Playing with fq_codel in 2.4
-
last bit of ocd. I'm not sure if the interrupt change or the increase in rx ringbuffer size did any good, but I note these are things that are not fixed numbers and need to scale by the bandwidth. "more" interrupts is generally better for low latency networking but too many interrupts overwhelms a modern cpu faster.
I think the sysctl for tso and "large receive" offloads to the igp card are here:
net.inet.tcp.tso="0"
net.inet.tcp.lro="0"These "bulk up packets" in the card and lower system memory and interrupt requirements. I'm all about unbulking and interleaving (FQ-ing) packets. lro in particular is often notoriously buggy, but worth enabling as intel's network cards (igp) in particular generally has good support for it. (be prepared to totally crash the network side of the box though, or break something elsewhere in the network stack).
Now that it is repeatable, can the icmp nat issue get reported somewhere?
-
@dtaht More interrupts is generally better for low end NICs. Higher end NICs have soft-interrupts and dynamic low latency interrupt rate limiting.
The Intel i350 does interrupt coalescing to reduce the interrupt average rate, but if an interrupt has not occurred in a certain amount of time, it can immediately issue an interrupt instead of delaying it. This allows the NIC to quickly respond to sparse data flows. I think Intel implements it as if an interrupt has not occurred within the past N time where N is the size of the coalescing.
In the past, I have measured single digit microsecond(~8us) latency ping flooding my LAN NIC with ~70,000 pps through my switch from my desktop. All the while averaging a nearly perfect 600 total interrupts per second. About 150 interrupts per second per core.
It's been a while since I did that test and I think drivers have changed and I now see a less stead interrupt rate under load. But even when I did my ~1.48Mpps load test on my firewall, I was seeing only a hair bit over 1,000 interrupts per core, hanging around 13% cpu on my 3.3ghz quad i5. Should have went with a dual core. Oh, and that test was with HFSC shaping enabled. The actual pps was closer to 1.43-1.44Mpps because it was from my desktop and it was having issues. But it was 1.44Mpps ingress LAN and 1.44Mpps egress WAN ~13% cpu and ~5k total interrupts per second with shaping.
A soft interrupt is when the device driver using MSI-X to mask off an interrupt, processes some data, then before returning control to the kernel, checks to see if any new data came in. If it sees new data, it can continue to process the new data without any new hardware interrupts, at least from itself not sure about other devices. Once the data is fully consumed, the interrupt mask is removed and new data can cause the hardware to interrupt the CPU again.
-
@harvy66 Would you then recommend we allow the pfSense igb driver dictate the max interrupt rate rather than forcing it via sysctl values in the /boot/loader.conf.local file? I force my max interrupt rate to 32,000.
-
@dtaht Yes, we can create a bug report here:
https://www.netgate.com/docs/pfsense/development/bug-reporting.htmlThere are still some details I would like to collect before filing the bug but anyone can file it now if they have an itch. I believe folks thought the limiter NAT issues were fixed in 2.4+. I'll be away for the next few days but will check in next week.
Here is the most recent related bug I could find that looks to be related:
https://redmine.pfsense.org/issues/4326Post about the long-standing limitation:
https://forum.netgate.com/topic/104297/limiters-do-not-work-with-nat/ -
@Harvy66 Great explanation, thanks.
Some items -
A) 1000 interrupts/sec = 1ms delay in processing packets. We are seeing 2-3ms delays here for the sparse flows on the rrul test. This implies coalescing at about a 1ms interval - where the total delay for those flows were fq_codel running closer to the hw, on a 500mbit workload, should be about, um, 104 usec. there's 6k of tcp packets, 440 bytes by the sparse flows and 256ish for the acks.
So if coalesing could be tuned down to half what's being shown here, observed interlfow latency would be halved. If ya got 13% of cpu used up maybe (is there a tool?) you can turn down coalesing by 7x and get 7x less latency.
(bad measure in that that doesn't deal with context switch overhead. 4x? The tool in linux is called ethtool)
Rant:
Most pps tests with lro, tso tests suck in that they A) only test one 5 tuple stream, not mixed traffic (like the various rrul tests - and real traffic do). This also means you don't stress out the routing cache table which is a huge bottleneck. I'd LOVE a pps test that simulated, oh, 280 flows simultaneously each lasting for .5-2 sec over a minute, using different packet sizes).
We wrote rrul in part because all the industry pps tests were misleading, people were sinking years into things like gro to lie to those tests, instead of focusing on the real underlying traffic problem on real workloads people really had. If we'd focused on the right thing, perhaps we'd have TCAMS in way more hardware, maybe even cpus. Cisco is still laughing all the way to bank on this front.
B) Same goes for outbound shaping - some intel hardware has a programmable completion interrupt rate so you can just tell it "it's a 500mbit interface", and you can just throw fq_codel at it with no limiter and negligable overhead.
Hmm... That hardware might actually be in this atom box we've been debugging. It's not in the apu2. I can't remember the specific model. But the freebsd implementation would have to have fq_codel as a native qdisc.
C) I'd really hoped the isps would demand hardware for their shaping needs that ran fq_codel - it's not that more expensive than a fifo is. There was some early work on this subject from arris ( http://snapon.lab.bufferbloat.net/~d/trimfat/Cloonan_Presentation.pdf ) but I've heard nothing since, and my comcast links still have 680ms of overbuffering where they should have turned it down to under 100ms years ago.
inbound shaping is always going to be very cpu intensive. we can try to parallize that
but that involves fixing the entire path from the driver and hashing in the hardware card.fixing oubound would save 1/3 the cpu for inbound on a symmetric connection.
I'd really hoped the users would rise up and demand less latency, and the isps respond to their bufferbloat "F" scores on:
http://www.dslreports.com/speedtest/results/bufferbloatand their dslam/bras/enodeb/cmts vendors rush in with new or upgraded products to meet the demand in a virtuous circle. I do know of a few isps now getting it right....
D)
Multicores have a tendency to not scale well for routed network traffic. It usually pays to do all the network processing on one core and use the other for administrative processing. Even with a good shared l2 cache, it sucks to cross cores to get to another device. On arm boxes I have, locking eth0 to one core and eth1 to another nearly halves routed throughput.E) I've already ranted about the stupidity of tuning the entire internet for a 20 second test from speedtest.net instead of running realistic tests for hours at a time, or ever even looking at the carnage at t+21.
end rant. I need to go sailing. :)
-
@Harvy66 thanks for the explanation on the i350 series - I'll dig into that more.
@dtaht the C2758 SoC integrates the i354 in my test pfSense box so it's directly related to what @Harvy66 shared.
I'm enjoying the progress being made here. Happy sailing @dtaht? Does the dog join you on the boat?

Cheers!
-
I revised the rant I wrote previously above a bit. Can't get my motor started to get out of the dock....
-
@tibere86 I am not confident enough myself to make a recommendation, but I have been thoroughly impressed with how igb with the i350 works with what I assume is interrupt coalescing. I would also hesitate to make any broad assumptions about how interrupts would be handled across different Intel NICs and also different hardware.
pfSense should focus on out-of-the-box decent performance but high reliability. Unless a certain feature is known to work reliably, I would have documentation and let the end user optimize their firewalls. Of course I would expect purchased pfSense appliances to be fully optimized.
Even MSI-X is hit and run for motherboard support. It's technically part of PCIe spec, but it's one of those chicken-and-egg issues where it's not reliable enough to enable out of the box, but no one is getting useful feedback to fix issues because no one is using it. From what I've read in regards to MSI-X, if you want the maximum performance, you can try enabling it, but it is possible for some combination of chipset, firmware, driver, kernel, etc issues that can make it act flaky. Maybe this is no longer true. I do know that the HP rebadged i350s have MSI-X support disabled because of compatibility issues with some of HP's hardware, but because they report as an i350, the driver will assume the feature is enabled. Bad things can happen and they may not happen all of the time.
-
In case people want to try, this is what I'm using for my config
kern.ipc.nmbclusters="262144" hw.igb.rxd=2048 hw.igb.txd=2048 net.pf.states_hashsize=524288 net.pf.source_nodes_hashsize=524288 hw.igb.fc_setting=0 hw.igb.rx_process_limit="-1" hw.igb.tx_process_limit="-1" net.inet.tcp.syncache.hashsize="2048" net.inet.tcp.syncache.bucketlimit="16" net.inet.tcp.syncache.cachelimit="32768"states_hashsize and source_nodes_hashsize should be powers for two and typically equal to or larger than your total possible states.
edit: I just noticed I do not have hw.igb.enable_msix=1 in there anymore. I know I would want it enabled and I do not remember having any issues. Not sure why it's not there, but I plan on doing a fresh ZFS install of pfSense soon. I'll worry about it then.
edit2:
dmesg | grep -i msi
igb0: Using MSIX interrupts with 5 vectors
igb1: Using MSIX interrupts with 5 vectorsSeems to be enabled.
-
@dtaht said in Playing with fq_codel in 2.4:
I revised the rant I wrote previously above a bit. Can't get my motor started to get out of the dock....
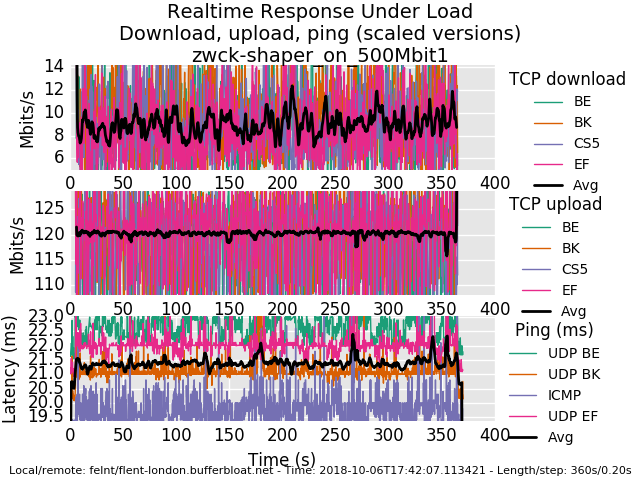
I hope you had a nice trip after you started the engine. I am wondering could you explain the graphs that are being posted whats actually displayed. I suppose in the scaled example the first 2 y axis (Mbits) are a maximum loss of bandwidth during upload and download phase, i.e a delta of some sorts, so a low number is good in both cases, for the ping its just the measured ping and not a difference between max and min ping?
Anyway I exchanged my pfsense with a beefier version.
ntel(R) Core(TM) i5-3550 CPU @ 3.30GHz,
i3501_1538841948180_rrul-2018-10-06T174207.113421.zwck-shaper_on_500Mbit1.flent.gz
-
Nope. Didn't get out of the dock. Tomorrow maybe.
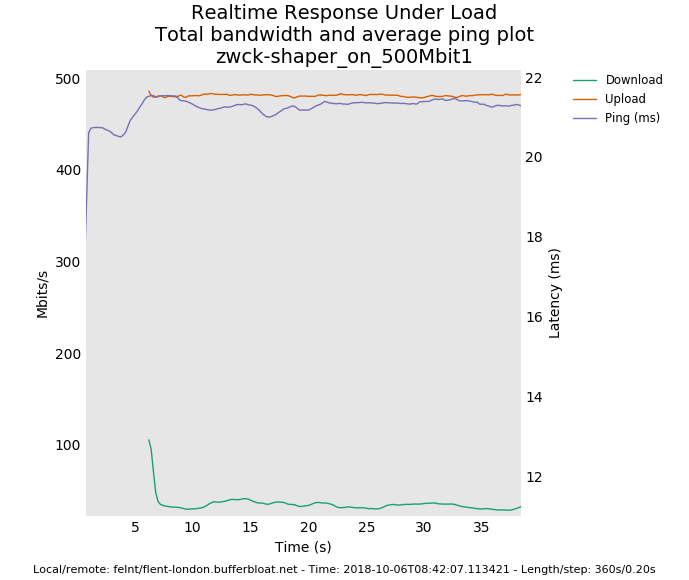
There's a totals and bar graph plot available from flent-gui.
You are setup for 500mbit symmetric and only getting 40mbit down?
you are still having a small spike every 40 or 60 seconds... got anything in cron? It's not a big problem like ping failing completelt through nat, but...
as to explaining a rrul graph - there's 4 tcp flows down, 4 tcp flows up, 3 ping-like udp flows an an icmp (ping) flow. We mark each flow with a common diffserv marking (0 = best effort, cs1 = background, cs5 is supposedly used for video, ef was often used for voice). The black line is the average of the flows so you can just multiply in your head by 4 - usually- unless one flow didn't get started. I tend to look at this plot first, then the totals plots, then bar charts. Or make a change between runs and run the flent-gui *.gz so to be able to produce comparison plots (Data->Load additional data files or use view->open files to compare various test runs)
We take a sample of the amount transferred per flow every 200 ms (-s .02 if you want every 20ms). This gives you a reflection (not the actual) of the tcp sawtooth. the width of the sawtooth reflection gives you an idea as to the rtt the tcp flows are experiencing (not very visible at these rtts but it's there). FQing and relying on ping alone to measure rtt tends to "hide" the real latency of the queue depth for the fatter flows.
In case I'm still talking past you, google for "tcp sawtooth", "diffserv", etc. :)
so the rrul test stresses out a link in both directions simultaineously, tests if classification exists, measures your achievable throughput, shows if you have anomalous behavior like the weird drops we saw yesterday, and runs for 40 seconds longer than speedtest by default.
there is actually an option on linux's flent to get the actual tcp sawtooth and rtt stats directly from the tcp stack itself (it's in the --socket-stats option in tcp_nup tests). And the queue depth from the router. And a zillion other things. It's a deep tool, as, oy, before toke wrote it we were mostly decoding packet captures in wireshark, and that had no way to compare multiple tcp flows against each other at all, so things like the 3 simultaneous flows dropping at once would have been invisible. In 60 seconds we learn a lot. People fall in love with fq because the measurement flow gets prioritized, and miss tcp end up having enormous queue depths that need to be managed with aqm. (try sfq with 10000 packets if you like instead of fq_codel with rrul, or fq_codel with a target of 1000ms and interval of 10000ms and limit 10000)
I totally realize that the default plot is hard to grasp at first, but after a while it grows on you, and after checking for anomalies, go look at the cdf, totals or bar plots. There's another flent test I use a lot called tcp_tcp_4up_squarewave - which tends to speak to EE types better. That one starts one tcp flow (grabbing all the bandwidth), another after 10 sec (which should evolve rapidly to take half the bandwidth), another in 10 sec that should rapidly take 1/3 the bandwidth. If BBR is available it tests that. It really shows and I hope, conveys intuition as to how tcp is really working in your test environment - but is not the stress test rrul is. (try it shaped and unshaped! (bbr is not enabled in most of my cloud, but even cubic is interesting))
I used that one in a preso to broadcom.
http://flent-fremont.bufferbloat.net/~d/broadcom_aug9.pdfthere is no "perfect" score in the rrul tests. but if you run it pre-qos and post, and aim for "smoothness" and have seen what a "bad" link looks like (which is most of them), it grows on you. every time I go to a coffee shop or visit a business, I run a test... the horrors!
I am ocd enough to be unhappy about the 2-3 ms difference between loaded and unloaded latency on fq_codel in bsd and linux on these workloads where it could be only 104us if it were in hw or we could context switch fast enough and didn't coalesc so many interrupts. once you have bad latency you are stuck with it.
another confusing thing is the bandwidth is on the left, the ping latency is on the right in this plot:
so in more direct answer to your question, it's the actual ping, not the delta.
anyway, are you sure you have the inbound limiter at 500mbit? if so, what happens if you change outbound to 200 mbit and leave inbound at 500mbit?
-
or just try the flent tcp_download or --te=download_streams=16 tcp_ndown test. I'm really hoping this is a misconfiguration, or a problem with handing both inbound and outbound shaping at the same time, and not a fundamental problem with the inbound shaper peaking at a mere 40mbits on this hardware.
-
@harvy66 I note I wasn't ranting at you - but the world! - about the pps testing. I needed to go sailing. sorry! is there a way to coalesce less in this os?
-
One other thing about the traffic types difference on the latency plot on the bottom 3rd of your rrul test. This is probably (try the rrul_be test instead) showing that some switch, or pfsense, or somewhere on the path, something is paying attention to diffserv markings. And doing it wrong, probably based on a pre-2002 based interpretation of the "tos" field. cs1 should get less priority than best effort. and so it goes... it's not terribly significant, but..
The "ping" data usually comes back faster than the udp data because the host on the other side doesn't exit the kernel to respond, where the udp data requires the netserver to respond after a context switch to userspace. so you are measuring context switch time indirectly on this one.
Some routers deprioritize ping (I think this is a good idea, btw, but users oft think ping measures reality, so a lot of people prioritize ping to lie about the path. This makes ping floods in the ipv6 world potentially very disabling). so seeing ping take longer is "good", seeing ping get massively dropped, bad, being slightly faster, normal.
Excessive lossage of udp indicates a udp problem (https://www.badmodems.com/ is an example of devices that choke on udp + nat), however our rrul udp test is more robust if irtt is used.
there's other data you can pull out via text or csv
If I could get all the sysadmins and network device qa folk in the world to put flent in their toolkits it would be a better world, and it's available in most linux distros as a package now. I have a 10 line script that i run on visiting a customer that runs rrul, rrul_be, tcp_nup, tcp_ndown, tcp_squarewave, rtt_fair4 (tests for connectivity to 4 servers across the world and how badly they degrade over distance), a simultaneous ipv4 and ipv6 test that does the same, a udp burst test for wifi, and I forget the other two... (flent --list-tests)
10 minutes later, I flip through a few graphs and know what can be done to improve the network. fix it, then run it again, show the result to the customer, demonstrate things like voip and videoconferencing just working now, and get a check. In theory. I kind of wish it took days of work to do that now, instead of 25 minutes. it would pay better! I'm lucky to get lunch for so little apparent effort.
-
I’m glad you guys are working through this. I hope it gets to the point I can just have it on by default in the background making my connection nice.
-
@dtaht darn my modem, xb6, is on the list, didn't know puma 7 was also affected. Explains my crappy results in flent.
-
So I did a bit of reading today and found some fantastic resources of limiters, dummynet, and how the other schedulers in pfSense (FreeBSD) work:
http://info.iet.unipi.it/~luigi/ip_dummynet/original.html
http://info.iet.unipi.it/~luigi/qfq/
http://info.iet.unipi.it/~luigi/doc/20100513-bsdcan10dn.pdfhttps://www.netgate.com/docs/pfsense/trafficshaper/limiters.html
These are a bit dated, but still relevant.
After doing a lot of reading today, I wanted to share a couple additional thoughts - one regarding setting up fq_codel, the other about an interesting alternative setup I started experimenting with.
Regarding fq_codel Setup:
For the most basic setup, I think one only needs to create one or two limiters (up and down) and then in the Queue section, just enable and configure the fq_codel algorithm under Scheduler. The section for Queue Management Algorithm in my opinion does not need to be changed from the default and child queues under the limiter also aren't necessary. fq_codel creates queues and handles the AQM for them so there is no need to fill Codel in again under Queue Management Algorithm. If you were using another algorithm that is strictly a scheduler (e.g. RR or QFQ), the proper queue management algorithm would need to be selected. Having said that, the Queue Management Section can still be filled in if fq_codel is chosen as scheduler, but I'm just not sure how much additional benefit there would be (vs. just more compute cycles) to have AQM on the incoming packet queue and then again from fq_codel on the flow queues it creates/manages. To finish setting up, all one would need to apply is the name of the up and down limiter to the in and out pipe sections in the firewall rules.
Masks on the queues, in my opinion, also aren't necessary to get fq_codel to work properly because the algorithm handles the mapping of flows to queues.
Child queues can be created and these can be applied to the firewall rules, but it's not required to get the algorithm to work. Child queues become more interesting if one wanted to e.g. split the total bandwidth into weighted queues (e.g. schedule 9 packets out of queue 1 before scheduling 1 packet out of queue 2 in a 90/10 weighted scheme). But as @bafonso already mentioned fq_codel does not support weighted queues. For that one would have to use a different scheduler such as QFQ, for example.
I apologize in advance if anything on the above is incorrect, and if so someone please correct me. This is just my interpretation after doing some additional reading and testing today.
An Interesting Alternative Setup:
After reading about dummynet, limiters, pipes, queues, etc. today, I decided to try this alternative setup:
- Create two limiters: Up and Down. Fill in the bandwidth and then choose RR (Round Robin) for scheduler
- Create a child queue under each limiter and select Codel and ECN on each to enable AQM.
- For the upload child queue, choose "Source Addresses" for mask and change the bucket size to 1024.
- For the download child queue, choose "Destination Addresses" for mask and change the bucket size to 1024.
- Apply the upload and download queue to your LAN firewall rule (that allows outbound traffic) under in and out pipe.
To me this setup is very seems very similar to what fq_codel does. A queue (managed by Codel AQM) gets created for each IP/flow and then the scheduler traverses those queues in round robin fashion. Besides not being able to adjust the quantum parameter for instance, can someone tell me how this setup is different from fq_codel? Performance from what I can tell so far seems quite similar. However, I'm sure there a probably more differences.
Thanks in advance for your help, I really appreciate it.
-
fq_codel hashes on the 5 tuple, you are hashing on the source addr. The source addr is often not visible post nat, thus the 5 tuple (src,dst,src port, dst port, protocol) is a better distinguishing characteristic.
A single fq_codel instance contains 1024 shared queues based on a hash of that.
Having the filter up front into 1024 codel queues means a memory limit of 1024 * X packets. Usuaally not a problem, but it's losing the 5 tuple hash that hurts.
It looks like this bug needs to be reopened for the ping through nat bug.
https://redmine.pfsense.org/issues/4326
-
Thanks @dtaht - I think you are right, that is the biggest difference. I was originally thrown off this capability, because if you look here:
http://info.iet.unipi.it/~luigi/doc/20100513-bsdcan10dn.pdf
Slide 33 claims that masks are applied to the 5-tuple of each packet (so similar to fq_codel). However, in the Netgate documentation I see this:
https://www.netgate.com/docs/pfsense/trafficshaper/limiters.html
"Dummynet pipes have a feature called dynamic queue creation which allows unique queues based on the uniqueness of a connections source protocol, IP address, source port, destination address or destination port. They can also be used in combination. pfSense currently only allows setting the source address or the destination address as the mask."
So it looks like the limitation here might be pfSense and not dummynet itself? Does anyone know why this limitation exists in pfSense?
I'm currently playing around with Quick Fair Queuing (QFQ) and weighted queues a little bit to see how that performs. Any suggestions for performance comparison tests I could run?
Anyway, I don't mean to take this thread off track since it is about fq_codel after all and not the other scheduling algorithms available in dummynet/pfSense. However, after doing some reading, tinkering is a lot of fun :). That said, for simplicity and an algorithm that just works, fq_codel wins hands down, and the configuration is very easy on pfSense.
-
I put a bug over here: https://redmine.pfsense.org/issues/9024
I am not in a position to "help" much more here. You've got one bad modem, one proof of a nat problem with ping, another as yet unproven report of "all nat connections collapsing after a test" (or was that the bad modem?), and proof that fq_codel is doing the right things (both with and without ecn) without nat in place.