Playing with fq_codel in 2.4
-
@dtaht pfsense runs basremetal on A1SRi-2758F, it can easily handle my speed I think lol.
edit: i downloaded ubuntu from windows store, ill report back to see if anything improves -
@dtaht yeah so that didn't work...
-
@gsakes try the ack-filter option on your outbound cake instance. try turning on ecn on your src and destination tcp stacks. While I'd doing flent featureitus, you can also capture cake and fq_codel stats from the gw.
if you set up ssh authorized_keys to let you get there without a login. Some things (sigh) require root, so you setup your .ssh/config as I do with:
Host gw*
User rootHost apu*
User root--te=qdisc_interfaces=enp1s0 --te=qdisc_stats_hosts=hosta
it would be good to one day be able to poll a pfsense ipfw instance this way also.
You can monitor/plot ongoing cpu_stats on the gw with
--te=cpu_stats_hosts=hostA,hostB,hostC # and if you allow ssh to localhost monitor
local stuff too.While I'm at it you can also change congestion control algorithms with --te=CC=reno # for example. I don't have bbr universally or publically deployed, linode doesn't build it in. Note, we have no way of verifying except by eyeball if we actually switched CC algos. I can certainly see (after being trained by flent) what reno, cubic, cdg, and bbr "look like"). Perhaps we need to turn an AI on these graphs! :)
I just mentioned that vm's network can get overburdened. so there's a
--te=ping_hosts=hosta,hostb,hostcinstead of just watching ping in another window. That's lowcost.
A full list of the admittedly underdocumented and sometimes buggy additional test data collection mixins is in the flent/tests/*.inc. I do note that by default we try to make flent not heisenbug the tests by hitting a cpu burden or bandwidth limit elsewhere. For example, remotely polling for cake stats is very intensive at -s .02 and does seriously impact the performance of a low end openwrt router, so I wrote a tool in c that does it way faster - (but it broke on a recent release of iproute) - and it is still intensive so beware.
pull requests for better documentation, blog posts about the joy of flenting your network, gladly accepted. :)
I do tend to script this stuff with a huge variable of all the extra tests I run, toke uses the "batch" facility also built into flent. If you like [ini] file formats, go for "batch".
There's also tcpdump, tcptrace -G, and xplot.org. I DO - when I spot a weirdness - fire off a tcpdump while flenting and look at the real capture with wireshark or xplot.org. There's a good java version of xplot, also. Doing that tcpdump/xplot.org plot of your before/after test is quite informative, you can see all the carnage going on in a tcp flow even more directly (and we used tcpdump a lot to verify that flent's sampling and stats were indeed correct - but tcpdump (even with using -s 128) is very cpu intensive and often you want to be dumping at the server side of the thing...)
-
@strangegopher "didn't work". This is the -s .02 test? If so, it's pretty normal to show that your upload throughput is very spotty over 20ms interval at this low bandwidth. The default sampling rate of -s .2 "hides" that. see nyquist theorem. This is another one of my rants - humans thing of bandwidth as data/interval, and set the interval to seconds. Where, here, we just set it to data/20ms and the results got "interesting" - you got a lot more detail on the download sawtooth.
For the upload... (nyquist bit us again)...
Arguably the plot idea itself is wrong here. We should show dots or crosses rather than connect the dots with lines when the data rate is this low, or rework how the average is smoothed.
( I really am trying to encourage folk to post their .flent.gz data so I can verify you did it right).
-
@gsakes try that --socket-stats test without -s .02
-
@strangegopher having a fat cpu may or may not help on inbound shaping. you are bound by the context switch latency which is 1000s of clocks on "modern" intel hardware. The (paper) Mill computer cpu can do it in 5. If we could do it in offloaded hardware, cool.
You are also bound by clock resolution, interrupt coalescing, and numerous other potential difficulties.
I regard the biggest remaining technical problem in the whole bufferbloat effort is doing inbound shaping cheaply enough at high rates, to eliminate the "badwidth" folk are providing at these speeds (a recent test of 5G showed 2 seconds of buffering).
I'd have preferred the core algos just roll out to more vendor hardware, and pursued political solutions.
I'd hoped that outbound shaping would get more fixed by (one example) having a programmable completion interrupt in the ethernet/gpon/cable chip - which essentially makes it "free" for bql derived systems (I still haven't found the intel chipsets that do it), or that ISPs would get clue and demand a better shaper + fq_codel from their CMTS/BRAS/ENODE-B/GPON vendors on their side so we wouldn't have to inbound shape at all. It's just a programmable interrupt per subscriber to do it right in hardware on outbound in their case. Totally doable. And profitable for whatever chipmaker/vendor gets there first. http://jvimal.github.io/senic/
'cause fixing the internet on my dime and time costs. (but do you say "no" when vint cerf, jim gettys, esr, paul vixie and dave reed tell you you're the only guy that can make even a proof of concept work? (cerowrt). I couldn't... and I was thoroughly POed about it in the first place, as while I was (retired) in nicaragua, my wifi "upgrade" from g to n one summer for my 14km long link to the internet failed completely during the (2 month long) rainy season - when there was nothing to do but surf the internet. So great. it's 8 years later and I can finally get a decent wifi link to the boonies down there, and I keep thinking about retiring again.... sailing down there... never logging in again... reading books... writing one... surfing a lot...)
As it happens, I have what I think is a better algorithm for inbound policing (It's called "bobbie"), but I abandoned the work when early versions of cake were 40% faster than fq_codel was (cake is now twice as slow as htb + fq_codel due to featureitus), and decided to focus on fixing wifi as the most bang for what little bucks I had left, and as something I knew would work. Even with grant money for it, proving if bobbie could work was going to take a long time. I published (could have patented) the idea behind that in the hope that someone else would take up the work - as (for example) the fq_codel work for bsd was taken up by a team in australia, and other volunteers keep pushing more, good stuff out, fixing bugs, and figuring out how to deploy things.
you can also look at some of the work in the conex working group of the ietf.
Anyway, I don't know why you are only getting 120mbit down on 150mbit config on a beefy box running an OS I don't know a lot about. Tuning the limiter is the last idea I have... trying to up the target and interval in codel perhaps...
-
there has been a windows version of flent at various points in its existence. getting all the dependencies right has been hard, so it's mostly used on linux and osx. yes, having a windows version packaged up would be good. There was also an effort to make it work over the web at one point (flent's output is json, and with a good json library for plotting the prototype looked good. We needed a backend database and some other stuff)
def goin to bed
-
@dtaht Porting it into pfsense as a package would be nice too.
-
@pentangle It's in openbsd... please point a freebsd packager at it. https://repology.org/metapackage/flent/versions
-
@dtaht Unfortunately I'm one of those Windows experts who has little or no knowledge of BSD aside from what the GUI gives. I'll leave that to someone competent in it.
-
@dtaht said in Playing with fq_codel in 2.4:
@pentangle It's in openbsd... please point a freebsd packager at it. https://repology.org/metapackage/flent/versions
ahh, this would be ideal. The only other hardwired hosts I have to test from are either raspberry pi or an ancient mac mini - pretty sure the mini is the reason my flent tests show such a different picture than when i test using netperf on the pfsense router.
here was my latest: charter can't tell me what i'm provisioned for, so i don't know if i have 400mb or 300mb, so i adjusted my shaper down to 290 from 390:

-
@sciencetaco Is that a live link? What's your "before" result? That would give you an exact idea as to what you are getting from them, and an even more exact would be running the tcp_download test instead of rrul. What's a dslreports on a before setting? You can try watching your link quality on the cablemodem itself also. Bad SNR there can be a problem.
(helps to have the flent.gz files)
Still don't know why you aren't getting close to the set rate. (can the limiter burst size be tuned?) Another thing to try is setting the codel algo to kick in (for test purposes) much later, like target 30ms, but I'm still pointing fingers at the limiter/cpu context switch latency, out of cpu, etc.........
-
Going back to my alice's restaurant quote (which is an arcane bit of americana - you can lose 20 minutes to this https://www.youtube.com/watch?v=W5_8U4j51lI&start_radio=1&list=RDW5_8U4j51lI , easily, it's a thanksgiving tradition here)
(I think y'all are mostly in england or the continent?)
and being sad about how few views the various core bufferbloat presos jim, I and others have done ( https://www.youtube.com/results?search_query=bufferbloat ) - even the highly entertaining one by stephen hemminger ( https://www.youtube.com/watch?v=y5KPryOHwk8&t=828s ) only has 3k views (take 10 minutes out of your life, it's great, but not as great as alice's restaurant)
and seeing https://www.youtube.com/results?search_query=fq_codel+pfsense have 30k views...
I'd love to try to get some of what we've discussed and solved above with flent into a script and talk with a good presenter like lawrence or Mark Furneaux to get more folk to pay attention....
video is not my forte. But you can get anything you want at alice's restaurant.
-
@dtaht said in Playing with fq_codel in 2.4:
@sciencetaco Is that a live link? What's your "before" result? That would give you an exact idea as to what you are getting from them, and an even more exact would be running the tcp_download test instead of rrul. What's a dslreports on a before setting? You can try watching your link quality on the cablemodem itself also. Bad SNR there can be a problem.
(helps to have the flent.gz files)
Still don't know why you aren't getting close to the set rate. (can the limiter burst size be tuned?) Another thing to try is setting the codel algo to kick in (for test purposes) much later, like target 30ms, but I'm still pointing fingers at the limiter/cpu context switch latency, out of cpu, etc.........
link is live, only traffic is 1 streaming client.
I disbled my limiters and ran a few tests, as you suggested. Here are the outputs:
tcp_down limited:

rrul46 without a limiter:

tcp_down no limit:

i really appreciate everyone that's taken the time to take a look at my output and offer suggestions. thank you all.
flent .gz files: (4 of them in the tarball)
0_1539269433292_flent.tar -
@sciencetaco your limited and unlimited tcp_download plots are essentially the same. latency is good. Sure you turned it off? Otherwise your latency is not bad
Otherwise the fact that four flows do a bit better than one implies that we have a flow per CMTS channel (take a look at your cmts config and see how many channels are operational), or a limit on my tcp stack on this server (I usually test with four flows) or your receive window... (which btw, I'd not considered before on this thread - I can't do much testing of the real world at real rtts outside the lab. At short RTTs I can certainly do 1gb on various hardware)
There's some hint that powerboost might be on with charter (first 20 sec solid then a major drop (yea, optimizing for speedtest)).
but heck, rather than fiddle with the tcp config, try killing it with a hammer. try using
--te=download_streams=16 tcp_ndown
with the limiter on and off. Cool that you just tested both ipv6 and ipv4 at the same time, also. I kind of hope we end up with a "superscript" that has all 10 tests nicely done in a row... against someone elses server.
The totals plot is much easier to deal with.
thx for sharing the flent data! However I meant to go to bed about 8 hours ago... bbl
-
@ dtaht Here are the results with ack filter on the outbound interface, and ecn enabled:

-
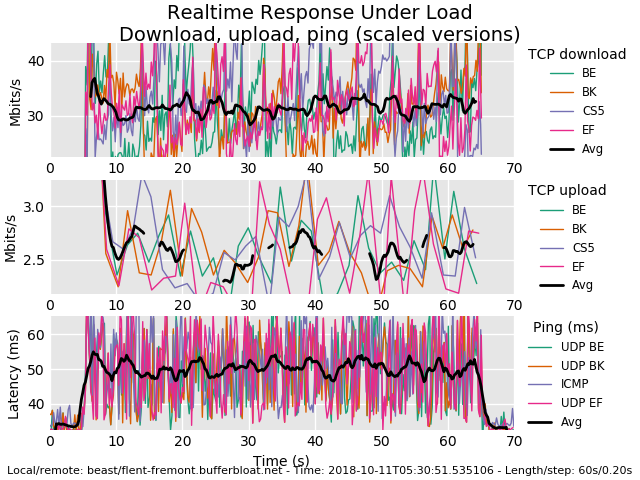
@gsakes That result is a thing of beauty. If only the whole internet worked like that.
-
@dtaht lol - i must be reading that wrong - that result is actually better?
-
@gsakes well post the flent files? and tc -s stats? to my eye - tcp up/download occilations are less, bandwidth ruler flat, uplink bandwidth improved by a few percent, and induced latency cut from 5ms to about 4. Love to do a comparison plot.
Another flent trick is you can lock the scaling to one plot when flipping between them, so your first plot had more occilations than you see here. I think... let me scroll back
5 years of work for those few percentage points compared to the orders of magnitude win fq_codel was... but I'll take it, and frame it.
-
@dtaht Yes- frame it - it was worth it, no - really. Ok, here's without ack-filter, and ecn, I'll post those flent files next:
