Playing with fq_codel in 2.4
-
@tman222 said in Playing with fq_codel in 2.4:
I'm very glad you were able to confirm the proper setup. I had postulated something similar a few post back up in this thread based on what I had read about Limiters/Dummynet:
https://forum.netgate.com/topic/112527/playing-with-fq_codel-in-2-4/635You provided very nice information in that post. Actually, I tried your RR+Codel setup a long time ago to confirm a specific behaviour I saw with our fq_codel implementation. Regarding the differences to fq_codel (in addition to the quantum value you mentioned and regardless of the internal implementation differences), FQ-CoDel has two groups of sub-queues. One group for new (and very short-life like a DNS query) flows and other for old flows. New flows sub-queue has higher priority than old flows. This prioritisation improves network response (RFC8290 explains that very clearly).
@tman222 said in Playing with fq_codel in 2.4:
Here's one interesting thing though (and a question that I'm still trying to answer): In my case I have a 10Gbit LAN feeding into a 1Gbit WAN link. If I enable Codel on the limiter's child queues I see slightly better performance than just enabling fq_codel and leaving AQM alone on the queues (i.e. just going with the default Tail Drop).
That's so weird. Choosing CoDel or Tail Drop with fq_codel should not change the performance at all. In fact, Tail Drop or CoDel enqueue/dequeue code is not be executed at all when fq_codel scheduler is configured (fq_codel has sperate enqueue/dequeue functions).
@tman222 said in Playing with fq_codel in 2.4:
Now, is it the case that with Codel enabled on the child queues, some of the packets being received would already be dropped before reaching the fq_codel scheduler and its own set of queues? In other words there are two stages of AQM occurring? Or is Codel AQM on the child queues ignored when fq_codel is enabled?
The answer is Codel AQM on the child queues ignored when fq_codel is enabled. So, CoDel will not drop any packet in this setup and the buffer space of the child queue will not be used to store packets at all.
@tman222 said in Playing with fq_codel in 2.4:
I definitely agree that it is not necessary to have Codel enabled on child queues since fq_codel handles the AQM with its own set of queues. However, could adding the Codel to child queues help when dealing with high speed (high pps) networks with a slower uplink? Or am I just creating additional CPU overhead and no benefit?
As you mentioned, fq_codel uses its own queues. These queues are accessible only by fq_codel instances. As mentioned in ipfw(8) man page, you can configure the number of these queues using fq_codel flows parameter. I don't think you are creating additional CPU overhead by enabling CoDel.
Sorry if you mentioned that in your early post (so many posts) but I am curious about how do you measure your firewall performance when testing fq_codel. Do you use a local testing environment? Additionally, have you tried to use just CoDel, PIE or Tail Drop with traffic shaping (limiter) and see how many pps can be achieved? That is important to see which part causes a reduction in performance.
-
Hi @rasool - thanks for getting back to me. After reading your response, I decided to start over once more and followed your steps - i.e. I created child queues but did not enable Codel this time. After doing some initial testing, I'm happy to report that performance was similar to what I had before, so indeed it seems that Codel on the child queues is just being ignored. The only thing that would speak against that is that I found myself increasing the queue size (from the default 50) when I originally had Codel enabled on the child queues, and this did improve performance.
I also had one other quick question for you: Why are the child queues necessary in the first place if fq_codel has its own set of queues? Put another way, why can't the Limiter be applied directly to the firewall rules instead of the child queues underneath the limiter?
Thanks again for all your help, I really appreciate it.
-
@tman222 Thanks for posting your question. Was wondering the same but hadn't got around to asking.
-
@tman222
Thank you for testing and confirming that. Enabling Codel for child queues and increasing queue size should not improve the performance of fq_codel as well, similar to pipe/limiter case beacuse fq_codel bypass dummynet queues.@tman222 said in Playing with fq_codel in 2.4:
I also had one other quick question for you: Why are the child queues necessary in the first place if fq_codel has its own set of queues? Put another way, why can't the Limiter be applied directly to the firewall rules instead of the child queues underneath the limiter?
@tman222 and @markn6262
A simple answer is because of current pfSense WebUI you need to create "child" queues. You can use fq_codel with just limters if the WebUI configures the pipe to use the created schdulare. Here is an example of how to use fq_codel without creating a queue (I haven't test that though).
ipfw pipe 1 config bw 800Mb sched 1 ipfw sched 1 config pipe 1 type fq_codel target 5ms interval 100ms quantum 1514 limit 1024 flows 1024 ecnBasically, just sched <sched number> should be added to pipe configuration.
Please note that creating a pipe will also create a queue internally because dummynet needs a flowset to interact with packets. There is no way to send packets directly to fq_codel schdeuler. -
@Rasool, @tman222 , and @markn6262
I mentioned this in a previous post but what I have found is that with lower configured mbit pipes, latency is higher under load when a child queue is not used. At 90mbit, latency is higher when not using a child queue and just using the limiter pipe - at 800mbit everything is basically the same with or without a configured child queue. The only changes I make between tests are to increase/decrease the pipe bandwidth and/or remove/add child queues and change floating rules to reflect in/out limiter/queue - the firewall is rebooted between tests to make sure all states are flushed and rules.limiter is reloaded properly. I'm not sure if the aforementioned latency behavior is specific to pfSense 2.4.4 or if this is also the case in vanilla FreeBSD 11.2. While the limiter does technically work with just a pipe and fq-codel, it appears to currently be more performant using a child queue.
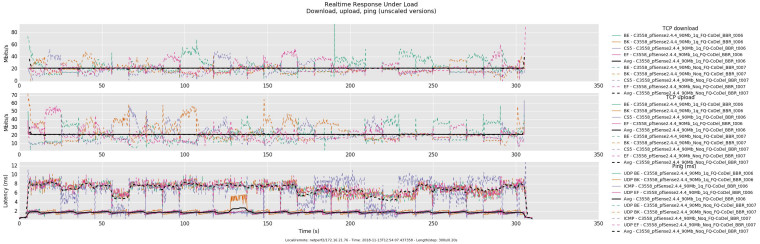
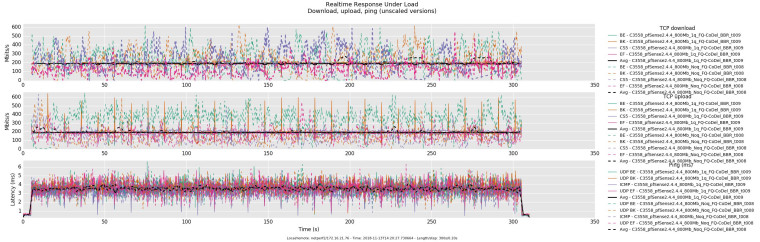
Edit 1 - Adding tested limiter configs
No Child Queue - 90mbit
pipe 1 config bw 90Mb droptail sched 1 config pipe 1 type fq_codel target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 noecn pipe 2 config bw 90Mb droptail sched 2 config pipe 2 type fq_codel target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 noecnChild Queue - 90mbit
pipe 1 config bw 90Mb droptail sched 1 config pipe 1 type fq_codel target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 noecn queue 1 config pipe 1 droptail pipe 2 config bw 90Mb droptail sched 2 config pipe 2 type fq_codel target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 noecn queue 2 config pipe 2 droptailNo Child Queue - 800mbit
pipe 1 config bw 800Mb droptail sched 1 config pipe 1 type fq_codel target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 noecn pipe 2 config bw 800Mb droptail sched 2 config pipe 2 type fq_codel target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 noecnChild Queue - 800mbit
pipe 1 config bw 800Mb droptail sched 1 config pipe 1 type fq_codel target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 noecn queue 1 config pipe 1 droptail pipe 2 config bw 800Mb droptail sched 2 config pipe 2 type fq_codel target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 noecn queue 2 config pipe 2 droptail -
The other thing of note is that pfSense appears to use ipfw to configure the pipes/sched/queue but traffic is sent to "dnpipe" using a patched version of pf and not via ipfw rules. So we're not exactly comparing apples to apples with @Rasool.
-
@uptownvagrant said in Playing with fq_codel in 2.4:
At 90mbit, latency is higher when not using a child queue and just using the limiter pipe
Could you please increase pipe size for No Child Queue - 90mbit experiment and rerun the same test? I feel like fq_codel was not working in that configuration because @90mbit and 50pkts queue size and DropTail, the maximum queueing delay is around 6.5ms. For 800mbit, queueing delay is less than 1ms so you should not see a large queuing delay even without fq_codel.
I think the maximum queue size you can set is 100 by default. You can increase that limit using sysctl net.inet.ip.dummynet.pipe_slot_limit -
I reran the tests using a 90mbit pipe and changing the queue size to 15 slots (delay approx. 2ms) and 100 slots (delay approx. 13.5ms). As you suspected, it does appear that the FQ-CoDel scheduler is not being executed when just a pipe, without an associated queue, is used in pfSense.
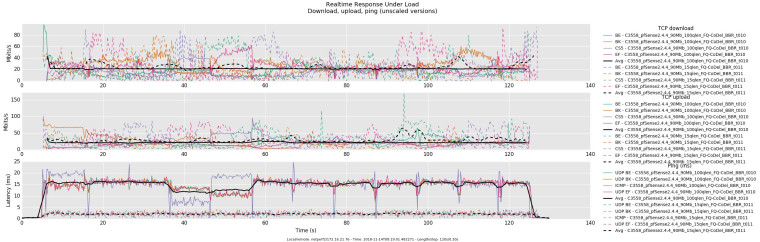
And here is with 1 child queue with a queue size of 1000 to show that FQ-CoDel is properly handling the queue and not the Dummynet directive.
Confirming ipfw limiter config:
pipe 1 config bw 90Mb queue 1000 droptail sched 1 config pipe 1 type fq_codel target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 noecn queue 1 config pipe 1 queue 1000 droptail pipe 2 config bw 90Mb queue 1000 droptail sched 2 config pipe 2 type fq_codel target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 noecn queue 2 config pipe 2 queue 1000 droptailConfirming pf rules are using queues and root pipes:
[2.4.4-RELEASE][admin@dev.localdomain]/root: pfctl -vvsr | grep "FQ-CoDel" @84(1540490406) match in on ix0 inet all label "USER_RULE: WAN in FQ-CoDel" dnqueue(2, 1) @85(1540490464) match out on ix0 inet all label "USER_RULE: WAN out FQ-CoDel" dnqueue(1, 2) [2.4.4-RELEASE][admin@dev.localdomain]/root:Confirming slot limit:
[2.4.4-RELEASE][admin@dev.localdomain]/root: sysctl -n net.inet.ip.dummynet.pipe_slot_limit 1000 [2.4.4-RELEASE][admin@dev.localdomain]/root: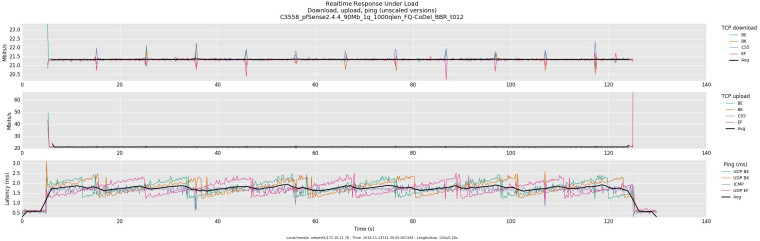
Edit 1: Adding flent.gz files.
0_1542313536664_rrul-2018-11-14T081901.482271.C3558_pfSense2_4_4_90Mb_100qlen_FQ-CoDel_BBR_t010.flent.gz
0_1542313547047_rrul-2018-11-14T082439.469459.C3558_pfSense2_4_4_90Mb_15qlen_FQ-CoDel_BBR_t011.flent.gz
0_1542313567879_rrul-2018-11-14T113005.867344.C3558_pfSense2_4_4_90Mb_1q_1000qlen_FQ-CoDel_BBR_t012.flent.gz -
@uptownvagrant
Thank you for confirming that. So that means if CoDel+FQ_CoDel limiter is selected directly (not the child queue) in floating rules, the traffic will be controlled by CoDel algorithm.I can say, to avoid any possible problems when configuring fq_codel using current WebUI, the limiter child queue method should be used (with DropTail selected for both the limiter and child queue).
Now we have to figure out which part(s) causes performing issues. I think we have to compare the results (pps, CPU %utilisation, throughput) when using limiter with DropTail+FIFO (limiter only) and DropTail+FQ_CoDel (using child queue method).
-
@uptownvagrant said in Playing with fq_codel in 2.4:
I reran the tests using a 90mbit pipe and changing the queue size to 15 slots (delay approx. 2ms) and 100 slots (delay approx. 13.5ms). As you suspected, it does appear that the FQ-CoDel scheduler is not being executed when just a pipe, without an associated queue, is used in pfSense.
I am really loving watching y'all go at this, trying different things, fiddling with params, etc - coming up with things I'd have never thought of!
I have to admit, that I'd really like *.flent.gz files to to tests like these. In . particular, it's obvious to my eye, you are using BBR, due to the drop every 10 sec.
This comparison plot, though, was awesome.
In this work, you are exposing a BBR pathology, where 4 flows start at exactly the same time, all go into their PROBE_RTT mode all at the same time, and you can see things go wrong at T+35 on the non-fq_codel case where one flow actually grabs the right bandwidth and the other flows do not, then it gets a mis-estimate of the queue and comes back too strong 10sec later.
Which doesn't happen in the fq_codel case. We get good ole sawtooths, and no pathologies.
(though I'd love to be getting drop statistics and other stuff, I imagine packet loss is pretty high as BBR is kind of confused). I gotta go repeat this style test on my own testbed!
However, well, I do tend to stress rrul is a stress test, and applications really shouldn't be opening up 4 flows at the same time to the same place. BBR would hopefully behave much better were the starts staggered by 200ms.
Still, joy! no pathologies, low latency. Wish I had the .flent.gz file.... :)
And a huge welcome to Rasool. I'm just amazed he did such a great job with fq_codel working from the RFC alone.
-
I have to note that things seem to be looking very good here.
But, we had a huge problem with nat and UDP and a bug report filed on that a few weeks back. Is that fixed by getting the ipfw pipe right and being able to swap stuff out in flight?
-
I may be going over old ground here, but can I ask a set of relatively straightforward questions that would help to solidify my ideas of how FQ_CoDel integrates and interoperates within pFsense:
-
I understand that FQ_CoDel is designed to generically decrease latency by prioritising smaller packets, but what is the best way to prioritise individual streams of these packets?
I see 2 distinct options within pFsense:
A - Create interface rules to shape traffic that would sit alongside the "limiter" rules for FQ_CoDel
B - Create several individual queues within a limiter, weight them accordingly, and assign floating firewall rules to the relevant types of traffic rather than a catch-all floating rule
Which is the most appropriate method to use? (and can you even use A?) -
With other traffic shaping methods there was an argument that a smaller queue length and getting the client to drop packets and retransmit instead was a preferable outcome for bufferbloat than to have a longer queue and manage that queue. Is this still the case with FQ_CoDel? and if so, is there an algorithm to use for determining close to the optimum queue length?
-
When setting bandwidth limits within pFsense and then testing, it appears that the small bandwidth reduction required to ensure the limiter operates correctly has already been calculate (e.g. when we have a WAN link that speedtests at 105 Mbit/s and we set it at 100 Mbit/s in the limiter, we get ~96 Mbit/s) - is this inherent within FQ_CoDel, pFsense, or both? should we still aim to do our own haircut of the observed line speed when setting up pFsense? and if it's calculated-in on either of FQ_CoDel/pFsense, how do we (or even should we) optimise that figure to have the least possible bandwidth reduction whilst still having an operable FQ_CoDel?
Thanks,
Mike. -
-
@pentangle said in Playing with fq_codel in 2.4:
I may be going over old ground here, but can I ask a set of relatively straightforward questions that would help to solidify my ideas of how FQ_CoDel integrates and interoperates within pFsense:
- I understand that FQ_CoDel is designed to generically decrease latency by prioritising smaller packets, but what is the best way to prioritise individual streams of these packets?
I see 2 distinct options within pFsense:
A - Create interface rules to shape traffic that would sit alongside the "limiter" rules for FQ_CoDel
B - Create several individual queues within a limiter, weight them accordingly, and assign floating firewall rules to the relevant types of traffic rather than a catch-all floating rule
Which is the most appropriate method to use? (and can you even use A?)
It is my understanding that the implementation of FQ-CoDel does not take into account dummynet child queue weight. If you are looking to prioritize certain flows using dummynet, QFQ would be my first choice currently. I would then use floating rules to place flows into the appropriate queues very similar to how you would configure ALTQ. You could use CoDel on the weighted child queues or you could use a different AQM and calculate how much buffering you want. I'd be interested in what @Rasool would recommend.
- With other traffic shaping methods there was an argument that a smaller queue length and getting the client to drop packets and retransmit instead was a preferable outcome for bufferbloat than to have a longer queue and manage that queue. Is this still the case with FQ_CoDel? and if so, is there an algorithm to use for determining close to the optimum queue length?
The goal of FQ-CoDel is to maintain the internal queue size per flow and thus it does not adhere to the "queue" setting of ipfw/dummynet.
- When setting bandwidth limits within pFsense and then testing, it appears that the small bandwidth reduction required to ensure the limiter operates correctly has already been calculate (e.g. when we have a WAN link that speedtests at 105 Mbit/s and we set it at 100 Mbit/s in the limiter, we get ~96 Mbit/s) - is this inherent within FQ_CoDel, pFsense, or both? should we still aim to do our own haircut of the observed line speed when setting up pFsense? and if it's calculated-in on either of FQ_CoDel/pFsense, how do we (or even should we) optimise that figure to have the least possible bandwidth reduction whilst still having an operable FQ_CoDel?
There are a lot of variables you'll need to identify to get to your answer but the overarching goal here is that your handoff device, as much as possible, should handle the buffering/dropping behavior of traffic if you want to maintain the lowest latencies - it is generally agreed on that you will have to sacrifice some bandwidth to maintain low latencies in our current environment. Your example of 105Mbit, I'm assuming this is a symmetric link? I'm assuming your pfSense device is connected to the next WAN hop at GigE? What is your test that shows you are only getting 96Mbit when you set the limiter bandwidth to 100Mbit? I ask because in my experimenting, if I use the default FQ-CoDel scheduler settings, I would be able to get every bit of the 100Mbit you set, and a bit more, If I have enough flows and pps through the CPU. In my experimenting, using the hardware and configuration that I have tested, If I have a circuit that starts buffering at my ISP after 100Mbits, and I'm using a GigE connection to interface, I'll need to set the limiter to 90Mbit, FQ-CoDel default settings, in order to keep utilization under 100Mbit almost all of the time. This is based on very heavy bandwidth contention from multiple clients, to multiple servers, across pfSense - think multiple machines doing flent RRUL tests simultaneously. So I'm testing anticipated worst case scenario in my environment, think public access Wi-Fi with little to no filtering, but you may have identified that your worst case scenario is just a few clients with a couple of heavy TCP flows at a time. In your case you may be able to set your limiter closer to the point where you ISP starts buffering.
Even for the lay person like myself that likes tinkering, I've found a lot of value from experimenting and reading through RFC 8290 and "Dummynet AQM v0.2 – CoDel, FQ-CoDel, PIE and FQ-PIE for FreeBSD’s ipfw/dummynet framework". I also feel like we've been privileged to have the support of @dtaht and @Rasool here in our own little corner of the Internet - I know it has greatly helped my understanding.
- I understand that FQ_CoDel is designed to generically decrease latency by prioritising smaller packets, but what is the best way to prioritise individual streams of these packets?
-
@dtaht I've edited my post and added the flent.gz files.
-
@dtaht Unfortunately the NAT+limiter+ICMP bug is still a thing. It appears that any scheduler triggers the bug so it's not specific to FQ-CoDel - we just happened to stumble upon it in our FQ-CoDel tinkering.
-
@uptownvagrant said in Playing with fq_codel in 2.4:
It is my understanding that the implementation of FQ-CoDel does not take into account dummynet child queue weight
Is this something that's likely to change in future? or is it a design limitation when trying to forklift FQ_CoDel into pFsense?
If you are looking to prioritize certain flows using dummynet, QFQ would be my first choice currently.
How would I achieve this within a pFsense GUI? I don't want to drop to the CLI if I can help it (and i'm sure the vast majority of pFsense users would agree).
Your example of 105Mbit, I'm assuming this is a symmetric link? I'm assuming your pfSense device is connected to the next WAN hop at GigE? What is your test that shows you are only getting 96Mbit when you set the limiter bandwidth to 100Mbit? I ask because in my experimenting, if I use the default FQ-CoDel scheduler settings, I would be able to get every bit of the 100Mbit you set, and a bit more, If I have enough flows and pps through the CPU. In my experimenting, using the hardware and configuration that I have tested, If I have a circuit that starts buffering at my ISP after 100Mbits, and I'm using a GigE connection to interface, I'll need to set the limiter to 90Mbit, FQ-CoDel default settings, in order to keep utilization under 100Mbit almost all of the time.
The link in question is a Virgin Media cable connection at one of my customer sites - it speed tests from www.speedtest.net at 105Mbit/s without shaping, but when I set it at 100Mbit/s it gives me 96Mbit/s through speedtest.net - I realise that site is not 100% brilliant at giving results, but in this case these results are repeatable, and I was just concerned as to whether the algorithm was robbing me of the other 4Mbit/s in order to perform the 'haircut' within itself or whether I was just seeing an anomaly.
I have a 300Mbit/s / 50Mbit/s FTTP connection here at home and that gives me consistently 305 Mbit/s and 52 Mbit/s with the shaper off, and when I set it at 300 and 50 I get 290 and 45 - these are consistent with what I'm seeing from the Virgin line at the customer, so the question really was whether pFsense/FQ_CoDel was designed so that I can run a speedtest.net, take the raw measurements from that and plug it into the pFsense limiters and it'd perform it's own 'haircut' internally, or whether I was still required to take ~90% of the speed shown and plug that into the limiters instead?I echo your thanks for the support of @dtaht and @Rasool and thanks for your own contribution!
-
@pentangle said in Playing with fq_codel in 2.4:
@uptownvagrant said in Playing with fq_codel in 2.4:
It is my understanding that the implementation of FQ-CoDel does not take into account dummynet child queue weight
Is this something that's likely to change in future? or is it a design limitation when trying to forklift FQ_CoDel into pFsense?
I appears to be a limitation of FQ-CoDel currently. If you look at section 6 and 7 of RFC 8290 it is discussed.
If you are looking to prioritize certain flows using dummynet, QFQ would be my first choice currently.
How would I achieve this within a pFsense GUI? I don't want to drop to the CLI if I can help it (and i'm sure the vast majority of pFsense users would agree).
This can be done in the GUI now but is off topic here. If you create a new post in the traffic shaping forum and tag me I will share what I have done a bit of testing on.
Your example of 105Mbit, I'm assuming this is a symmetric link? I'm assuming your pfSense device is connected to the next WAN hop at GigE? What is your test that shows you are only getting 96Mbit when you set the limiter bandwidth to 100Mbit? I ask because in my experimenting, if I use the default FQ-CoDel scheduler settings, I would be able to get every bit of the 100Mbit you set, and a bit more, If I have enough flows and pps through the CPU. In my experimenting, using the hardware and configuration that I have tested, If I have a circuit that starts buffering at my ISP after 100Mbits, and I'm using a GigE connection to interface, I'll need to set the limiter to 90Mbit, FQ-CoDel default settings, in order to keep utilization under 100Mbit almost all of the time.
The link in question is a Virgin Media cable connection at one of my customer sites - it speed tests from www.speedtest.net at 105Mbit/s without shaping, but when I set it at 100Mbit/s it gives me 96Mbit/s through speedtest.net - I realise that site is not 100% brilliant at giving results, but in this case these results are repeatable, and I was just concerned as to whether the algorithm was robbing me of the other 4Mbit/s in order to perform the 'haircut' within itself or whether I was just seeing an anomaly.
I have a 300Mbit/s / 50Mbit/s FTTP connection here at home and that gives me consistently 305 Mbit/s and 52 Mbit/s with the shaper off, and when I set it at 300 and 50 I get 290 and 45 - these are consistent with what I'm seeing from the Virgin line at the customer, so the question really was whether pFsense/FQ_CoDel was designed so that I can run a speedtest.net, take the raw measurements from that and plug it into the pFsense limiters and it'd perform it's own 'haircut' internally, or whether I was still required to take ~90% of the speed shown and plug that into the limiters instead?If you're looking to tune your limiter to give the best speedtest.net result you certainly can set the bandwidth higher but FQ-CoDel won't necessarily behave the way you hope when additional flows are thrown at it during real world usage. You're really not being robbed of 4Mbit/s because your not having to recover from your ISPs buffers. You may be able to burst without the limiter but you're paying for it and chances are you'll notice it in your interactive flows when there is contention.
Here's a note from Dave Taht a while back that illustrates the point. He's responding to a Flent RRUL test I ran against one of his netservers on the US West Coast. Without the limiter enabled, this particular circuit, FiOS aka FTTP, was one that I could squeak out above 50Mbps according to dslreports.com/speedtest but there was buffering and recovery happening...
@dtaht said in Playing with fq_codel in 2.4:going back to the fios example earlier. having fq_codel shaping at 48mbit appears to get more bandwidth than fios with 120ms worth of buffering at 50mbit does. Why? You get a drop, it takes 120ms to start recovery, you get a drop at the end of that recovery and the process repeats. Someone tell FIOS that engineering their fiber network to speedtest only works for 20 seconds.....
It's kind of hard to see at this resolution but the green line's median and whiskers are locked solid at 48mbit while the other... (btw, I should go pull the actual data transferred out of flent, I didn't, but you can't actually trust it due to 120ms worth of occilation, anyway, but improved bandwidth here is real. As is the lowered latency.
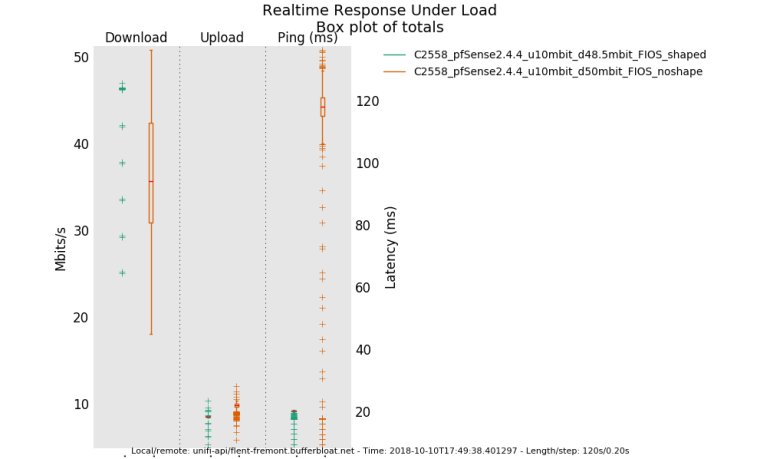
-
@rasool said in Playing with fq_codel in 2.4:
@uptownvagrant
Thank you for confirming that. So that means if CoDel+FQ_CoDel limiter is selected directly (not the child queue) in floating rules, the traffic will be controlled by CoDel algorithm.Yes, that would be my assumption too, but then I tested and the output is almost identical to DropTail. It appears that the AQM selection for the limiter is not being obeyed in pfSense. This does not appear to be a WebUI issue as the ipfw limiter.rules file looks to show the AQM and scheduler selected properly.
I can say, to avoid any possible problems when configuring fq_codel using current WebUI, the limiter child queue method should be used (with DropTail selected for both the limiter and child queue).
Yes, this is what I have found but again, it does not appear to be an issue with the WebUI. IMO, having the child queue is a functional requirement at this time and I'm not sure if it's related to the pf patch that pfSense is using to direct traffic to dummynet pipes and queues. Maybe kernel?
Now we have to figure out which part(s) causes performing issues. I think we have to compare the results (pps, CPU %utilisation, throughput) when using limiter with DropTail+FIFO (limiter only) and DropTail+FQ_CoDel (using child queue method).
We certainly can do that but there appears to be multiple issues with limiters and pfSense that we've identified in this thread and I'm wondering if the performance limitations may be a result. I've tested with FreeBSD and ipfw dummynet limiters and the performance issues did not surface.
-
Here are the two issues I think we've identified. If others can respond that they are able to reproduce the issues I will file bug reports for 2.4.4.
Issue 1:
Using limiters on an interface with outgoing NAT enabled causes all ICMP ping traffic to drop when the limiter is loaded with flows. I can reproduce this issue with the following configuration.- limiters created (any scheduler). One limiter for out and one limiter for in.
- create a single child queue for the out limiter and one for the in limiter.
- floating match IPv4 any rule on WAN Out using the out limiter child queue for in and in limiter child queue for out.
- floating match IPV4 any rule on WAN In using the in limiter child queue for in and out limiter child queue for out.
- load the limiter with traffic (most recently I've been using a netserver v2.6.0 on the WAN side and a Flent client on the LAN side running RRUL test)
- start a constant ping from the client to the server during the RRUL test
Both the flent.gz output and the constant ping will show a high rate of ICMP packets getting dropped. If NAT is disable you will not see ICMP drops.
Issue 2:
If a limiter pipe, not queue, is used in a floating match rule, FQ-CoDel will not be used even if selected and verified in /tmp/rules.limiter. I can reproduce this issue with the following configuration.- limiters created (FQ-CoDel scheduler with default settings). One 90Mbps limiter for out and one 90Mbps limiter for in.
- floating match IPv4 any rule on WAN Out using the out limiter for in and in limiter for out.
- floating match IPV4 any rule on WAN In using the in limiter for in and out limiter for out.
- using a netserver v2.6.0 on the WAN side and a Flent client on the LAN side, run the RRUL test on the client and inspect the output flent.gz. Server and client have GigE connectivity to pfSense.
You will notice that latency under load reflects a default 50 slot DropTail queue size and not what is expected from the default FQ-CoDel configuration. Adding a DropTail child queue to each limiter, updating the floating rules to use the queues instead of pipes, and rerunning the Flent RRUL test will show expected latency under load when FQ-CoDel with the default settings are in play.
-
@uptownvagrant said in Playing with fq_codel in 2.4:
Issue 1:
Using limiters on an interface with outgoing NAT enabled causes all ICMP ping traffic to drop when the limiter is loaded with flows.I can confirm this is happening. Using Rasool's steps outlined in post "@rasool said in Playing with fq_codel in 2.4"
I set a continuous ping going to 1.1.1.1, then start up speedtest.net and perform a speed test. All pings while the connection is being tested will time out. Disable the limiters and test again, ping doesn't drop packets.