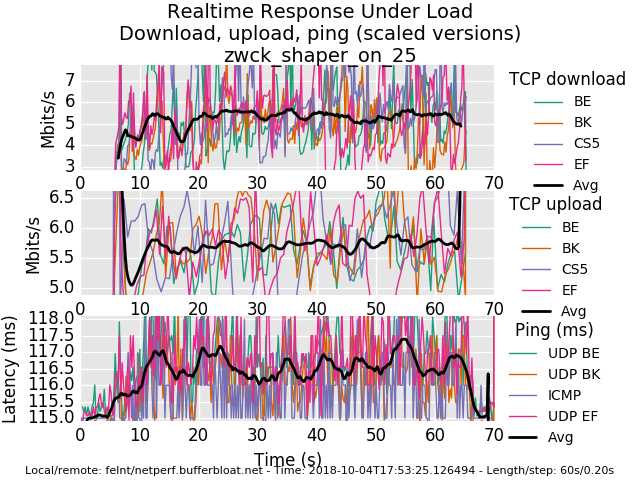
0_1538668567021_rrul-2018-10-04T175325.126494.zwck_shaper_on_25.flent.gz
-
@zwck your first result shows you either out of cpu or that server out of bandwidth in both the shaped and unshaped cases at 1gbit. I have not gone to any great extent to get 1gbit+ to work in our cloud. I should probably start pursuing that....
peaking at 400mbit down 160 up unshaped. I imagine it can do either down or up at 1gbit?
It's interesting to see you doing mildly better shaped than unshaped. More bandwidth, lower latency. (still could be my server though). your enormous drops in throughput on the shaped download may be due to overrunning your rx ring, try boosting that and increasing the allowed interrupts/sec, and regardless, your users are experiencing issues at a gbit that you didn't know about, because flent tests up and down at the same time (like your users do), and web tests don't. Win for flent again, go get hw that can do 1gbit in both directions - even unshaped - at the same time!
correction it looks like only one download flow started? is that repeatable? try rrul_be also (doesn't set the tos/diffserv bits). that could be a another symptom of a nat problem....
your 25mbit result is reasonable (at this rtt), and shows ping working properly. However at this rtt there's not a lot of ping to be had... (irtt tool would be better) or a closer server.
I don't know where in the world you'd get a 115ms baseline rtt to that server??
If you are on the east coast of the us, try flent-newark.bufferbloat.net, west coast: flent-fremont... england: flent-london -
-
@uptownvagrant honestly a limit < 1000 is kind of an artifact of the tiny 32MB routers we used for the testing. I don't recommend < 1000 at any speed currently. However OSX is using < 1000 for their fq_codel thing. At these speeds it's pretty hard to hit a 600 packet limit (standing queue should be no more than, oh, 32 full size packets at 10Mbits, don't quote me!, or ~600 acks. It almost never hurts to drop acks).
I look forward to hearing about the ecn test.
I am hoping it's something wrong with nat on the icmp front, because, cynically, it's not a problem I can solve and fq_codel would thus be proven correct ('specially if ecn works). :)
-
@strangegopher sch_cake is an advanced version of "sqm" with an integral shaper and a zillion other features that we worked on for the last 5 years. It's now in linux 4.19. With all the "second system syndrome" ideas in it, it's about twice as cpu intensive as htb + fq_codel. :(. There's a lot in cake I don't like. And I'm one of the authors! I wanted something faster and more elegant.
details:
https://www.bufferbloat.net/projects/codel/wiki/CakeTechnical/
https://lwn.net/Articles/758353/It's really mostly targetted at sub 20Mbit uplinks but we have got it to 50Gbit on heavy duty hw.
But: some of the good ideas are amazing - per host fq, ack-filtering, robust classificaton, and easy one line setup. Specific to your question was how by matching the docsis or dsl framing overhead you can get to ~100% of your outbound line rate - ripping that idea out of cake and making it work generically in freebsd's limiters would let outbound match the isp rate, as I said. cake is dual bsd/gpl licensed for this reason, but unlike fq_codel, I'd kind of prefer people lift the best ideas out of it and use them rather than slavishly copy the code.
some details about how you could make freebsd's limiter obey docsis framing on this thread here:
https://github.com/dtaht/sch_cake/issues/48
-
someone try this at 100mbit+ speeds:
hw.igb.max_interrupt_rate="128000"
I don't know where to increase the rx ring, in linux we use "ethtool". Probably these?
hw.igb.rxd="4096"
hw.igb.txd="4096" -
for the record, this is cake:
root@office:~# tc -s qdisc show dev eth0 qdisc cake 8010: root refcnt 9 bandwidth 9Mbit diffserv3 triple-isolate nat nowash ack-filter split-gso rtt 100.0ms noatm overhead 18 mpu 64 Sent 3823129438 bytes 27251388 pkt (dropped 2316876, overlimits 34025373 requeues 343) backlog 0b 0p requeues 343 memory used: 313464b of 4Mb capacity estimate: 9Mbit min/max network layer size: 28 / 1500 min/max overhead-adjusted size: 64 / 1518 average network hdr offset: 14 Bulk Best Effort Voice thresh 562496bit 9Mbit 2250Kbit target 32.3ms 5.0ms 8.1ms interval 127.3ms 100.0ms 103.1ms pk_delay 0us 1.8ms 27us av_delay 0us 132us 6us sp_delay 0us 4us 4us backlog 0b 0b 0b pkts 0 29491122 77142 bytes 0 3971468896 11505073 way_inds 0 1290904 1214 way_miss 0 474687 3673 way_cols 0 0 0 drops 0 1029 0 marks 0 4 0 ack_drop 0 2315847 0 sp_flows 0 2 1 bk_flows 0 2 0 un_flows 0 0 0 max_len 0 28766 1198 quantum 300 300 300I have a feeling y'all here like fiddling with classification and rules and so on, but
sometimes it's nice to just typetc qdisc add dev eth0 root cake bandwidth 9mbit nat docsis ack-filter
and be done with it.
-
note: I have $dayjob and sailing tomorrow. don't expect replies.I sure hope the icmp issue is nailed....
Happy debloating!
-
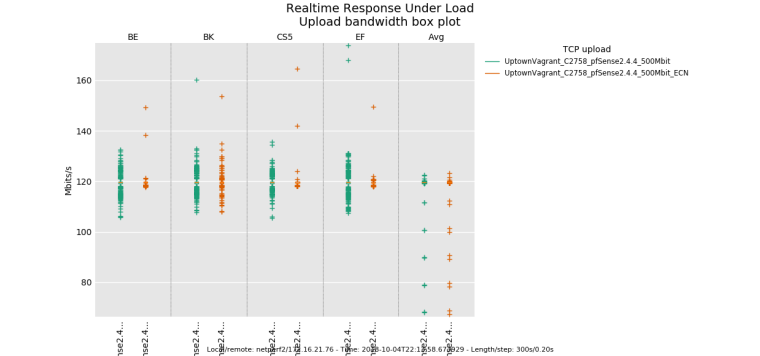
Here is the Atom C2758 doing 500mbit.
Here are the customized sysctl values:
net.inet.tcp.tso="0" net.inet.tcp.lro="0" dev.igb.0.fc="0" dev.igb.1.fc="0" dev.igb.2.fc="0" dev.igb.3.fc="0" dev.igb.0.eee_disabled="1" dev.igb.1.eee_disabled="1" dev.igb.2.eee_disabled="1" dev.igb.3.eee_disabled="1" hw.igb.rxd="4096" hw.igb.txd="4096" hw.igb.rx_process_limit="-1" hw.igb.tx_process_limit="-1" hw.igb.num_queues="8" hw.igb.max_interrupt_rate="128000" net.inet.tcp.hostcache.cachelimit="0" net.inet.tcp.syncache.bucketlimit="100" net.inet.tcp.syncache.hashsize="1024"Here is 500mbit without ECN.
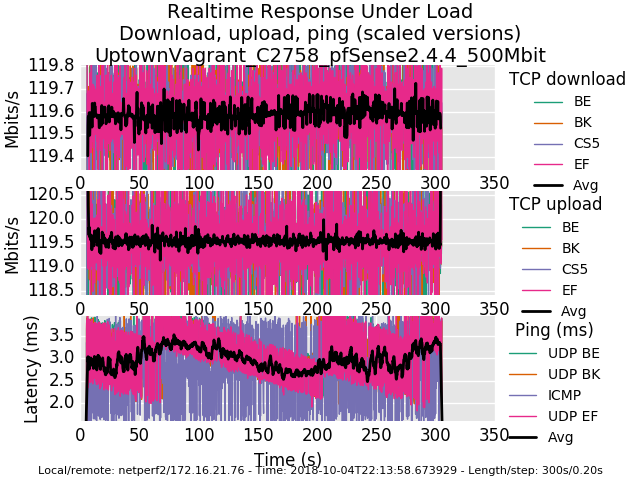
0_1538717701396_rrul-2018-10-04T221358.673929.UptownVagrant_C2758_pfSense2_4_4_500Mbit.flent.gzHere is 500mbit with end-to-end ECN enabled.
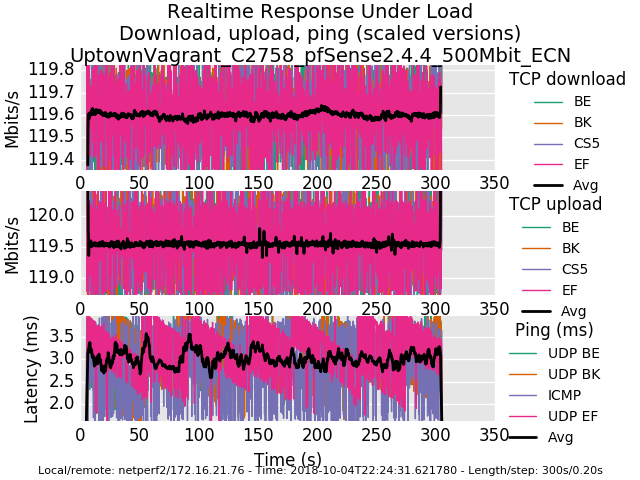
0_1538717713043_rrul-2018-10-04T222431.621780.UptownVagrant_C2758_pfSense2_4_4_500Mbit_ECN.flent.gzI have confirmed that disabling NAT removes the dropped icmp behaviour, traceroute loops, when limiters are used on an interface with NAT.
-
I switched to a server closer and upped the computing power :D
This is shaped to 800Mbps
1_1538719369675_rrul-2018-10-05T075404.739377.zwck-shaper_on_800Mbit.flent.gz
-
@uptownvagrant awesome. Is there a path for y'all to report this problem back to netgate and the freebsd devs? I'm totally over my head there. With nat you are using more cpu of course and there may be more variables worth tuning for more resources, the gc interval, and so on.
Your .5ms of smoothish jitter is a little puzzling but I can live with it. freebsd does not have sub 1ms timestamp resolution so perhaps that's it. What's 500usec between friends? :)
another nice flent thing is the ability to do comparison plots. The ecn result has smoother throughput.
-
@zwck you sure you shaped the dl to 800mbits? 'cause that's 28mbit. could also be your server or client has a fifo on it too, fq_codel or sch_fq on linux help with bidir tests a lot, also. or it could be flent-london... (flent's tcp_download test? the rrul test is extreme you can drill down with simpler tests)
(I thought you might be near england! It's really weird that I have such a grasp of worldwide rtts)
-
Hi and goodmoring. (for me at least)
Also i included @uptownVagrant 's tuning as we have more or less the same pfsense setup :D
Sorry that such a newbie, such as i, is posting here too, sadly the topic is far from my expertise.ipfw sched show 10000: 500.000 Mbit/s 0 ms burst 0 q75536 50 sl. 0 flows (1 buckets) sched 10000 weight 0 lmax 0 pri 0 droptail sched 10000 type FQ_CODEL flags 0x0 512 buckets 1 active FQ_CODEL target 5ms interval 60ms quantum 1514 limit 10240 flows 1024 ECN Children flowsets: 10000 BKT Prot ___Source IP/port____ ____Dest. IP/port____ Tot_pkt/bytes Pkt/Byte Drp 0 ip 0.0.0.0/0 0.0.0.0/0 3 144 0 0 0 10001: 500.000 Mbit/s 0 ms burst 0 q75537 50 sl. 0 flows (1 buckets) sched 10001 weight 0 lmax 0 pri 0 droptail sched 10001 type FQ_CODEL flags 0x0 512 buckets 1 active FQ_CODEL target 5ms interval 60ms quantum 1514 limit 10240 flows 1024 ECN Children flowsets: 10001 0 ip 0.0.0.0/0 0.0.0.0/0 6 540 0 0 0and rrd
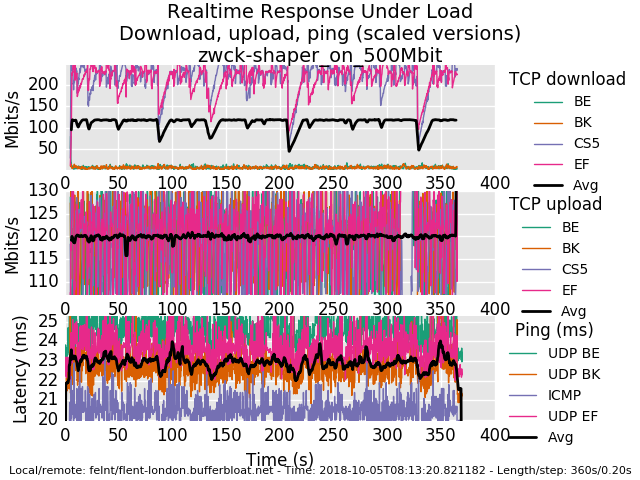
0_1538720733109_rrul-2018-10-05T081320.821182.zwck-shaper_on_500Mbit.flent.gz
-
It;s awesome to have more folk doing bidir network stress testing with flent. nobody in product marketing wants you to do that.
@zwck ok, I rebooted the box in london (it had a tcp tweak i didn't like), It should be back up in a minute. It looks to me though you just peak out at 1gbit total, though, on this hw...)
-
@zwck said in Playing with fq_codel in 2.4:
burst 0
Is there a way to tune the "burst" value in the limiter above? It's nice to see the dscp values actually being respected e2e here also. that never happens.