Playing with fq_codel in 2.4
-
as for bad cablemodems, I'm dying for someone to try this out: https://express.google.com/product/Arris-SURFboard-Cable-Modem-and-AC2350-Wi-Fi-Router-with-Arris-Secure-Home-Internet-by-McAfee/0_17937886568302066345_0
or a pure modem of the same generation from arris.
-
After doing a bit more thinking, I'm more curious about how the performance of fq_codel is impacted by enabling Codel AQM on the input queue.. For instance, consider the following two setups:
- Setup 1: Up and down limiters created with appropriate bandwidth for each. Enable Codel for Active Queue Management and then enable fq_codel for scheduler. Adjust queue size as necessary. Apply limiters to firewall rules. This setup to me looks like this:
Limiter (Pipe) Input Queue (managed by Codel AQM) ---> fq_codel scheduler ---> 1....N output queues (managed by Codel AQM), where N is number of flows.
- Setup 2: Up and down limiters created with appropriate bandwidth for each. Leave Active Queue Management as is and then enable fq_codel for scheduler. Adjust queue size as necessary. Apply limiters to firewall rules. This setup to me looks like this:
Limiter (Pipe) Input Queue (No AQM, just tail drop) ---> fq_codel scheduler ---> 1....N output queues (managed by Codel AQM), where N is number of flows.
I can imagine that setup 1) could potentially yield better performance especially if there is a big enough difference between the local interface (LAN) speed and the WAN connection speed. However, does the additional processing required (AQM x2) result in poorer performance on slower equipment?
I'm curious if anyone had run any tests using both these setups and noticed any difference? Also, it would be great to hear thoughts anyone might have regarding the performance of these options in general.
Thanks in advance.
-
@xraisen In my pfSense 2.4.4 under CoDel there are two parameters. There is target which defaults to 5 and interval which defaults to 100. Is there any merits to adjusting these?
-
- how do you typically go forward in tuning your pfsense?
- does hw.igb.fc_setting=0 actually exist?
-
@zwck said in Playing with fq_codel in 2.4:
hw.igb.fc_setting=0
Does not actually work on my Supermicro Atom 2758. I use "hw.igb.0.fc=0", which does exists when I run "sysctl -a".
-
@zwck - there are two main ways I'm aware of:
- Edit your loader.conf.local file
- Go to System --> Advanced --> System Tunables.
@kjstech - Yes, with very slow connections (low upload or download speeds) the target and limit may need to be increased to avoid excessive drops in the queue.
https://www.bufferbloat.net/projects/codel/wiki/Best_practices_for_benchmarking_Codel_and_FQ_Codel/
https://lists.bufferbloat.net/pipermail/bloat/2017-November/007975.html
http://caia.swin.edu.au/freebsd/aqm/patches/README-0.2.1.txtHope this helps.
-
@tman222
Hey, Thanks mate. i guess i am aware of both methodologies, i am more wondering how do you find the proper settings to type in there. I read throught, and played around with, https://calomel.org/freebsd_network_tuning.html this guide. But could not see any difference.Also for people who want to play around with flent:
quick installation guide for ubuntu 16+sudo apt update sudo apt upgrade sudo apt install git git clone https://github.com/HewlettPackard/netperf.git cd netperf sudo apt install texinfo sudo apt install iperf sudo apt-get install automake -y sudo apt install autoconf -y sudo apt install python-pip -y pip install netlib pip install cpp ./autogen.sh autoconf configure.ac > configure sudo chmod 755 configure ./configure --enable-demo make make install sudo add-apt-repository ppa:tohojo/flent sudo apt update sudo apt install flent flent rrul -p all_scaled -l 60 -H flent-london.bufferbloat.net -t no_shaper -o RRUL_no_shaper.png -
Hi @zwck
It's a lot of trial and error (i.e. testing) to see what works best for your use case(s). Keep in mind that a lot of the guides you will find are for tuning host computers and some of those suggestions may not work well for a firewall appliance.
One other site that I have gotten some helpful tuning info from has been the BSD Router Project, for example:
https://bsdrp.net/documentation/technical_docs/performanceHope this helps.
-
Is there any reason you folks can think of why when I run the flent rrul/rrul_noclassification, my download seems to top out at 40mb/s to netperf-west.bufferbloat.net. When I run "netperfrunner.sh" from the same host, i get the following:
flent:

script:
2018-10-10 08:59:19 Testing netperf-west.bufferbloat.net (ipv4) with 4 streams down and up while pinging gstatic.com. Takes about 60 seconds. Download: 150.21 Mbps Upload: 10.27 Mbps Latency: (in msec, 61 pings, 0.00% packet loss) Min: 29.343 10pct: 33.824 Median: 44.323 Avg: 45.461 90pct: 57.069 Max: 74.273I'm applying the limiter via floating rules on WAN. I'm using codel+fq_codel set to 390mb/s down and 19mb/s up.
I've seen some people incorporating their limiters via in/out pipe on the default lan allow rule - is there some consensus on which method is "best"? I've got a bunch of vlans off that interface - if i went this method, i'd need to include the in/out pipe on every default allow rule for each vlan?
thank you for all you've managed to figure out and explain to me thus far.
-
I asked about this as well. some posts up dthat explains it, its actually 4x40Mbps ~ 160 and 4x3 ~ 12 Mbps (when you start flent with the option --gui you can check total download and upload values)
Why it tops out at about half your speed limit is difficult to say, maybe hardware/line limitations from you or the host? I started setting up the codel params with extreme reduced speeds. i.e. 1gbit line limit, codel limiters set to 100Mbit. -
@tman222 said in Playing with fq_codel in 2.4:
Hi @zwck
It's a lot of trial and error (i.e. testing) to see what works best for your use case(s). Keep in mind that a lot of the guides you will find are for tuning host computers and some of those suggestions may not work well for a firewall appliance.
One other site that I have gotten some helpful tuning info from has been the BSD Router Project, for example:
https://bsdrp.net/documentation/technical_docs/performanceHope this helps.
I just quickly skimmed this section with the outcome:
changing :machdep.hyperthreading_allowed="0" -> 24% increased performance net.inet.ip.fastforwarding=1 (useless since freebsd11) hw.igb.rxd or hw.igb.txd -> decrease performance hw.igb.rx_process_limit=100 to -1 -> improvement, 1.7% max_interrupt_rate from 8000 to 32000 -> no benefit Disabling LRO and TSO -> no impact -
@zwck I don't get how that could be. Both tests use netperf, right? The two test outputs provided were from the same host. So odd.
-
@sciencetaco i probably don't understand you properly:
I think what you linked shows the same result - flent shows 150 down and about 10 up and your script output shows 150 down and 10 up
-
@zwck I think I overlooked the 4x multiplier on flent in your original reply,my bad. This satisfied my brain's need for clarification. thank you!!
-
At one level, I'm apologetic about the default rrul plot being so complicated. You get the most at a glance that way. You can certainly choose to output the totals plot instead, if that's what you want. My fear was that people would just look at that all the time instead of the more complicated one, and my other fear was that people wouldn't actually switch to using the gui to more fully analyze the data.
And my third fear was that people wouldn't use the other tests. You can test your
download or upload in isolation with either the tcp_download/tcp_upload test (simple) or do something more complicated like --te=download_streams=4 tcp_ndown . In the flent network I have not personally been able to stress the servers much past 100mbit, so here's YET ANOTHER TEST that goes to two servers:flent -s .02 -x -H flent-fremont.bufferbloat.net -H flent-newark.bufferbloat.net -H flent-fremont.bufferbloat.net -H flent-fremont.bufferbloat.net -t 'whatever' rtt_fair4be
I put in more detailed fine grain sampling (-x -s .02).
But I have a feeling you are running out of cpu/interrupts/context switches.
-
@zwck said in Playing with fq_codel in 2.4:
"hw.igb.rxd or hw.igb.txd -> decrease performance"
What were the hw.igb.rxd and hw.igb.txd values you tried? pfSense default is 1024 for both I think. -
btw: it would cheer me up if people would show their "before" plot, also. I should put one up of what my connection looks like without shaping on it.
I don't know how to make slow hardware faster... and if you encounter issues with shaping 300mbit, well, take a look at how much better things get if you just shape the upload, and call it a day. Can you still get 300mbit down without a shaper? Does latency improve if you just shape the out?
-
So, this is what my last comcast modem looked like, without shaping.
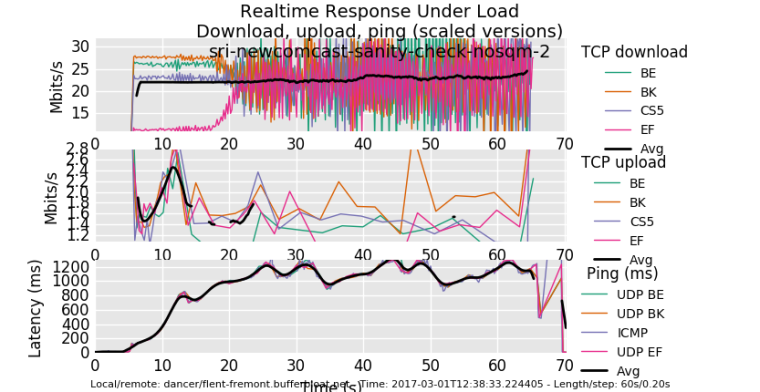
0_1539192524603_rrul_be-2017-03-01T123958.188746.sri_newcomcast_sanity_check_nosqm_2.flent.gz
See how long the red download flow takes to get to parity? 20 seconds. Thats because it started just slightly late, and could not catch up with the other flows. This is what happens to any new flow (like, um, dns or tcp or...) when you have a flow already eating the link and your RTT climbs to 1 sec....
The upload flows are almost completely starved (1sec RTT!).
-
using the squarewave test is fun too. Not doin that... But anyway, for comparison, I get about twice the upload performance and 15ms added latency on this hardware (an arm neon) running cake... and I'm running low on cpu here. (There's also other real traffic). Same cablemodem....
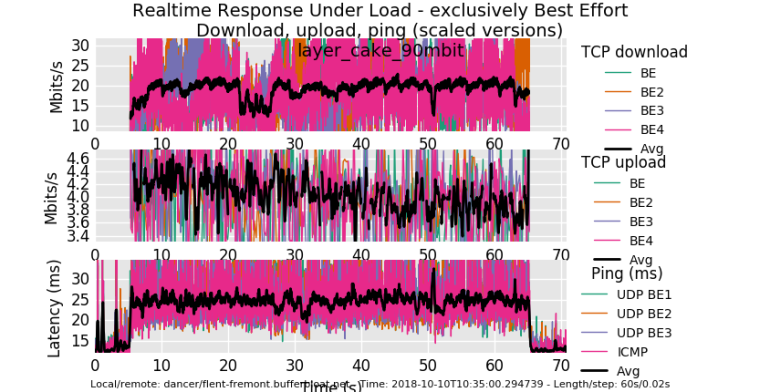
After i get off this call I'll kill the download shaper and see what happens... but I'm in a call while I was doing this and nobody noticed... :)!0_1539193422893_rrul_be-2018-10-10T103500.294739.layer_cake_90mbit.flent.gz
-
ok, glutton for punishment. Shaped up only. I sure hope the rest of the world isn't as miserably overbuffered as comcast's CMTSes are.....
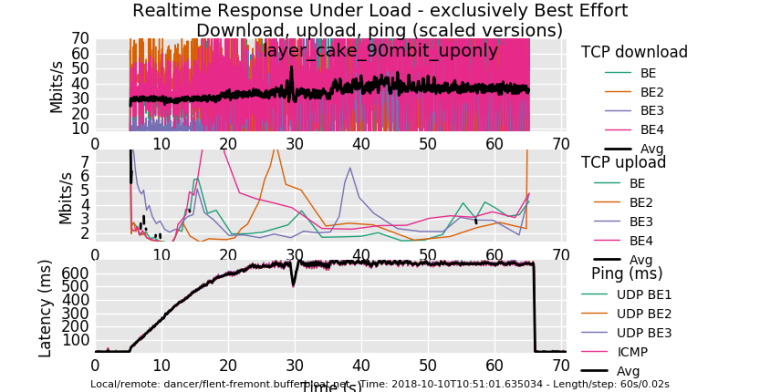
0_1539194140099_rrul_be-2018-10-10T105101.635034.layer_cake_90mbit_uponly.flent.gz
I campaigned hard to get the cable industry to cut their CMTS buffering to a 100ms TOPs. So we're still suffering. pie on the modem is not enough. cheap arm and x86 hardware is not enough....